
미국 텍사스공대 연구팀이 문장 속 ‘희망’이라는 감정을 찾아내는 AI 실험을 했다. 놀랍게도 5년 전에 나온 구형 AI가 최신 AI들을 제치고 가장 뛰어난 성능을 보였다. 더 복잡하고 새로운 AI가 반드시 더 좋은 결과를 내는 것은 아니라는 사실이 증명된 셈이다.
구형 BERT, 정확도 84%로 최신 AI들 제쳐
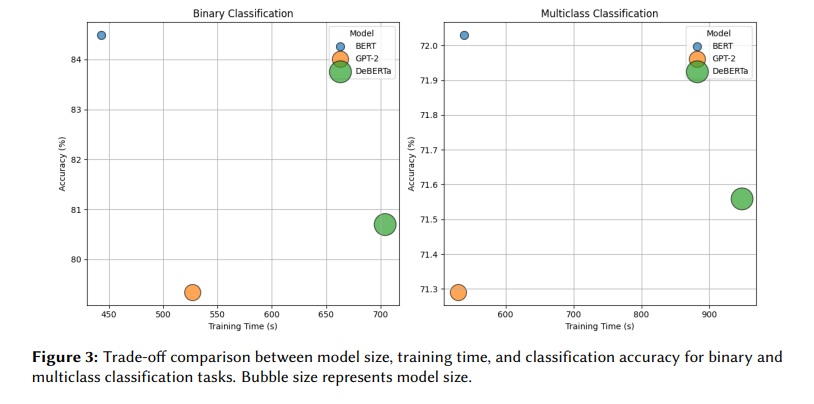
해당 연구 논문에 따르면, 연구팀은 세 가지 AI를 비교했다. 2018년에 나온 BERT(버트)와 2019년 GPT-2(지피티-2), 그리고 2021년 DeBERTa(디버타)다. 이들에게 문장을 보여주고 ‘희망이 담긴 문장인지 아닌지’ 구분하는 실험을 시켰다. 결과는 의외였다. 가장 오래된 BERT가 84.49%의 정확도로 1위를 차지했다. DeBERTa는 80.70%, GPT-2는 79.34%를 기록했다. 연구팀은 약 5,200개의 문장으로 AI를 훈련시키고, 1,900개의 문장으로 테스트했다.
더 복잡한 실험도 진행했다. 희망을 다섯 가지로 세분화해서 분류하는 것이다. ‘희망 없음’, ‘막연한 희망’, ‘현실적 희망’, ‘비현실적 희망’, ‘비꼬는 말’ 등이다. 여기서도 BERT가 72.03%로 가장 높은 정확도를 보였다. DeBERTa는 71.56%, GPT-2는 71.29%였다.
속도는 2배 빠른데 정확도는 더 높아
더 놀라운 건 처리 속도다. 간단한 실험에서 BERT는 학습에 443초가 걸렸다. GPT-2는 527초, DeBERTa는 704초였다. 복잡한 실험에서는 BERT와 GPT-2가 각각 539초와 530초로 비슷했지만, DeBERTa는 948초나 걸렸다. BERT보다 거의 두 배 느린 셈이다.
결국 DeBERTa는 학습 시간이 59% 더 오래 걸렸지만 성능은 오히려 떨어졌다. 연구팀은 BERT가 정확도와 속도 면에서 가장 균형 잡힌 선택이라고 결론 내렸다. 특히 컴퓨터 성능이 제한된 환경에서 실제로 사용할 때 이런 차이가 중요하다고 강조했다.
GPT-2, 비꼬는 말 찾기에선 압도적 1위
각 AI마다 잘하고 못하는 게 달랐다. GPT-2는 전체 점수는 낮았지만, ‘비꼬는 말’ 찾기에서는 92.46%로 압도적이었다. BERT는 77.38%, DeBERTa는 82.14%에 그쳤다. GPT-2가 더 많은 자료로 학습해서 미묘한 말투를 잘 알아채는 것으로 보인다. 반대로 모든 AI가 어려워한 부분도 있다. ‘비현실적 희망’을 찾는 건 세 AI 모두 힘들어했다. BERT는 67.25%, GPT-2는 46.78%, DeBERTa는 50.29%만 맞췄다. 이 유형은 다른 희망 표현과 구분하기가 애매해서 자주 헷갈렸다.
GPT-2는 문장을 ‘희망 있음’으로 판단하는 경향이 강했다. 민감도는 93.77%로 높았지만, 특이도는 66.40%로 낮았다. 반면 BERT는 민감도 84.20%, 특이도 84.75%로 균형이 잘 잡혀 있었다.
문장 손질 방법에 따라 결과 달라져
연구팀은 흥미로운 사실을 하나 더 발견했다. 처음 실험에서 BERT는 복잡한 분류에서 74.87%의 정확도를 보였다. 그런데 나중 실험에서는 모든 AI가 71~72% 정도만 맞췄다. 원인은 문장을 정리하는 방식 차이였다. 처음에는 문장을 거의 손대지 않고 그대로 학습시켰다. 나중에는 대소문자를 통일하고, 인터넷 주소를 지우고, 해시태그와 특수문자를 모두 제거했다.
과도하게 정리한 게 오히려 독이 됐다. 대문자 강조, 느낌표 사용, 해시태그 같은 요소들이 희망의 미묘한 뉘앙스를 표현하는 데 중요한 역할을 했던 것이다. 이를 다 지우니까 AI가 제대로 파악하지 못했다. 연구팀은 때로는 최소한의 손질이 더 나은 결과를 낸다는 다른 연구 결과와도 일치한다고 설명했다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 희망 감지 AI는 어디에 쓰나요?
A: 정신 건강 상담, 소셜미디어 분석, 재난 상황 대응 등에 활용될 수 있습니다. 예를 들어 상담 기록을 분석해서 환자의 심리 상태 변화를 추적하거나, 재난 상황에서 SNS 글을 분석해 대중의 감정 상태를 파악하는 데 쓰일 수 있습니다.
Q2. BERT가 최신 AI보다 더 정확한 이유는 뭔가요?
A: BERT는 문장의 앞뒤를 모두 살펴보면서 단어의 의미를 파악합니다. 반면 GPT-2는 앞쪽 단어만 보고 판단해서 전체 맥락 파악에 한계가 있었습니다. 희망이라는 감정은 문장 전체의 흐름을 봐야 제대로 이해할 수 있어서, BERT 방식이 더 유리했던 것입니다.
Q3. 희망을 다섯 가지로 나눈 기준은 뭔가요?
A: ‘희망 없음'(희망이 없는 문장), ‘막연한 희망'(구체적이지 않은 일반적인 낙관), ‘현실적 희망'(근거 있는 기대), ‘비현실적 희망'(실현 가능성이 거의 없는 기대), ‘비꼬는 말'(겉으로는 희망적이지만 실제로는 반대 의미)입니다. 이렇게 세분화하면 문장 속 희망의 성격을 더 정확히 이해할 수 있습니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: Classification of Hope in Textual Data using Transformer-Based Models
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





