
상하이 자오퉁 대학교와 중국 콰이쇼우 테크놀로지(Kuaishou Technology) 연구진이 이미지와 비디오의 생성부터 편집까지 하나의 모델로 처리하는 ‘비노(VINO)’를 공개했다. 지금까지는 사진을 만들 때, 영상을 만들 때, 편집할 때 각각 다른 AI 프로그램을 써야 했지만, 비노는 이 모든 작업을 하나로 처리한다.
여러 종류의 명령을 한 번에 이해하는 기술
비노의 핵심 기술은 글, 사진, 영상 등 서로 다른 형태의 자료를 동시에 이해하고 처리하는 능력이다. 연구팀은 이를 위해 두 가지 핵심 부품을 조합했다. 첫 번째는 이미지와 텍스트를 함께 이해하는 비전-언어 모델(VLM)이고, 두 번째는 실제로 이미지나 영상을 만들어내는 멀티모달 확산 트랜스포머(MMDiT)이다.
비전-언어 모델이 사용자가 입력한 글, 참고용 사진, 영상 등을 분석해서 통합된 정보로 변환하면, 확산 트랜스포머가 이 정보를 바탕으로 새로운 이미지나 영상을 만들어낸다. 이 설계 덕분에 작업별로 특화된 모듈 없이도 단일 시스템이 다양한 입력을 처리할 수 있게 됐다.
특히 연구팀은 학습 가능한 쿼리 토큰(learnable query tokens) 이라는 기술을 추가했다. 이는 사용자의 추상적인 요구사항과 실제 이미지 제작 사이를 연결하는 역할을 한다. 따라서 실험 결과 이 기술을 적용하자 AI가 훨씬 안정적으로 학습했고, 결과물의 품질도 크게 향상됐다.
원본 사진·영상의 특징을 정확하게 유지하는 비결
비노는 원본 이미지나 영상의 특징을 잘 보존하기 위해 특별한 장치를 마련했다. 단순히 이미지를 분석한 정보만 사용하는 게 아니라, 원본의 세밀한 시각 정보도 함께 활용한다. 이때 중요한 것이 특수 토큰 경계 메커니즘(token-boundary mechanis)이다. 각 참고 자료(사진이나 영상)마다 시작과 끝을 표시하는 특별한 표지를 붙이는 방식이다. 이 표지는 의미 정보와 시각 정보 양쪽에 동일하게 적용된다. 덕분에 AI는 같은 원본에서 나온 여러 종류의 정보를 하나로 묶어서 인식할 수 있다.
연구팀의 실험에서 이 표지를 제거하자 AI가 정지된 사진을 움직이는 영상의 일부로 착각하는 오류가 발생했다. 특히 만들어진 영상의 첫 장면이 심하게 일그러지는 문제가 나타났다. 이 메커니즘은 복잡한 여러 자료를 다룰 때 인물이나 사물의 특징이 뒤섞이는 것을 막는 핵심 역할을 한다.
3단계 학습으로 만능 AI로 진화
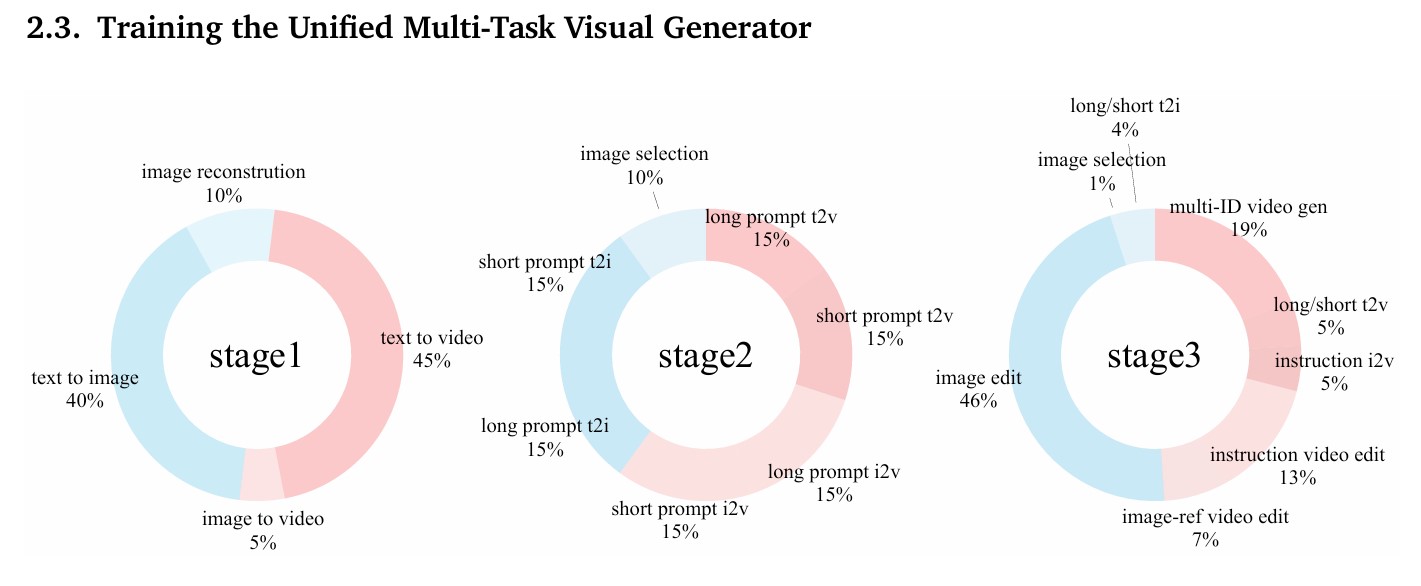
비노 연구팀에 따르면, 비노를 학습시키는 데 가장 어려웠던 점은 서로 다른 형태의 명령을 처리하는 것이었다. 이미지나 영상을 새로 만들 때는 길고 자세한 설명이 필요하지만, 편집할 때는 “배경을 바꿔줘”처럼 짧고 간단한 지시를 사용한다. 연구팀은 이 문제를 3단계 학습 전략으로 해결했다.
1단계에서는 긴 설명과 함께 이미지·영상 자료를 학습시켰다. 이 과정에서 AI의 이해 능력과 제작 능력을 서로 맞췄다. 2단계에서는 긴 설명과 짧은 설명을 섞어서 학습시켜 AI가 짧은 명령도 이해하고, 부족한 정보를 스스로 채울 수 있게 했다. 3단계에서는 모든 종류의 작업을 함께 학습시켰다.
학습 데이터 비율을 보면 단계별로 점차 편집 작업의 비중을 늘려갔다. 1단계에서는 텍스트로 이미지 만들기(40%), 텍스트로 영상 만들기(45%) 등 기본 생성 작업 위주였다. 3단계에서는 이미지 편집(46%), 여러 인물이 나오는 영상 생성(19%), 지시에 따른 영상 편집(13%) 등 복잡한 작업의 비중이 크게 늘었다.
기존 AI들과 비교해도 뛰어난 성능 입증
연구팀은 여러 성능 평가 도구로 비노의 능력을 검증했다. 이미지 생성 능력을 평가하는 테스트에서 비노는 추가 기술을 적용했을 때 상위권 이미지 전문 AI들과 비슷한 수준을 보였다. 영상 품질 평가에서는 기반이 된 훈위완 비디오(HunyuanVideo) 와 거의 같은 성능을 유지하면서도, 명령의 의미를 이해하는 능력에서는 오히려 더 뛰어난 결과를 냈다.
참고 자료를 바탕으로 영상을 만드는 능력 평가에서 비노는 일부 유료 상용 AI들을 포함한 여러 경쟁 모델들보다 높은 점수를 받았다. 특히 원본 인물의 얼굴 특징을 그대로 유지하는 능력에서 우수한 평가를 받았다.
편집 능력은 더욱 뛰어났다. 이미지 편집 평가에서 비노는 5점 만점에 평균 4.18점을 기록하며 최상위권 성능을 보였다. 특히 불필요한 요소 제거, 여러 요소 조합, 동작 관련 편집에서 4.3~4.5점대의 높은 점수를 받았다. 놀라운 점은 편집 학습을 시작한 지 얼마 안 됐을 때도 대부분의 공개 AI를 넘어섰다는 것이다.
영상 편집에서는 경쟁 AI인 ‘베이스-디토’와 비교 평가를 진행했다. 대상 유지, 배경 일관성, 움직임 부드러움 등 모든 항목에서 90%대 중후반의 높은 점수를 기록했다. 25명을 대상으로 한 사용자 평가에서도 명령 이해도와 영상 품질 모두 5점 만점에 4점을 받아, 2점대에 머문 베이스-디토를 크게 앞질렀다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. 비노가 기존 AI와 어떻게 다른가요?
A. 기존에는 사진 만들기, 영상 만들기, 편집하기를 각각 다른 AI 프로그램으로 해야 했습니다. 비노는 이 모든 작업을 하나의 프로그램에서 처리합니다. 여러 개의 앱을 설치하고 배울 필요 없이 하나만 사용하면 됩니다.
Q. 일반 사용자도 비노를 쓸 수 있나요?
A. 현재 비노는 연구 단계의 기술입니다. 논문과 프로젝트 페이지가 공개되어 있으며, 깃허브에서 코드를 확인할 수 있습니다. 실제 서비스로 출시되려면 더 기다려야 할 것으로 보입니다.
Q. 비노의 한계는 무엇인가요?
A. 비노는 이미지나 영상에 글자를 넣는 기능이 약합니다. 또한 참고 자료로 영상과 여러 장의 사진을 동시에 많이 넣으면 처리 속도가 느려집니다. 연구팀은 향후 더 효율적인 AI 구조를 탐색할 계획입니다.
기사에 인용된 리포트 원문은 arXiv에서 확인가능하다.
논문명: VInO: A Unified Visual Generator with Interleaved OmniModal Context
이미지 출처: VInO: A Unified Visual Generator with Interleaved OmniModal Context
해당 기사는 클로드를 활용해 작성되었습니다.





