
AI 기업 앤트로픽이 인공지능 모델의 보안을 대폭 강화하면서도 운영 비용을 40분의 1 수준으로 줄인 새로운 기술을 공개했다. 이번 기술은 AI가 위험한 정보를 제공하지 못하도록 막으면서도, 일반 사용자의 정상적인 질문을 거부하는 비율을 0.05%까지 낮췄다는 점에서 주목받고 있다.
기존 보안 시스템의 허점 발견… “조각내서 숨기고, 암호처럼 감추고”
해당 연구 논문에 따르면, 앤트로픽 연구팀은 기존 보안 시스템에서 두 가지 심각한 허점을 발견했다. 첫 번째는 ‘재구성 공격’이다. 이는 위험한 질문을 여러 조각으로 나눠서 무해한 내용 사이사이에 숨긴 뒤, 나중에 다시 조립하는 방식이다. 마치 퍼즐 조각을 흩어놓았다가 나중에 맞추는 것과 비슷하다. 예를 들어 위험한 질문을 컴퓨터 코드의 여러 함수 안에 분산시켜 넣으면, 입력 단계에서 걸러지지 않았다.
두 번째는 ‘출력 위장 공격’이다. 공격자들은 AI가 답변할 때 위험한 화학물질 이름을 무해한 별명으로 바꾸거나, 수수께끼나 은유 같은 표현을 사용하도록 유도했다. 예를 들어 특정 화학물질을 직접 언급하지 않고 “겨울의 숨결”이나 “바다의 선물” 같은 표현으로 돌려 말하게 만드는 식이다.
이런 공격 방식들은 AI의 성능을 떨어뜨리긴 하지만, 그 정도는 매우 다양했다. 한 테스트에서 AI의 정확도가 74.2%에서 32.3%로 급격히 떨어졌지만, 다른 방식에서는 49%까지만 감소했다. 연구팀은 이런 차이 때문에 공격자들이 AI 성능을 덜 해치면서도 보안을 뚫는 새로운 방법을 계속 개발할 수 있다고 우려했다.
질문과 답변을 함께 분석하는 새 방식… 보안성 2배 이상 향상
이런 문제를 해결하기 위해 연구팀은 ‘교환 분류기’라는 새로운 방식을 개발했다. 기존에는 사용자의 질문과 AI의 답변을 각각 따로 검사했다면, 새 방식은 질문과 답변을 함께 보면서 실시간으로 판단한다. AI가 답변을 만들어내는 동안 계속해서 전체 맥락을 확인하는 것이다.
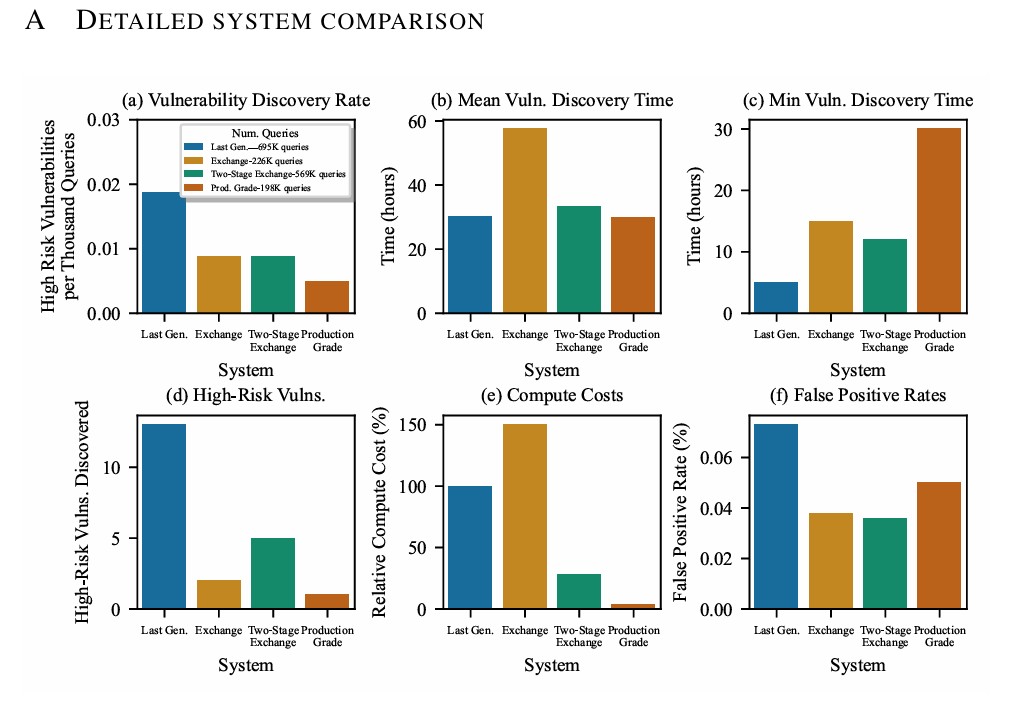
실제 해킹 테스트 결과, 새로운 방식의 보안 성능이 크게 향상됐다. 기존 시스템은 69만 5천 건의 해킹 시도에서 13건의 심각한 보안 취약점이 발견됐다. 반면 새 시스템은 22만 6천 건에서 2건만 발견됐다. 이는 해킹 시도당 취약점 발견 건수가 2.2배로 감소한 것이다. 또한 8개의 모든 위험 질문에 답변할 수 있는 강력한 해킹 기법을 찾아내는 데 걸린 시간도 평균 27시간에서 100시간으로 크게 늘어났다. 이는 해커들이 보안을 뚫기가 그만큼 어려워졌다는 의미다.
2단계 검사 시스템으로 비용 5배 이상 절감
하지만 새로운 방식은 처리 비용이 50% 증가하는 문제가 있었다. 이를 해결하기 위해 연구팀은 ‘2단계 검사 시스템’을 만들었다. 첫 번째 단계에서는 가볍고 빠른 검사기가 모든 대화를 빠르게 확인한다. 여기서 의심스러운 것만 골라내 두 번째 단계의 더 정밀하지만 비용이 많이 드는 검사기로 보내는 방식이다.
이 방식의 핵심은 첫 번째 단계에서 의심스러운 대화를 발견해도 바로 차단하지 않고 두 번째 검사로 넘긴다는 점이다. 덕분에 첫 번째 검사기가 조금 예민하게 반응해도 괜찮다. 일반 사용자의 정상적인 질문이 첫 번째 단계에서 걸려도, 두 번째 단계에서 다시 확인해 통과시킬 수 있기 때문이다.
56만 9천 건의 해킹 시도를 대상으로 한 테스트에서 이 시스템은 5건의 심각한 취약점을 발견했다. 보안 성능은 이전과 비슷하면서도 처리 비용은 5.4배 줄어들었다. 전체 대화 중 약 10%만 두 번째 단계로 넘어갔으며, 첫 번째 단계가 전체 비용의 약 77%를 차지했다.
실제 서비스 환경에서 오작동률 0.05%… 1,700시간 해킹 테스트 통과
최종 완성된 시스템은 초경량 도구를 1단계로, 초경량 도구와 외부 검사 도구의 조합을 2단계로 사용한다. AI가 답변을 만드는 동안 초경량 도구가 계속 감시하다가 위험 점수가 기준을 넘으면 2단계 검사를 시작한다. 2단계에서는 두 도구의 판단을 각각 55%와 45%의 비율로 합쳐서 최종 결정을 내린다. 이 시스템은 앤트로픽의 클로드 소넷 4.5 모델을 보호하는 데 사용되고 있다.
2025년 12월 1일부터 2026년 1월 1일까지 한 달간 실제 서비스 환경에서 테스트한 결과, 정상적인 질문을 잘못 차단하는 비율이 0.05%에 불과했다. 이는 기존 연구에서 보고된 0.38%보다 크게 낮은 수치다. 1단계 초경량 도구는 전체 대화의 약 5.5%만 2단계로 보냈다. 처리 비용은 2단계 시스템에 비해 8배, 단일 교환 검사 방식에 비해 40배 줄어들었다.
보안성 테스트를 위해 약 1,736시간 동안 약 19만 8천 건의 해킹 시도가 이루어졌다. 그 결과 심각한 취약점은 단 1건만 발견됐다. 이는 이번 연구에서 평가한 모든 시스템 중 가장 낮은 수치다. 해커가 이 취약점을 찾는 데 걸린 시간도 30시간으로, 다른 시스템들보다 길었다. 가장 중요한 것은 8개의 모든 위험 질문에 상세하게 답변할 수 있는 강력한 해킹 기법이 단 하나도 발견되지 않았다는 점이다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 헌법적 분류기는 무엇을 하는 기술인가요?
A1. AI에게 위험한 질문(예: 무기 제조법)을 했을 때 답변을 차단하는 보안 시스템입니다. 사용자의 질문과 AI의 답변을 실시간으로 분석해 화학·생물·핵 무기 같은 위험한 정보 제공을 막습니다.
Q2. 새 시스템이 기존보다 훨씬 저렴한 이유는 무엇인가요?
A2. AI가 답변을 만들 때 이미 계산한 정보를 재활용하는 초경량 검사 도구를 사용하기 때문입니다. 추가 계산이 거의 필요 없어 기존 방식보다 40배 저렴하면서도 보안 성능은 더 우수합니다.
Q3. 이 기술이 막을 수 있는 해킹 방식은 어떤 것들인가요?
A3. 위험한 질문을 조각내서 여러 곳에 숨기는 방식과, AI가 위험한 내용을 암호나 은유로 표현하도록 유도하는 방식을 막을 수 있습니다. 질문과 답변을 함께 보면서 판단하기 때문에 맥락을 고려한 탐지가 가능합니다.
해당 기사에 인용된 리포트 원문은 앤트로픽 웹사이트에서 확인 가능하다.
리포트 명: Next-generation Constitutional Classifiers: More efficient protection against universal jailbreaks
이미지 출처: 앤트로픽
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





