
엔비디아가 AI 영상 생성 속도를 획기적으로 개선하는 새로운 기술 ‘TMD’를 공개했다. 해당 연구 논문에 따르면, 이 기술은 기존에 수십 번의 단계가 필요했던 영상 생성 과정을 단 몇 번으로 줄이면서도 높은 화질을 유지한다. 이번 기술은 실시간 영상 제작, 영상 편집, 게임 속 영상 생성 같은 분야에서 AI를 실제로 활용할 수 있게 만든 혁신이라는 평가를 받고 있다.
50번 계산하던 것을 1.38번으로… 영상 생성이 36배 빠르게
TMD 기술의 핵심은 복잡한 AI 영상 생성 과정을 간단하게 압축하는 것이다. 엔비디아 연구팀은 Wan2.1이라는 대형 AI 모델을 실험한 결과, 기존에 50단계가 필요했던 영상 생성을 단 1.38단계로 줄이면서도 성능 평가에서 84.24점이라는 높은 점수를 기록했다. 이는 기존 최고 기술인 rCM의 83.02점보다 1.22점이나 높은 성과다.
연구팀이 사용한 방법은 AI 모델을 두 부분으로 나누는 것이다.
첫 번째 부분은 ‘메인 엔진’으로, 영상의 전체적인 의미와 구조를 파악한다.
두 번째 부분은 ‘디테일 처리기’로, 메인 엔진이 만든 기본 정보를 받아서 여러 번 다듬으며 세밀한 부분을 완성한다. 이렇게 역할을 나누면 메인 엔진은 한 번만 작동하고, 가벼운 디테일 처리기가 반복 작업을 하기 때문에 전체 계산량이 크게 줄어든다. 디테일 처리기는 여러 번 반복하면서 화질을 높이는데, 반복 횟수를 조절하면 속도와 품질의 균형을 자유롭게 맞출 수 있다는 장점이 있다.
빠르면서도 선명하게… 속도와 화질 동시 개선 비결은 ‘2단계 학습’
TMD는 두 단계로 나눠 학습하여 최고의 성능을 만들어낸다.
첫 번째 단계는 ‘디테일 처리기 훈련’이다. 기존 MeanFlow라는 기술을 개선한 방법을 사용해서, 디테일 처리기가 반복해서 영상을 다듬을 수 있는 능력을 갖추도록 만든다. 이 단계에서 디테일 처리기는 원본 AI 모델의 결과물과 비슷한 방식으로 작동하도록 설계된다.
두 번째 단계는 ‘전체 시스템 최적화’다. 여기서는 영상 생성에 특화된 DMD2-v라는 방법을 사용한다. DMD2-v는 기존 기술을 영상에 맞게 개선한 것으로, 세 가지 핵심 요소가 있다. 첫째, 진짜와 가짜 영상을 구별하는 판별 시스템에 3차원 처리 기술을 적용해 시간과 공간 정보를 함께 분석한다. 둘째, 초기 학습은 한 번에 영상을 생성하는 경우에만 사용해서, 여러 단계로 나눠 생성할 때 발생하는 거친 오류를 방지한다. 셋째, 시간 조정 기법을 써서 성능을 높이고 생성 실패를 막는다. 학습 과정에서 디테일 처리기의 반복 작업을 풀어서 실제 사용할 때와 똑같은 방식으로 훈련하기 때문에, 학습한 대로 실제로도 잘 작동한다.
품질 평가 1위, 사용자 만족도 1위… 모든 지표에서 압승
연구팀은 Wan2.1의 1.3B(소형)과 14B(대형) 모델 두 가지로 광범위한 실험을 진행했다. 소형 모델 실험에서 2단계 생성 방식을 쓴 TMD는 2.33번의 계산으로 84.68점을 기록하며, 4번 계산이 필요한 가장 강력한 기존 방법 rCM의 84.43점을 넘어섰다. 1단계 생성에서도 TMD는 1.17번의 계산으로 83.80점을 받아 모든 1단계 생성 방법을 이겼다.
대형 모델 실험에서는 더 놀라운 결과가 나왔다. 1단계 생성에서 TMD는 1.38번의 계산으로 84.24점을 달성했는데, 이는 1단계 rCM의 83.02점보다 1.22점이나 높으면서도 계산량 증가는 최소였다. 특히 초기 학습 과정 없이도 이 성과를 냈다는 점에서 TMD의 효율성이 입증됐다.
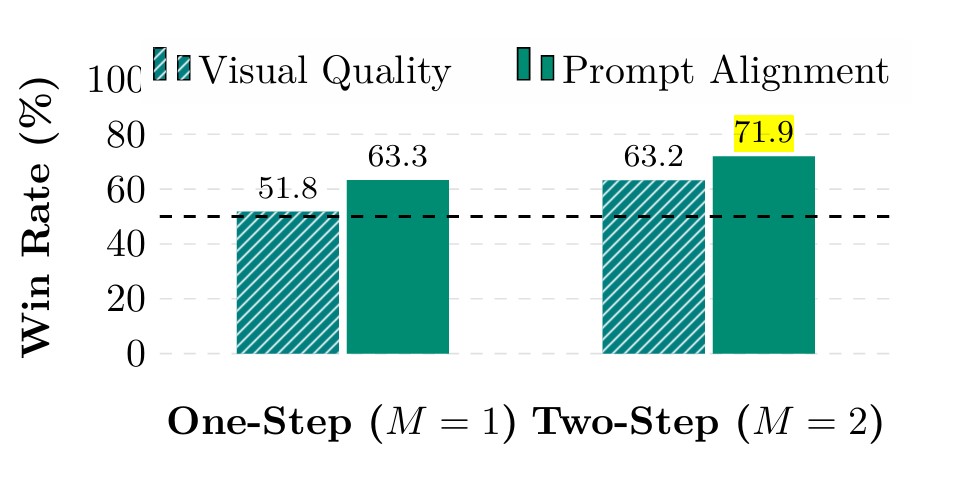
연구팀은 실제 사용자들이 어떻게 느끼는지 알아보기 위해 60개의 어려운 주문으로 영상을 만들어 테스트했다. 각 주문마다 5개씩 다른 영상을 만들고, 평가자들에게 화질과 주문 일치도를 비교하게 했다. 결과는 1단계와 2단계 생성 모두에서 사용자들이 기존 방법보다 TMD를 훨씬 선호했다. 특히 주문한 내용과 얼마나 잘 맞는지에서 큰 차이가 났다. 1단계 생성에서 화질은 51.8%, 주문 일치도는 63.3%가 TMD를 선택했고, 2단계 생성에서는 각각 63.2%와 71.9%가 TMD를 골랐다.
반복 처리가 고품질의 핵심이다
연구팀은 여러 가지 실험을 통해 TMD의 각 부분이 최종 성능에 어떤 영향을 주는지 분석했다. 특히 디테일 처리기의 반복 횟수를 바꿔가며 실험한 결과가 인상적이다. 반복을 1번만 하는 것과 4번 하는 것을 비교했더니, 1번만 반복한 영상은 오류가 많고 흐릿한 반면, 4번 반복한 영상은 훨씬 선명하고 깨끗했다. 이는 고품질 영상을 만들기 위해서는 디테일 처리기가 여러 번 반복해서 다듬는 과정이 꼭 필요하다는 것을 보여준다.
반복 횟수와 디테일 처리기의 크기를 다양하게 바꿔가며 속도와 품질의 균형을 분석했다. 그 결과 계산량이 늘어날수록 점수가 올라가는 경향을 확인했다. 이는 TMD가 생성 속도와 영상 품질 사이에서 세밀하게 조절할 수 있는 유연성을 제공한다는 의미다. 또한 첫 번째 학습 방법을 비교한 실험에서 개선된 MeanFlow 방식이 기본 방식보다 더 좋은 결과를 냈고, 이것이 두 번째 학습 단계의 좋은 출발점이 됨을 확인했다.

실시간 영상 편집·콘텐츠 제작 가능
TMD 기술은 대형 AI 영상 모델의 느린 속도 문제를 해결하기 위해 만들어진 새로운 방법이다. 전체 의미를 파악하는 메인 엔진과 세부 사항을 다듬는 가벼운 디테일 처리기로 나누는 설계와, 2단계 학습 전략이 합쳐져서 최고의 성능을 만들어낸다.
Wan2.1 모델 실험은 TMD가 속도와 품질 사이에서 자유롭게 조절할 수 있음을 증명했다. 특히 비슷한 계산 비용에서 기존 기술들을 모두 넘어서며 뛰어난 화질과 주문 일치도를 달성했다. 연구팀은 앞으로 두 학습 단계를 하나로 합치고, 다른 속도 향상 기술들과 TMD를 결합해서 영상 생성을 더욱 빠르게 만들 계획이다.
이번 연구는 실시간 영상 제작의 새로운 가능성을 보여준다. 기존에는 수백 번의 계산이 필요했던 고품질 영상 생성이 단 몇 번으로 가능해지면서, 즉각적인 콘텐츠 제작, 실시간 영상 편집, 게임과 가상현실에서의 즉석 영상 생성 등 다양한 분야에서 혁신을 가져올 것으로 기대된다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. TMD 기술이 뭐고 기존 AI 영상 제작과 뭐가 다른가요?
A. TMD는 대형 AI 영상 모델을 빠른 생성기로 압축하는 기술입니다. 기존 AI는 좋은 영상을 만들려면 복잡한 계산을 해야 했지만, TMD는 이걸 1~4번으로 줄이면서도 비슷하거나 더 나은 품질을 만듭니다. 덕분에 거의 실시간으로 영상을 만들 수 있게 됐습니다.
Q2. TMD를 쓰면 영상 만드는 속도가 얼마나 빨라지나요?
A. 엔비디아 실험 결과, Wan2.1 대형 모델에 TMD를 적용하면 기존 50단계에서 1.38단계로 줄어들어 약 36배 빠릅니다. 소형 모델도 2.33단계로 약 21배 빨라졌습니다. 품질은 그대로 유지하면서 이런 속도를 낸 것이라 실제로 쓸 수 있는 수준입니다.
Q3. TMD 기술은 어디에 쓸 수 있나요?
A. 실시간 영상 제작이 필요한 다양한 곳에 쓸 수 있습니다. 예를 들어 유튜버나 크리에이터를 위한 즉석 영상 편집 도구, 게임이나 메타버스에서 실시간으로 환경 만들기, AI 로봇 훈련용 가상 세계 만들기, 영화나 광고 제작에서 빠른 미리보기 만들기 등에 활용될 수 있습니다.
해당 기사에 인용된 논문 원문은 arXiv에서 확인 가능하다.
논문명: Transition Matching Distillation for Fast Video Generation
이미지 출처: Transition Matching Distillation for Fast Video Generation
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





