
구글과 시카고대학교(University of Chicago) 연구팀이 발표한 논문에 따르면, AI 모델인 딥시크 R1(DeepSeek-R1)과 QwQ-32B가 문제를 풀 때 단순히 순서대로 생각하는 게 아니라, 마치 여러 사람이 회의하듯 내부에서 다양한 의견을 주고받으며 답을 찾는다는 사실을 밝혀냈다. 이는 AI가 똑똑해진 비결이 단순히 계산을 많이 하는 것이 아니라, 사람들이 모여 토론하며 문제를 해결하는 방식과 비슷한 원리를 사용하기 때문이라는 것을 보여준다.
AI도 스스로에게 질문하고, 반박하고, 다시 생각한다
연구팀은 8,262개의 어려운 문제에 대한 딥시크 R1과 QwQ-32B의 답변 과정을 분석했다. 그 결과 이 AI들은 일반 AI와는 완전히 다른 방식으로 생각한다는 사실을 발견했다. 문제를 풀 때 스스로에게 질문을 던지고 답하며, 다른 방향으로 생각해보고, 자신의 생각에 반대 의견을 제시한 뒤 이를 조정하는 모습을 보였다.
예를 들어 딥시크 R1은 화학 문제를 풀 때 “하지만 여기서는 사이클로헥사-1,3-다이엔이지 벤젠이 아니다”, “또 다른 가능성은 높은 열이 케톤에서 CO를 제거할 수 있다는 것인데, 가능성은 낮다”처럼 스스로 반박하고 대안을 제시했다. 마치 한 명이 아니라 여러 명이 토론하는 것 같은 모습이었다.
연구팀이 AI 분석 도구를 사용해 조사한 결과, 딥시크 R1은 일반 AI인 딥시크 V3(DeepSeek-V3)보다 스스로에게 질문하고 답하는 행동이 34.5% 더 많았고, 다른 관점으로 생각을 전환하는 행동이 21.3%, 의견을 조정하는 행동이 19.1% 더 많이 나타났다. QwQ-32B도 마찬가지로 기본 버전인 Qwen-2.5-32B-IT보다 질문-답변이 45.9%, 관점 전환이 37.8%, 의견 충돌이 29.3%, 조정이 34.4% 더 자주 발생했다. 흥미롭게도 이런 패턴은 AI의 크기와 상관없이 최신 AI에서만 나타났다.
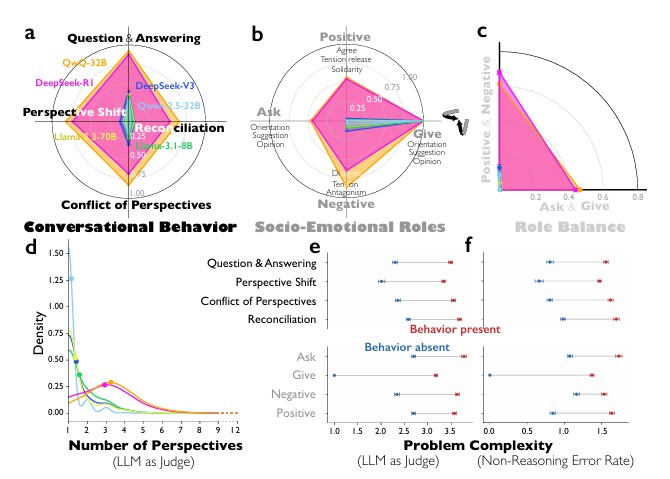
회의실처럼 12가지 역할을 번갈아 수행하는 AI
연구팀은 사람들이 회의할 때 하는 행동을 분류한 ‘베일스 상호작용 분석’이라는 방법을 AI에 적용했다. 이 방법은 회의 중 행동을 12가지로 나누는데, 제안 요청하기, 의견 말하기, 동의하기, 반대하기, 긴장 표현하기 등이 포함된다. 분석 결과 딥시크 R1과 QwQ-32B는 정보를 주는 역할과 요청하는 역할을 동시에 했고, 긍정적 반응과 부정적 반응도 모두 보였다. 반면 일반 AI는 주로 정보만 제공할 뿐 질문하거나 감정적 반응을 보이지 않아 일방적으로 설명만 하는 모습이었다.
연구팀이 역할의 균형도를 측정한 결과, 딥시크 R1은 일반 버전보다 ‘질문하기와 정보주기’ 균형이 22.2%, ‘긍정과 부정 반응’ 균형이 18.9% 더 높았다. 이는 최신 AI가 한쪽으로 치우치지 않고 여러 역할을 골고루 수행한다는 뜻이다. 재밌는 점은 문제가 어려울수록 이런 대화 방식이 더 자주 나타났다는 것이다. 대학원 수준의 과학 문제나 복잡한 수학 문제에서는 활발한 대화 패턴이 나타났지만, 간단한 논리 문제에서는 거의 나타나지 않았다.
성격 다양할수록 문제 잘 푼다… “걱정 많은 AI”와 “모험적인 AI” 공존
연구팀은 AI 분석 도구를 사용해 각 AI의 답변 과정에 나타나는 성격 특징을 분석했다. 사람의 성격을 분류하는 ‘5가지 성격 특성’을 적용한 결과, 딥시크 R1은 일반 AI보다 훨씬 다양한 성격을 가진 목소리들을 사용했다. 특히 외향성(활발함), 친화성(다정함), 신경성(예민함), 개방성(새로운 것에 대한 개방성) 측면에서 차이가 컸다. 특히 친화성과 신경성의 차이가 크게 증가했는데, 이는 AI 안에서 서로 동의하지 않고 도전하는 목소리들이 생성된다는 뜻이다.
흥미롭게도 성실성(꼼꼼함)의 차이는 오히려 적었는데, 이는 AI 안의 여러 목소리가 모두 집중력 있게 문제를 푼다는 의미다. 이런 패턴은 사람 팀 연구 결과와 일치한다. 기존 연구에 따르면 팀원들의 활발함과 예민함이 다양할수록 팀 성과가 좋아지지만, 성실성이 너무 다르면 오히려 성과가 떨어진다고 알려져 있다.
예를 들어 화학 문제를 풀 때는 의심 많고 꼼꼼하게 재검토하는 비판적인 목소리(친화성 낮음, 성실성 높음)와 유사한 사례를 떠올리는 연상 전문가(개방성 높음) 같은 5개의 다른 성격이 확인되었다. 전문성 측면에서도 딥시크 R1은 일반 버전보다 17.9%, QwQ-32B는 기본 버전보다 25.0% 더 다양한 전문 지식을 활용했다. 이론물리학, 논리적 분석, 금융, 창의적 글쓰기 등 여러 분야의 전문성이 한 문제 안에서 함께 나타났다.
‘놀람’ 기능 강화하자 정확도 2배로 껑충… 직접적·간접적 효과 모두 확인
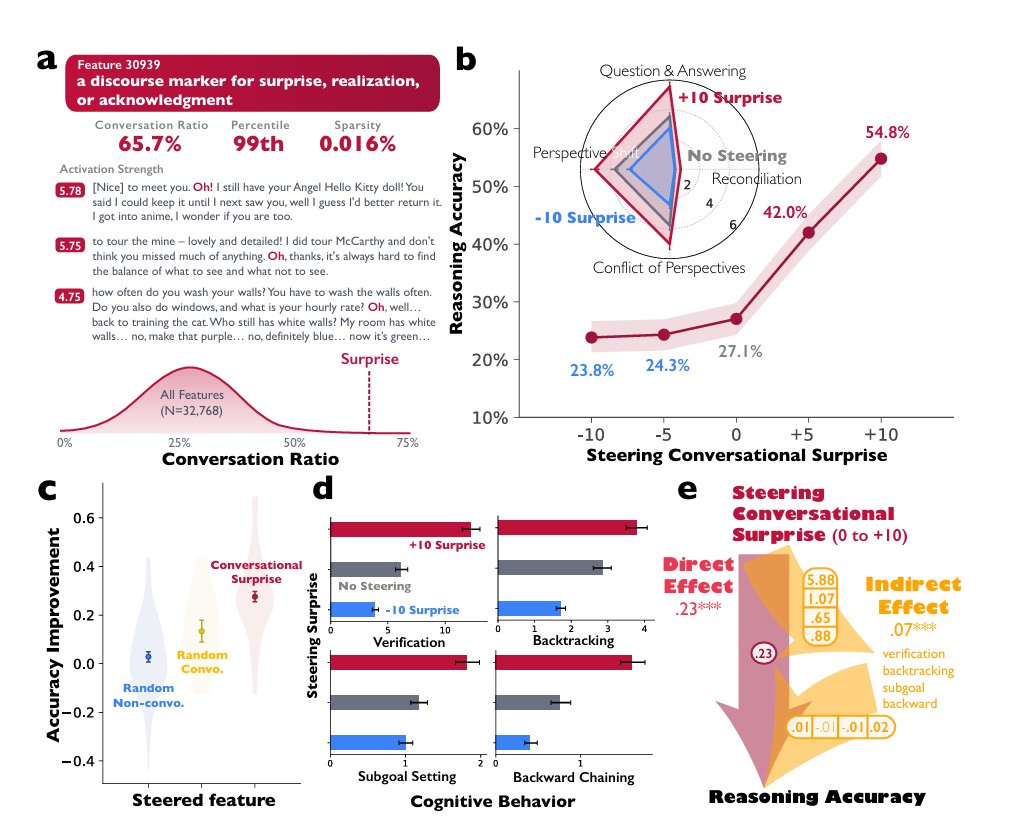
연구팀은 실험을 통해 대화 방식이 AI 성능에 실제로 영향을 미치는지 확인했다. 딥시크 R1 라마 8B(DeepSeek-R1-Llama-8B) 모델 안에 있는 32,768개의 기능 중에서 “놀람, 깨달음, 인정을 표현하는 말”을 담당하는 기능을 찾아냈다. 이 기능은 “오!” 같은 단어에서 작동하며, 대화 상황에서 65.7%의 비율로 나타나 전체 기능 중 상위 1%에 해당했다.
연구팀이 이 기능을 강하게(+10) 작동시킨 결과, 숫자를 조합해 목표값을 만드는 카운트다운 게임에서 정확도가 27.1%에서 54.8%로 2배 증가했다. 반대로 이 기능을 약하게(-10) 만들면 정확도가 23.8%로 떨어졌다. 기능을 강화하면 스스로 질문하기, 관점 바꾸기, 의견 충돌, 조정 등 모든 대화 행동이 동시에 증가했고, 약화시키면 이들이 모두 줄어들었다.
통계 분석 결과, 이 ‘놀람’ 기능 강화는 정확도에 직접적으로 영향을 미쳤을 뿐만 아니라(효과 크기 0.228), 검증하기, 되돌아가기, 단계별 목표 세우기, 역순으로 풀기 같은 문제 풀이 전략을 통해서도 간접적으로 영향을 미쳤다(효과 크기 0.066). 이는 대화 방식이 단순히 말투만 바꾸는 게 아니라 실제로 효과적인 문제 해결 전략을 사용하게 만든다는 뜻이다.
정답만 알려줘도 스스로 ‘토론’ 시작… 보상 없이도 대화 방식 자연 발생
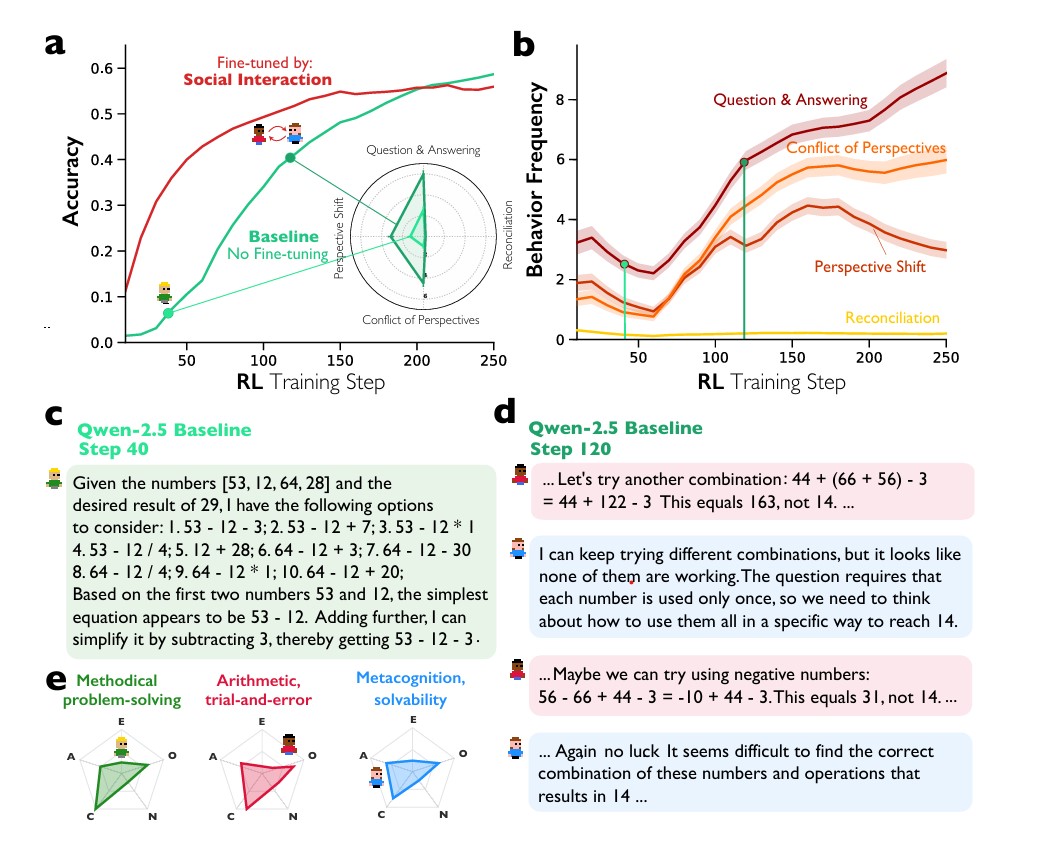
연구팀은 실험을 통해 AI가 정답에 대한 보상만 받아도 대화 방식을 스스로 발전시킨다는 것을 입증했다. Qwen-2.5-3B 기본 모델에게 카운트다운 과제에서 정답만 맞추면 보상을 주며 학습시켰다. 대화 방식이나 문제 풀이 전략에 대한 보상은 전혀 주지 않았지만, 250단계 학습 과정에서 스스로 질문하고 답하는 행동과 의견 충돌이 계속 증가했다. 관점을 바꾸는 행동도 약 160단계까지 증가했다가, AI가 더 적은 전환으로 답을 찾을 수 있게 되면서 감소했다.
특히 흥미로운 점은 학습 초기 40단계에서는 기계적으로 순서대로만 생각하던 AI가 120단계에 이르러 “우리”라는 단어를 사용하며 집단으로 생각하는 두 개의 뚜렷한 목소리가 나타났다는 것이다. 이들은 “다시 안 되네요”, “음수를 써볼까요” 같은 표현으로 불확실성을 표현하고 다른 방법을 시도했다. AI 분석 결과 이 두 목소리는 꼼꼼하고 체계적으로 문제를 푸는 성격과 개방적이고 활발하게 여러 방법을 시도하는 성격으로 구분되었다.
대화식 학습이 단계식 학습보다 2배 빠르다… 다른 문제에도 효과
연구팀은 세 가지 방식으로 AI를 학습시켜 비교했다. 기본 학습, 대화식 추가 학습 후 기본 학습, 단계식 추가 학습 후 기본 학습이다. 대화식 추가 학습 데이터는 2~4개의 다른 성격을 가진 목소리가 8,262개 문제를 함께 풀면서 서로의 생각을 보완하고, 질문하고, 수정하는 대화를 만들었다. 단계식 추가 학습 데이터는 같은 문제를 한 명이 순서대로 푸는 방식으로 만들었다.
실험 결과 대화식으로 추가 학습한 AI가 단계식보다 훨씬 빠르게 정확도를 높였다. Qwen-2.5-3B의 경우 40단계에서 대화식 AI는 약 38% 정확도에 도달한 반면 단계식 AI는 28%에 머물렀다. 이 패턴은 Llama-3.2-3B에서도 똑같이 나타났는데, 70단계에서 대화식 AI는 11% 정확도를 달성했지만 단계식 AI는 5%에 불과했다. 특히 Llama-3.2-3B에서는 학습이 진행될수록 차이가 더 벌어져, 150단계에서 대화식 AI는 40% 정확도를 달성했지만 단계식 AI는 약 18%에 정체되었다.
중요한 점은 두 방식 모두 똑같은 문제와 정답으로 학습했는데도 대화식 AI가 일관되게 더 빠르게 향상되고 더 높은 정확도에 도달했다는 것이다. 이는 대화 구조 자체가 정답을 아는 것 이상으로 학습에 도움을 준다는 의미다. 또한 숫자 문제로 대화식 학습을 받은 AI를 정치 가짜 뉴스 판별 문제에 적용했더니, 학습 중 이 주제를 한 번도 접하지 않았는데도 기본 AI보다 빨리 정확도가 올라갔다. 대화 구조가 다른 종류의 문제에도 효과가 있다는 뜻이다.
AI의 ‘집단 사고’ 원리 이해가 차세대 AI 개발의 핵심
이번 연구는 AI가 단순히 더 길게 생각하는 것이 아니라, 내부적으로 다양한 성격과 전문성을 가진 여러 목소리를 동시에 사용한다는 것을 밝혔다. 이는 AI가 똑똑해지는 원리가 사람들이 모여 토론하며 문제를 해결하는 방식과 비슷할 수 있음을 보여준다. 특히 성격과 전문성이 다양할수록, 대화 구조가 있을수록 실제로 성능이 향상된다는 실험 결과는 앞으로 AI를 만들 때 중요한 참고자료가 될 것이다.
연구팀은 “계산량이 늘어나면서 AI의 생각 과정이 혼자 생각하는 방식에서 여러 관점이 토론하는 구조로 진화한다”며 “높은 성능의 AI는 여러 목소리가 어떻게 조율되는지에 달려 있다”고 설명했다. 이는 AI를 혼자 문제를 푸는 존재가 아니라 여러 생각이 협력하는 구조로 보는 관점의 전환을 제안한다. 즉, AI가 똑똑해지는 것은 단순히 크기 때문이 아니라 서로 다른 목소리들이 체계적으로 상호작용하기 때문이라는 것이다.
이러한 발견은 여러 AI를 함께 사용하는 시스템 설계에도 중요한 의미를 가진다. 현재 AI 업계에서는 여러 AI가 계층구조나 복잡한 네트워크로 상호작용을 하는 시스템이 늘고 있다. 이번 연구는 다양한 구조를 시도하는 것뿐만 아니라, 사람 사회에서처럼 다양한 관점, 성격, 전문성을 갖춘 AI들을 조합하는 것이 중요하다는 것을 보여준다. 다양성과 대화 구조가 어떻게 상호작용을 하는지 이해하는 것이 차세대 AI 개발의 핵심이 될 전망이다.
FAQ ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. AI가 ‘토론’한다는 게 정확히 무슨 뜻인가요?
A. AI가 문제를 풀 때 한 가지 방법만 따라가는 게 아니라, 내부에서 여러 가지 다른 의견을 동시에 만들어낸다는 뜻입니다. 예를 들어 수학 문제를 풀 때 “이렇게 풀면 될 것 같아”라고 했다가 스스로 “잠깐, 그건 아닌 것 같은데”라고 반박하고, “그럼 이 방법은 어때?”라고 다른 방법을 제시하는 식입니다. 마치 여러 사람이 회의실에서 의견을 주고받는 것처럼 AI 내부에서 다양한 관점이 경쟁하고 협력한다는 것이 이번 연구의 핵심 발견입니다.
Q2. 이번 연구가 AI 개발에 주는 실질적인 의미는 무엇인가요?
A. AI 성능을 높이려면 단순히 크기를 키우거나 데이터를 더 많이 학습시키는 것만으로는 부족하고, AI 내부의 ‘대화 구조’가 중요하다는 것을 알려줍니다. 실험 결과 대화하듯 생각하도록 학습한 AI가 단계별로만 생각하도록 학습한 AI보다 같은 시간에 2배 가까이 빠르게 배웠습니다. 앞으로 AI를 만들 때 여러 관점과 대화 구조를 의도적으로 설계하면 더 효율적으로 똑똑한 AI를 만들 수 있다는 뜻입니다.
Q3. 일반 사용자는 이 연구 결과를 어떻게 활용할 수 있나요?
A. ChatGPT나 Claude 같은 AI 서비스를 사용할 때 “여러 관점에서 검토해줘”, “반대 의견도 말해줘”, “전문가 여러 명이 토론하듯 답해줘” 같은 질문을 하면 더 나은 답변을 얻을 수 있습니다. 이번 연구는 AI가 한 가지 관점이 아니라 여러 관점에서 문제를 볼 때 더 정확한 답을 준다는 것을 과학적으로 증명했습니다. 특히 복잡한 문제일수록 AI에게 스스로 반박하고 다른 방법을 시도하도록 유도하는 것이 효과적입니다.
기사에 인용된 논문 원문은 arXiv에서 확인할 수 있다.
논문명: Reasoning Models Generate Societies of Thought
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다





