
오픈AI가 챗GPT 사용자 8억 명을 단 하나의 주 데이터베이스로 지원하고 있다는 사실을 공개했다. 해당 리포트에 따르면, 지난 1년간 데이터베이스 처리량이 10배나 늘어났지만, 오픈AI는 포스트그레SQL(PostgreSQL)이라는 데이터베이스 시스템 하나로 초당 수백만 건의 요청을 안정적으로 처리하고 있다. 오픈AI의 기술 보고서는 생성형 AI 서비스의 폭발적 성장을 뒷받침하는 데이터 저장 기술의 진화 과정을 담고 있다.
챗GPT 출시 후 사용자 폭증… 전 세계 50개 서버로 분산 처리
오픈AI는 챗GPT와 API 서비스를 운영하는 핵심 데이터 저장 시스템으로 포스트그레SQL을 수년간 사용해 왔다. 미국 버클리 캘리포니아 대학교에서 처음 개발된 이 시스템은 현재 단 하나의 주 서버와 전 세계 여러 지역에 흩어진 약 50개의 복제 서버로 구성되어 있다. 이 구조로 8억 명의 사용자가 만들어내는 엄청난 양의 데이터 요청을 처리한다는 점이 놀랍다.
챗GPT가 출시된 후 사용자는 전례 없는 속도로 증가했다. 오픈AI는 이에 대응하기 위해 애플리케이션과 데이터베이스 양쪽 모두에서 대대적인 개선 작업을 빠르게 진행했다. 서버의 성능을 높이는 동시에 데이터를 읽는 서버를 추가로 설치해 부하를 분산시켰다. 이런 구조는 지속적인 개선을 통해 현재까지도 앞으로의 성장을 충분히 감당할 수 있는 여유를 갖추고 있다.
하나의 주 서버가 다운되면 전체 서비스 마비… 과거 여러 차례 장애 경험
오픈AI 규모에서 단 하나의 주 서버만 사용한다는 것은 놀랍지만, 실제로는 많은 어려움이 있었다. 오픈AI는 데이터베이스 과부하로 인한 여러 차례의 심각한 서비스 장애를 겪었다. 이런 장애들은 비슷한 패턴을 보였다. 임시 저장 시스템 고장으로 인한 대규모 데이터 요청 급증, 복잡한 데이터 검색 작업이 처리 능력을 모두 소진하는 경우, 새로운 기능 출시로 인한 데이터 저장 요청 폭주 등이 대표적이다.
서버 사용률이 증가하면 응답 시간이 늘어나고 요청이 실패하기 시작한다. 그러면 사용자들이 재시도를 하면서 부하가 더욱 증가해 챗GPT와 API 서비스 전체가 느려지는 악순환이 발생한다. 오픈AI는 데이터를 읽는 작업에서는 포스트그레SQL이 잘 작동하지만, 데이터를 저장하는 작업이 많을 때는 여전히 문제가 발생한다고 설명했다. 이는 주로 포스트그레SQL의 데이터 관리 방식 때문이다. 데이터를 수정할 때 전체 내용을 복사해서 새 버전을 만들기 때문에, 저장 작업이 많아지면 실제보다 훨씬 많은 데이터를 처리해야 한다.
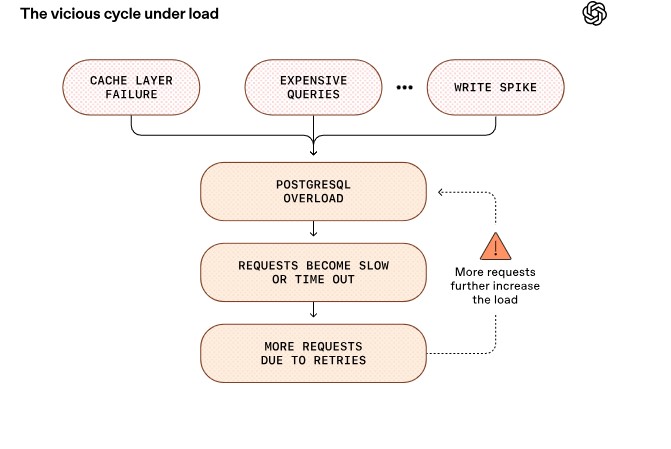
저장 작업 많은 업무는 다른 시스템으로 분산… 주 서버 부담 줄여
이런 문제를 해결하고 저장 부담을 줄이기 위해, 오픈AI는 데이터 저장이 많이 필요한 작업들을 애저 코스모스DB(Azure Cosmos DB) 같은 다른 시스템으로 계속 옮기고 있다. 애플리케이션도 불필요한 저장 작업을 최소화하도록 개선했다. 또한 현재 포스트그레SQL에 새로운 데이터 저장 공간을 추가하는 것을 더 이상 허용하지 않으며, 새로운 작업은 기본적으로 분산 시스템을 사용한다.
오픈AI의 시스템이 발전했지만, 포스트그레SQL은 여전히 하나의 주 서버가 모든 저장 작업을 처리하는 구조를 유지하고 있다. 주된 이유는 기존 시스템을 여러 개로 나누는 작업이 매우 복잡하고 오래 걸리기 때문이다. 수백 개의 연결 지점을 변경해야 하고, 몇 달 또는 몇 년이 걸릴 수 있다. 대부분의 작업이 데이터를 읽는 것이고 많은 개선을 했기 때문에, 현재 구조로도 계속되는 사용자 증가를 충분히 감당할 수 있다. 미래에 여러 서버로 나누는 것을 완전히 배제하지는 않지만, 당장은 우선순위가 아니라고 밝혔다.
주 서버 부담 줄이기부터 속도 제한까지 8가지 핵심 전략
오픈AI는 포스트그레SQL을 초당 수백만 건 처리 수준으로 확장하기 위해 다양한 개선 작업을 실행했다.
첫째, 주 서버의 부담을 최대한 줄였다. 저장 작업을 처리하는 서버가 하나뿐이기 때문에 저장 요청이 갑자기 늘어나면 서버가 빠르게 과부하될 수 있다. 오픈AI는 주 서버의 부담을 최대한 줄이기 위해 읽기와 저장 작업 모두를 최소화한다. 데이터를 읽는 요청은 가능한 한 복제 서버로 보내고, 주 서버에 남아야 하는 읽기 작업은 효율적으로 처리되도록 집중 관리한다.
둘째, 데이터 검색 작업을 최적화했다. 오픈AI는 처리 비용이 많이 드는 여러 검색 작업을 발견했다. 과거에는 이런 작업이 갑자기 늘어나면 처리 능력을 많이 소비해서 챗GPT와 API 요청이 모두 느려졌다. 복잡한 다중 검색은 가능한 한 피해야 하며, 필요하다면 검색 작업을 나누고 복잡한 처리는 애플리케이션에서 하도록 변경하는 것이 좋다.
셋째, 주 서버 고장 대비책을 마련했다. 데이터를 읽는 서버 하나가 다운되면 다른 서버로 요청을 보낼 수 있지만, 저장 작업을 처리하는 서버가 하나뿐이라는 것은 큰 약점이다. 주 서버가 다운되면 전체 서비스가 영향을 받는다. 오픈AI는 대부분의 중요한 요청이 데이터를 읽기만 한다는 점을 활용해, 이런 읽기 작업을 주 서버에서 복제 서버로 옮겼다. 이를 통해 주 서버가 다운되더라도 읽기 요청은 계속 처리될 수 있다. 저장 작업은 여전히 실패하지만, 읽기가 계속 가능하므로 최고 심각도 장애는 아니다.
넷째, 작업 부하를 분리했다. 특정 요청이 서버 자원을 지나치게 많이 사용하는 상황이 자주 발생한다. 이는 같은 서버에서 실행되는 다른 작업의 성능 저하를 초래할 수 있다. 오픈AI는 이 “시끄러운 이웃” 문제를 해결하기 위해 작업 부하를 별도의 서버로 분리한다. 구체적으로 요청을 중요도가 낮은 것과 높은 것으로 나누고 별도의 서버로 보낸다. 이렇게 하면 중요도가 낮은 작업이 자원을 많이 쓰더라도 중요한 요청의 성능은 영향받지 않는다.
다섯째, 연결 관리를 개선했다. 각 서버에는 최대 연결 개수 제한이 있다. 연결이 부족하거나 사용하지 않는 연결이 너무 많이 쌓이기 쉽다. 오픈AI는 과거 모든 가용 연결이 소진된 사고를 겪었다. 이를 해결하기 위해 중간 관리 시스템을 설치해 데이터베이스 연결을 효율적으로 관리한다. 이를 통해 연결을 재사용할 수 있어 연결 개수가 크게 줄어든다. 테스트 결과 평균 연결 시간이 50밀리초에서 5밀리초로 감소했다.
여섯째, 임시 저장 기능을 강화했다. 임시 저장된 데이터를 찾지 못하는 상황이 갑자기 늘어나면 데이터베이스로 요청이 쏟아져 처리 능력이 부족해지고 사용자 요청이 느려질 수 있다. 오픈AI는 데이터베이스의 부담을 줄이기 위해 임시 저장 기능을 사용해 대부분의 읽기 요청을 처리한다.
일곱째, 복제 서버 확장 방법을 개선했다. 주 서버는 모든 복제 서버에 데이터 변경 기록을 전송해야 한다. 복제 서버 개수가 늘어나면 주 서버가 더 많은 서버에 기록을 보내야 하므로 네트워크와 처리 능력 모두에 부담이 증가한다. 오픈AI는 현재 여러 지역에 약 50개의 복제 서버를 운영해 응답 시간을 최소화한다. 현재는 주 서버가 모든 복제 서버에 직접 기록을 전송해야 하지만, 매우 큰 서버와 높은 네트워크 성능으로 잘 작동한다. 오픈AI는 애저 포스트그레SQL 팀과 협력해 중간 복제 서버가 하위 서버에 기록을 전달하는 계단식 구조를 테스트하고 있다. 이를 통해 주 서버에 부담을 주지 않고 100개 이상의 복제 서버로 확장할 수 있다.
여덟째, 요청 속도 제한을 적용했다. 특정 요청이 갑자기 늘어나거나, 처리 비용이 많이 드는 검색이 급증하거나, 재시도가 폭주하면 처리 능력, 입출력, 연결 등 중요한 자원이 빠르게 소진되어 서비스 전체가 느려질 수 있다. 오픈AI는 여러 단계에서 속도 제한을 적용해 갑작스러운 요청 증가가 데이터베이스를 압도하고 연쇄 장애를 일으키는 것을 방지한다.
응답 시간 수십 밀리초에 99.999% 안정성 달성
이런 노력의 결과, 오픈AI는 애저 포스트그레SQL을 가장 대규모 서비스에도 사용할 수 있도록 확장할 수 있음을 증명했다. 포스트그레SQL은 데이터를 읽는 작업에서 초당 수백만 건을 처리하며, 챗GPT 및 API 같은 오픈AI의 가장 중요한 서비스를 운영한다. 약 50개의 복제 서버를 추가하면서도 데이터 동기화 지연을 거의 0에 가깝게 유지했으며, 전 세계 여러 지역에서 빠른 응답 시간을 유지하고, 미래 성장을 위한 충분한 여유를 확보했다.
이런 확장은 응답 시간을 최소화하고 안정성을 향상시키면서 이루어졌다. 오픈AI는 실제 서비스에서 지속적으로 수십 밀리초의 응답 시간과 99.999%의 안정성을 제공한다. 지난 12개월 동안 단 한 건의 최고 심각도 데이터베이스 장애만 발생했다. 이는 챗GPT 이미지 생성 기능이 급속히 확산될 때 발생했는데, 당시 1주일 만에 1억 명 이상의 신규 사용자가 가입하면서 저장 요청이 갑자기 10배 이상 급증했다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 오픈AI는 왜 8억 사용자를 하나의 데이터베이스로 처리할 수 있나요?
A. 챗GPT와 API 서비스는 대부분 데이터를 읽기만 하고 저장하는 경우가 적다는 특성이 있다. 오픈AI는 하나의 주 서버에서 모든 저장 작업을 처리하고, 전 세계 여러 지역에 흩어진 약 50개의 복제 서버로 읽기 요청을 분산시킨다. 또한 임시 저장, 연결 관리, 검색 최적화 등 다양한 기술 개선을 통해 서버 부담을 최소화했다.
Q2. 포스트그레SQL의 가장 큰 문제점은 무엇인가요?
A. 포스트그레SQL은 데이터를 읽는 작업에서는 잘 작동하지만, 저장 작업이 많을 때는 효율이 떨어진다. 데이터를 수정할 때 전체 내용을 복사해서 새 버전을 만드는 방식을 사용하기 때문이다. 저장 작업이 많은 상황에서는 실제보다 훨씬 많은 데이터를 처리해야 한다. 오픈AI는 이를 해결하기 위해 저장 작업이 많은 업무를 애저 코스모스DB 같은 다른 시스템으로 옮기고 있다.
Q3. 오픈AI는 데이터베이스 장애를 어떻게 예방하나요?
A. 오픈AI는 작업 부하 분리, 속도 제한, 임시 저장 잠금 장치 등을 활용해 장애를 예방한다. 작업 부하 분리는 중요도에 따라 요청을 별도의 서버로 나누어 한 작업의 문제가 다른 작업에 영향을 주지 않도록 한다. 속도 제한은 갑작스러운 요청 증가를 막으며, 임시 저장 잠금 장치는 같은 데이터를 찾는 여러 요청 중 하나만 데이터베이스에 접근하도록 해서 불필요한 부담을 줄인다.
기사에 인용된 리포트 원문은 OpenAI에서 확인 가능하다.
리포트명: Scaling PostgreSQL to power 800 million ChatGPT users
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





