
중국 AI 기업 딥시크(DeepSeek)가 사람의 눈 움직임을 따라하는 새로운 문서 인식 기술을 공개했다. 해당 논문에 따르면, 기존 AI가 이미지를 로봇처럼 무조건 왼쪽 위에서 오른쪽 아래로 읽었다면, 새 기술은 사람이 나선 그림을 볼 때처럼 의미 있는 순서로 시선을 옮긴다고 밝혔다. 덕분에 복잡한 표나 수식이 섞인 문서도 정확하게 읽을 수 있게 됐다.
로봇식 읽기 버리고 사람처럼 ‘의미’ 따라 읽는다
딥시크가 공개한 딥시크-OCR 2(DeepSeek-OCR 2)는 문서를 읽는 AI의 새로운 방식을 보여준다. 지금까지 이미지를 보는 AI들은 사진을 작은 조각으로 나눈 뒤, 무조건 왼쪽 위부터 시작해서 오른쪽 아래까지 순서대로 읽었다. 마치 책을 한 줄씩 읽듯이 말이다. 하지만, 이 방식은 문제가 있었다. 실제 문서는 2차원 평면인데, 이를 억지로 1차원 줄로 만들어 읽다 보니 표와 텍스트, 수식이 섞여 있을 때 내용의 연결 관계를 제대로 이해하지 못했다.
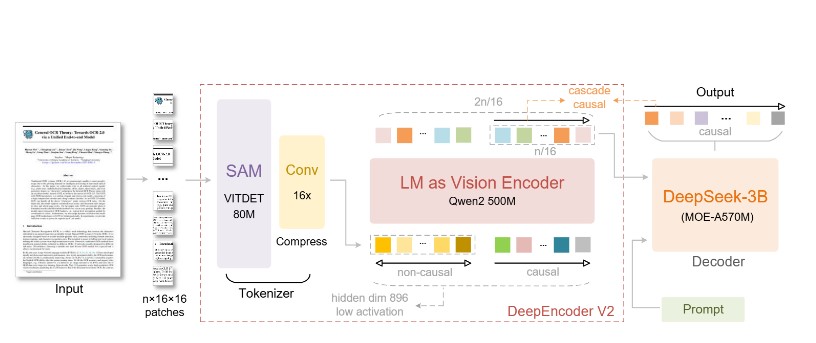
새로운 딥인코더 V2(DeepEncoder V2)는 이 문제를 해결했다. 사람의 눈이 작동하는 방식에서 힌트를 얻었다. 우리 눈은 중심부는 선명하게 보면서도 주변 전체를 동시에 인식한다. 그리고 나선 그림을 볼 때처럼, 눈동자가 의미 있는 순서로 움직인다. 각각의 시선은 이전에 본 것에 영향을 받는다.
이 기술의 핵심은 ‘인과적 흐름 쿼리’라는 개념이다. 쉽게 말해 “이전에 뭘 봤는지에 따라 다음엔 어디를 봐야 할지 결정한다”는 뜻이다. AI가 이미지의 정보 조각들을 공간상의 위치가 아니라 내용의 의미에 따라 다시 정리한다. 예를 들어 논문을 볼 때 제목 → 저자 → 본문 → 표 → 그림 순서로 읽는 것처럼, AI도 이제 문서의 논리적 구조를 파악해서 읽는 순서를 스스로 정한다.
기존 방식 버리고 언어 모델 구조 활용… 적은 계산으로 효율 높여
딥인코더 V2의 또 다른 특징은 이미지를 분석하는 방식을 완전히 바꿨다는 점이다. 기존에는 CLIP이라는 이미지 분석 도구를 사용했는데, 이번에는 글을 이해하는 언어 모델 구조를 이미지 분석에 적용했다. 구체적으로는 Qwen2-0.5B라는 5억 개 규모의 학습 값을 가진 모델을 사용했다. 이는 기존 CLIP의 3억 개와 비슷한 수준이라 컴퓨터 계산량을 크게 늘리지 않으면서도 효율적으로 작동한다.
이 구조는 실제로 2단계로 나뉜다. 1단계에서 이미지 분석 엔진이 이미지 정보 조각들을 의미 있는 순서로 다시 배열한다. 2단계에서 언어 모델이 이렇게 정리된 순서대로 내용을 이해한다. 기존 방식이 위치만 보고 순서를 정했다면, 새 방식은 내용의 의미를 파악해서 순서를 정하기 때문에 언어 모델이 훨씬 이해하기 쉽다.
이미지 한 장당 처리하는 정보 조각은 256개에서 1,120개 사이다. 최소 256개는 1024×1024 크기 이미지 하나를 처리할 때 나오고, 최대 1,120개는 구글의 제미나이-3 프로 AI가 사용하는 최대치와 같다. 큰 이미지는 1024×1024 크기로, 작은 부분은 768×768 크기로 나눠서 보는 방식을 사용했다.
문서 인식 정확도 91%… 읽는 순서 찾기도 크게 개선
딥시크-OCR 2는 옴니닥벤치(OmniDocBench) v1.5라는 평가 시험에서 뛰어난 성적을 거뒀다. 이 시험은 잡지, 학술 논문, 연구 보고서 등 9가지 종류의 문서 1,355장으로 구성되어 있고, 중국어와 영어 문서를 모두 포함한다.
결과는 전체 정확도 91.09%였다. 이전 버전인 딥시크-OCR의 87.36%보다 3.73% 올랐다. 더 놀라운 건 더 적은 정보량으로 이 성적을 냈다는 점이다. 이전 버전은 이미지 하나당 최대 1,156개의 정보 조각을 사용했지만, 새 버전은 1,120개만 사용했다.
특히 ‘읽는 순서를 얼마나 정확하게 찾아내는가’를 측정하는 지표에서 큰 개선이 있었다. 오류 정도가 0.085에서 0.057로 줄었다. 숫자가 작을수록 정확하다는 뜻이다. 이는 새 AI가 이미지를 보고 어떤 순서로 읽어야 할지 스스로 잘 판단한다는 의미다. 텍스트 인식 오류는 0.073에서 0.048로, 수식 인식은 0.236에서 0.198로, 표 인식은 0.123에서 0.096으로 모두 좋아졌다.
구글의 제미나이-3 프로와 비교해도 딥시크-OCR 2가 더 나았다. 비슷한 정보량(1,120개)을 사용했을 때 문서 해석 오류가 0.100으로, 제미나이-3 프로의 0.115보다 낮았다. 적은 계산으로도 더 정확하다는 얘기다.
실제 서비스에서도 같은 내용 반복 오류 대폭 줄어
딥시크-OCR 2는 시험 환경뿐 아니라 실제 서비스에서도 개선된 성능을 보였다. 딥시크-OCR은 두 가지 용도로 쓰인다. 하나는 사용자가 올린 이미지를 실시간으로 읽는 온라인 서비스고, 다른 하나는 대량의 PDF 파일을 처리하는 데이터 준비 작업이다.
실제 서비스에서는 정답을 알 수 없기 때문에 ‘같은 내용을 얼마나 반복하는가’를 주요 품질 지표로 본다. AI가 혼란스러워하면 같은 문장을 여러 번 반복하는 경향이 있기 때문이다. 온라인 사용자 이미지의 경우 반복 오류가 6.25%에서 4.17%로 2.08% 줄었다. PDF 처리에서는 3.69%에서 2.88%로 0.81% 감소했다.
연구팀은 9가지 문서 유형별로 자세히 비교했다. 딥시크-OCR 2는 대부분 이전 버전보다 나았지만, 신문에서는 여전히 0.13 이상의 오류를 보였다. 연구팀은 두 가지 이유를 추정했다.
첫째, 정보 조각 개수에 제한을 뒀는데 텍스트가 아주 많은 신문에는 부족할 수 있다.
둘째, 학습 데이터에 신문이 25만 장밖에 없어서 충분히 배우지 못했을 수 있다. 하지만 읽는 순서를 찾아내는 능력은 모든 문서 종류에서 일관되게 이전 버전을 앞섰다.
진짜 2차원 이해하는 AI와 모든 정보 처리 가능한 AI로 발전
딥시크-OCR 2는 새로운 AI 구조의 가능성을 보여준다. 이미지 분석 엔진과 언어 모델을 연결한 이 방식은 진짜 2차원 이해로 가는 길을 제시한다. 이미지 분석 엔진이 시각 정보를 의미 있는 순서로 다시 정리하고, 언어 모델이 그 순서대로 이해한다. 2차원 이미지 이해를 서로 보완하는 두 개의 1차원 순서 처리 작업으로 나눈 것이다.
물론 완벽한 2차원 이해까지는 갈 길이 멀다. 예를 들어 한 곳을 여러 번 다시 보거나 복잡한 경로로 시선을 옮기려면 지금보다 훨씬 더 많은 정보 조각이 필요할 것이다.
더 중요한 건 이 기술이 모든 종류의 정보를 처리하는 통합 AI로 발전할 가능성이다. 하나의 이미지 분석 엔진이 글, 소리, 이미지를 모두 처리할 수 있다는 뜻이다. 핵심 구조는 같고, 각 정보 종류마다 다른 질문 방식만 학습하면 된다. 이 엔진은 같은 기본 구조 안에서 글을 압축하고, 소리 특징을 뽑아내고, 이미지 내용을 재구성할 수 있다. 연구팀은 딥시크-OCR이 이 방향으로 가는 첫 시도였고, 딥시크-OCR 2는 한 걸음 더 나아간 것이라고 밝혔다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 딥시크-OCR 2가 기존 문서 인식 AI와 뭐가 다른가요?
A. 기존 문서 인식 AI는 이미지를 무조건 왼쪽 위에서 오른쪽 아래로 한 줄씩 읽었습니다. 하지만 이번 논문에서 사용한 딥시크의 문서 인식 AI인 딥시크-OCR 2는 사람처럼 의미를 파악하며 읽습니다. 제목 보고, 본문 읽고, 표 확인하는 식으로 내용에 맞춰 순서를 정하기 때문에 복잡한 문서도 정확하게 이해합니다.
Q2. 이 기술은 어디에 쓸 수 있나요?
A. 종이 문서를 스캔해서 컴퓨터로 옮기거나, 논문을 자동으로 분석하거나, 업무 자동화에 쓸 수 있습니다. 특히 수식이나 표가 많이 들어간 연구 보고서, 잡지, 교과서를 정확한 디지털 텍스트로 바꿀 수 있습니다.
Q3. 다른 AI보다 얼마나 더 좋은가요?
A. 문서 인식 시험에서 91.09%의 정확도를 기록했습니다. 이전 버전보다 3.73% 올랐고, 계산량은 더 적습니다. 구글 제미나이-3 프로 같은 대형 AI와 비슷하거나 더 나은 성능을 보였고, 특히 문서를 읽는 순서를 찾아내는 능력이 크게 좋아졌습니다.
기사에 인용된 논문 원문은 GitHub에서 확인 가능하다.
논문명: DeepSeek-OCR 2: Visual Causal Flow
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.




![[AI 트렌드] 말 한마디로 내 노래가 생긴다? 제미나이 음악 생성 프롬프트](https://aimatters.co.kr/wp-content/uploads/2026/03/AI-매터스-기사-썸네일-3.jpg)