중국의 AI 기업 Z.ai가 새로운 대규모 언어모델 GLM-5를 공개했다. 해당 리포트에 따르면, 이번 모델은 단순히 채팅에 응답하는 수준을 넘어 복잡한 시스템 설계와 장기 프로젝트를 수행할 수 있는 ‘에이전트 엔지니어링’ 능력을 갖췄다. 특히 문서 작업부터 코딩, 장기 사업 운영까지 실무에서 바로 활용할 수 있는 결과물을 생성한다는 점에서 주목받고 있다.
파라미터 2배 증가, 학습 데이터 28.5조 토큰으로 확대
GLM-5는 이전 버전인 GLM-4.5와 비교해 규모가 크게 확대됐다. 전체 파라미터는 355B(실제 활성화되는 파라미터 32B)에서 744B(활성화 40B)으로 약 2배 증가했다. 파라미터란 AI 모델이 학습을 통해 조정하는 내부 변수로, 이 수치가 클수록 모델이 더 복잡한 패턴을 학습할 수 있다. 사전 학습에 사용된 데이터도 23조 토큰에서 28.5조 토큰으로 늘어났다. 토큰은 AI가 텍스트를 처리하는 최소 단위로, 대략 단어의 3/4 정도 길이에 해당한다.
모델 규모가 커지면 성능은 향상되지만 운영 비용도 증가하는 문제가 있다. Z.ai는 이를 해결하기 위해 딥시크 스파스 어텐션(DeepSeek Sparse Attention, DSA)이라는 기술을 통합했다. 이 기술은 긴 문맥을 처리할 때 모든 정보를 동시에 분석하는 대신 중요한 부분에만 집중하여 계산량을 줄이는 방식이다. 덕분에 배포 비용을 대폭 낮추면서도 긴 문서를 처리하는 능력은 유지할 수 있었다.
오픈소스 모델 중 코딩과 추론 작업 1위 달성
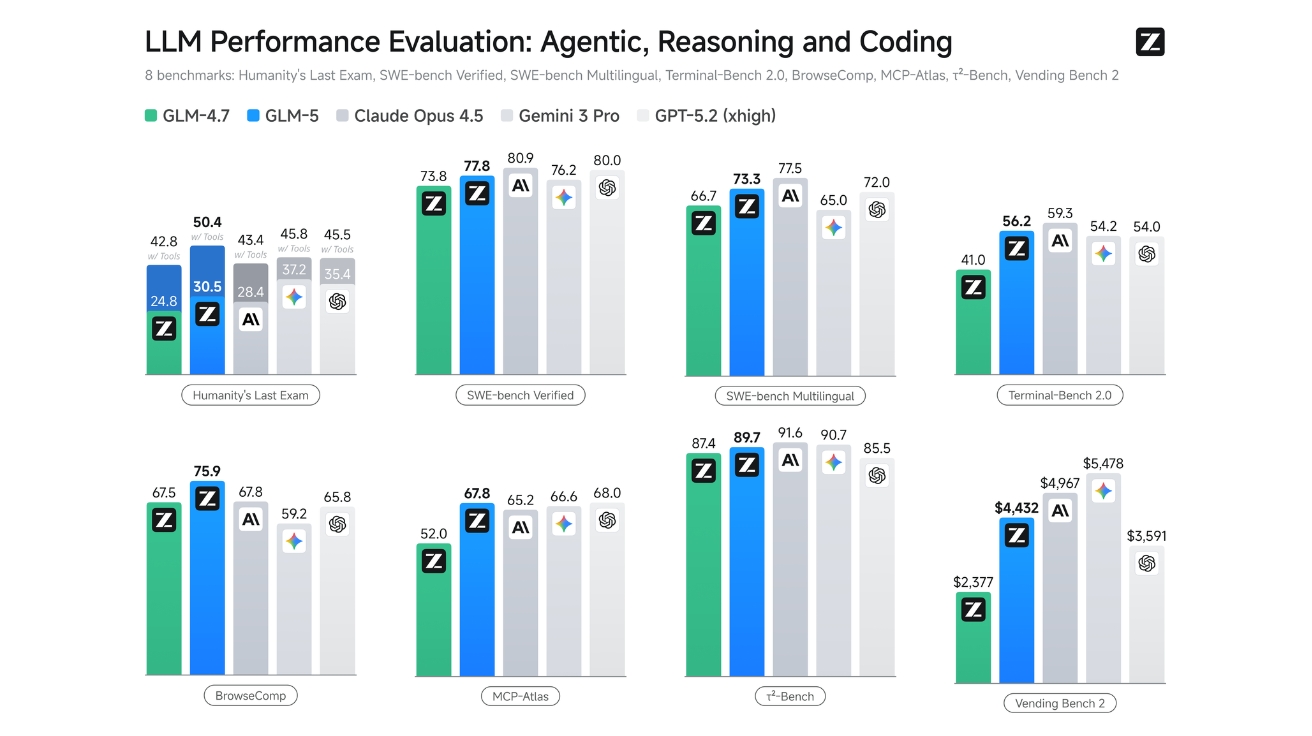
GLM-5는 다양한 벤치마크 테스트에서 오픈소스 AI 모델 중 최고 수준의 성능을 기록했다. 추론, 코딩, 에이전트 작업에서 특히 강점을 보였으며, 클로드 오푸스(Claude Opus) 4.5나 GPT-5.2 같은 비공개 최첨단 모델과의 격차도 좁혔다.
Humanity’s Last Exam이라는 고난도 추론 테스트에서 GLM-5는 30.5점을 기록했다. 이는 이전 버전 GLM-4.7(24.8점)보다 크게 향상된 수치다. 도구 사용이 허용된 버전에서는 50.4점으로 오픈소스 모델 중 가장 높은 점수를 받았다. 코딩 능력을 평가하는 SWE-벤치 검증(SWE-bench Verified) 테스트에서는 77.8점을 기록해 실제 소프트웨어 버그를 수정하는 능력이 뛰어남을 입증했다.
장기 운영 능력을 측정하는 벤딩 벤치 2(Vending Bench 2)에서 GLM-5는 오픈소스 모델 중 1위를 차지했다. 이 테스트는 AI가 1년 동안 가상의 자판기 사업을 운영하며 최종 계좌 잔액을 얼마나 늘리는지 평가한다. GLM-5는 4,432달러의 최종 잔액을 기록했는데, 이는 클로드 오푸스 4.5(4,967달러)에 근접한 수치다. 장기적인 계획 수립과 자원 관리 능력이 뛰어나다는 의미다.
대화 넘어 실제 문서와 파일 생성하는 ‘오피스 AI’
GLM-5의 가장 큰 특징은 단순히 대화를 나누는 수준을 넘어 실무에서 바로 사용할 수 있는 결과물을 만들어낸다는 점이다. Z.ai는 이를 “채팅에서 업무로”의 전환이라고 표현한다. 마치 지식 근로자가 워드나 엑셀을 사용하듯, AI가 직접 문서를 작성하고 파일로 저장해주는 것이다.
GLM-5는 텍스트나 원본 자료를 받아 즉시 워드(.docx), PDF(.pdf), 엑셀(.xlsx) 파일로 변환할 수 있다. 제품 요구사항 문서(PRD), 수업 계획안, 시험지, 재무 보고서, 일정표, 메뉴 등 다양한 문서를 처음부터 끝까지 완성해 바로 사용할 수 있는 형태로 제공한다.
예를 들어 미국 고등학교 학생회가 풋볼 경기 후원을 받기 위한 제안서를 만든다고 가정해보자. GLM-5에게 학교 배경, 문서 목적, 대상 독자를 설명하면, AI는 자동으로 소개, 행사 설명, 후원금 사용처, 후원 등급별 혜택, 결론 등을 포함한 완성된 워드 문서를 생성한다. 여기에는 사진 배치, 표 삽입, 색상 배합까지 포함되어 있어 별도 편집 없이 바로 제출할 수 있다.
강화학습 인프라 ‘슬라임’으로 훈련 효율 대폭 향상
AI 모델의 성능을 높이는 핵심 기술 중 하나가 강화학습(Reinforcement Learning, RL)이다. 강화학습은 AI가 시행착오를 통해 스스로 학습하며 능력을 개선하는 방법이다. 하지만 대규모 언어모델에 강화학습을 적용하면 훈련 효율이 떨어지는 문제가 있었다.
Z.ai는 이를 해결하기 위해 ‘슬라임(slime)’이라는 새로운 비동기 강화학습 인프라를 개발했다. 슬라임은 훈련 처리량과 효율성을 크게 향상시켜, 더 세밀하게 모델을 조정할 수 있게 만들었다. 이는 사전 학습(pre-training)으로 기본 능력을 갖춘 모델을 사후 학습(post-training)을 통해 ‘우수함’으로 끌어올리는 과정을 더 효과적으로 만든다. 사전 학습이 학생이 교과서를 읽으며 기초를 쌓는 것이라면, 강화학습을 통한 사후 학습은 실전 문제를 풀며 실력을 다듬는 과정에 비유할 수 있다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. GLM-5는 어떤 방식으로 사용할 수 있나요?
A. GLM-5는 여러 방법으로 접근할 수 있습니다. Z.ai 웹사이트에서 채팅 모드나 에이전트 모드로 무료 체험이 가능하며, 클로드 코드 같은 코딩 도구와 연동하여 프로그래밍 작업에 활용할 수 있습니다. 개발자라면 API를 통해 자체 서비스에 통합하거나, 허깅페이스에서 모델 가중치를 다운로드해 직접 서버에 설치할 수도 있습니다. MIT 라이선스로 공개되어 상업적 사용도 자유롭습니다.
Q2. 파라미터가 많다는 것이 왜 중요한가요?
A. 파라미터는 AI가 학습을 통해 조정하는 내부 설정값으로, 사람의 뇌에서 뉴런 연결에 해당합니다. 파라미터가 많을수록 AI는 더 복잡한 패턴과 관계를 학습할 수 있어 어려운 문제를 해결하는 능력이 향상됩니다. 다만 파라미터가 많으면 계산에 필요한 컴퓨터 자원도 늘어나기 때문에, GLM-5는 스파스 어텐션 같은 최적화 기술을 함께 적용해 효율성을 유지합니다.
Q3. GLM-5가 만든 문서는 실제로 바로 사용할 수 있나요?
A. 네, GLM-5는 편집 가능한 워드, PDF, 엑셀 파일을 직접 생성합니다. 사용자가 요구사항을 설명하면 AI가 문서 구조, 내용, 서식, 이미지 배치까지 완성해 다운로드 가능한 파일로 제공합니다. 물론 생성된 문서는 필요에 따라 추가 수정이 가능하지만, 대부분의 경우 최소한의 조정만으로 실무에 활용할 수 있는 수준입니다.
기사에 인용된 리포트 원문은 Z.ai에서 확인 가능하다.
리포트명: GLM-5: From Vibe Coding to Agentic Engineering
이미지 출처: Z.ai
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.