
최신 AI 모델들이 이미지를 ‘이해’한다는 건 이제 상식처럼 여겨진다. 그런데 15×15 크기의 단순한 격자 그림 하나가 그 믿음을 뒤흔들었다. 미국 로체스터 공과대학교(Rochester Institute of Technology)의 연구자 유발 레벤탈(Yuval Levental)이 발표한 논문은, 클로드 오퍼스(Claude Opus), 챗GPT 5.2(ChatGPT 5.2), 제미나이 3 씽킹(Gemini 3 Thinking) 등 세계 최고 수준의 AI 모델 세 가지가 ‘텍스트처럼 생긴 이미지’와 ‘단순한 검은 사각형’을 얼마나 다르게 인식하는지를 실험으로 보여준다. 결론은 놀랍다. AI는 글자를 닮은 기호는 정확하게 읽지만, 순수한 도형 앞에서는 속절없이 무너진다.
실험 설계: 같은 정보, 다른 모습으로
실험은 간단하다. 연구자는 15×15 칸으로 이루어진 격자(총 225칸)를 15개 만들었다. 각 격자의 일부 칸은 검게 채워지고 나머지는 비어 있다. 채워진 칸의 비율은 전체의 약 10.7%에서 41.8%까지 다양하다. 이 격자를 두 가지 방식으로 이미지로 만들었다. 첫 번째는 빈 칸을 점(.)으로, 채워진 칸을 우물 정자 모양(#)으로 표현한 ‘텍스트 기호 이미지’다. 두 번째는 같은 정보를 그냥 검은 사각형과 흰 사각형으로만 표현한 ‘채워진 사각형 이미지’다. 두 이미지 모두 PNG 파일로 만들어졌으며, AI는 이 이미지를 보고 어느 칸이 채워져 있는지 그대로 받아 적는 과제를 수행했다. 코드나 이미지 처리 도구 사용은 금지됐고, 오직 시각적 관찰만으로 답해야 했다.
텍스트 기호엔 91%, 사각형엔 최저 29%: 성능 격차의 충격
결과는 세 모델 모두에서 극명하게 갈렸다. 텍스트 기호 이미지를 사용했을 때 클로드 오퍼스와 챗GPT 5.2는 약 91%의 칸 정확도와 약 84%의 F1 점수를 기록했다. F1 점수란 얼마나 정확하게 채워진 칸을 찾아냈는지를 종합적으로 나타내는 수치로, 100에 가까울수록 완벽하다. 제미나이 3 씽킹도 텍스트 조건에서 약 84%의 정확도를 보였다.
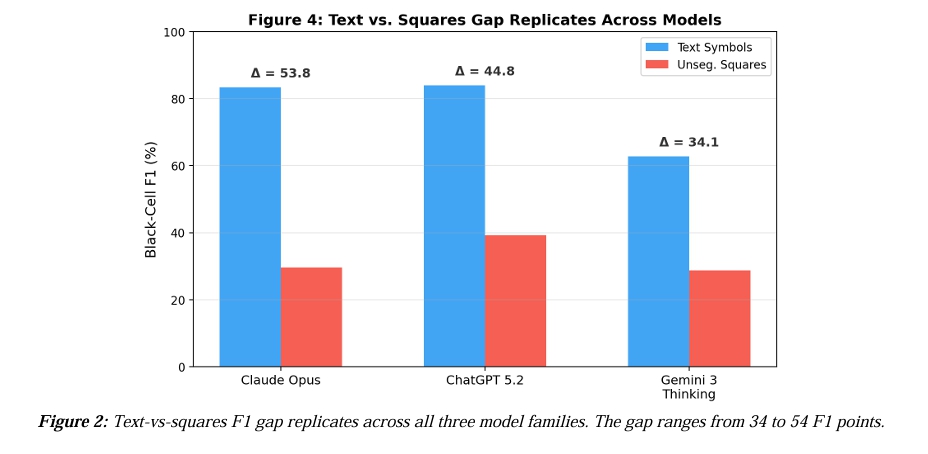
그러나 같은 정보를 검은 사각형으로만 표현하자 세 모델 모두 성능이 무너졌다. 클로드 오퍼스는 F1 점수가 29.6%로 떨어졌고, 챗GPT 5.2는 39.2%에 그쳤다. 특히 제미나이 3 씽킹은 사각형 조건에서 평균 28.7%의 F1 점수를 기록했는데, 채워진 칸의 비중이 35% 이상인 고밀도 격자에서는 F1 점수가 11%대까지 수직 낙하하며 가장 처참한 붕괴를 보였다. 텍스트와 사각형 조건 사이의 F1 점수 차이는 클로드에서 53.8점, 챗GPT에서 44.8점, 제미나이에서 34.1점에 달했다. 격자에 구분선(그리드라인)을 추가해도 성과는 거의 달라지지 않았다. 연구자는 이 차이가 단순한 모델별 특성이 아니라, 현재 AI 설계 방식의 구조적 한계를 반영한다고 결론 내렸다.
AI는 도형이 아니라 글자를 ‘보고’ 위치를 파악한다
이 실험이 중요한 이유는 두 이미지 모두 같은 방식으로 AI의 시각 처리 장치를 통과하기 때문이다. AI가 이미지를 볼 때는 반드시 ‘시각 인코더(visual encoder)’라는 부품을 거친다. 이 장치는 픽셀 정보를 AI가 이해할 수 있는 형태로 변환한다. 텍스트 기호 이미지도 결국 이미지이므로 이 장치를 통과하며, 직접 문자 데이터가 입력되는 방식이 아니다. 그런데도 텍스트처럼 생긴 기호가 있을 때만 성능이 급격히 좋아진다.
연구자는 이를 ‘텍스트 인식 경로(text-recognition pathway) 가설’로 설명한다. AI는 이미지 안에 글자처럼 생긴 요소가 있으면, 마치 내부에서 광학 문자 인식(OCR, Optical Character Recognition) 기술이 작동하듯 그 요소의 위치 정보를 정밀하게 파악한다. 반면 순수한 도형, 즉 텍스트와 무관한 시각 요소에 대해서는 위치를 대략적으로만 파악하는 ‘시각적 특징 경로(visual-feature pathway)’에 의존하게 된다. 이 두 경로의 성능 차이가 실험에서 확인된 엄청난 점수 격차의 원인이라는 설명이다.
모델마다 다른 방식으로 틀린다: 과소계산, 과대계산, 환각
흥미로운 점은 세 모델이 각각 다른 방식으로 실패한다는 것이다. 클로드 오퍼스는 실제보다 적게 채워진 칸을 찾아내는 ‘과소 계산’ 오류를 보였다. 실제로 채워진 칸이 60개라면 평균 45개 정도만 인식했으며, 그나마도 위치가 틀린 경우가 많았다. 채워진 영역이 어디쯤에 있는지는 감지하지만, 정확한 개별 칸 경계를 구분하지 못하는 것이다.
챗GPT 5.2는 반대로 실제보다 훨씬 많은 칸이 채워져 있다고 판단하는 ‘과대 계산’ 오류를 보였다. 실제 78~94개가 채워진 격자에서 112~133개를 채워진 것으로 답하기도 했으며, 심지어 격자의 가로 칸 수까지 16~17개로 잘못 인식하는 현상도 나타났다. 실제 패턴 주변에 없는 칸까지 채워진 것으로 상상해버리는 셈이다.
제미나이 3 씽킹의 실패 방식은 가장 독특하다. 밀도가 일정 수준을 넘어서면 실제 이미지를 무시하고 L자, 십자, 플러스 모양 같은 전형적인 기하학 패턴을 반복해서 만들어냈다. 이는 모델이 처리 용량의 한계에 도달했을 때 실제 입력 대신 학습 과정에서 기억한 패턴을 꺼내 쓰는 일종의 ‘환각(hallucination)’ 현상이다. 텍스트 조건에서도 밀도가 높아지면 알파벳 E, H, S 같은 단순한 문자 모양으로 답하는 현상이 나타났다.
AI가 도형을 잘 보게 하려면: 텍스트 라벨을 붙여라
연구자는 이 한계를 극복하기 위한 현실적인 방법도 제안했다. 가장 빠르게 적용 가능한 방법은 ‘텍스트 발판(textual scaffolding)’ 전략이다. 이미지에 좌표 레이블이나 행·열 번호를 추가해주면, AI가 위치 정보를 텍스트 인식 경로로 처리하도록 유도할 수 있다. 의료 영상, 자율주행 시스템, 과학 데이터 시각화, 문서 분석처럼 정확한 위치 파악이 중요한 분야에서는 이런 개선이 실질적인 차이를 만들 수 있다.
더 근본적인 해결책으로는 AI의 시각 인코더를 설계할 때, 이미지-텍스트 일치 방식이 아니라 공간 좌표를 직접 예측하는 방식으로 훈련하는 것을 제안했다. 현재 많은 AI 모델이 기반으로 사용하는 클립(CLIP)과 같은 시각 모델은 전체적인 의미 파악에 최적화돼 있어, 픽셀 단위의 정밀한 위치 정보를 처리하는 데 구조적으로 취약하다는 것이 이번 연구가 지적하는 핵심이다.
FAQ ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.
Q. AI가 이미지를 잘 이해한다고 하는데, 이번 실험에서 왜 이렇게 성능이 낮게 나온 건가요?
A. AI가 이미지를 ‘이해’한다고 할 때, 실제로는 이미지 전체의 의미(예: “이것은 강아지 사진이다”)를 파악하는 데 강점이 있습니다. 하지만 이번 실험처럼 격자의 각 칸이 정확히 어디에 있는지를 픽셀 단위로 파악하는 능력은 전혀 다른 문제입니다. 현재 AI는 글자처럼 생긴 시각 정보가 없으면 정밀한 위치 판단에 매우 취약한 것으로 드러났습니다.
Q. 클로드, 챗GPT, 제미나이 중 어떤 모델이 가장 뛰어난가요?
A. 텍스트 기호 인식에서는 클로드 오퍼스와 챗GPT 5.2가 약 91%로 제미나이(약 84%)보다 높은 정확도를 보였습니다. 반면 단순한 도형 인식에서는 제미나이가 밀도가 낮을 때 일시적으로 가장 좋은 성능을 냈으나, 밀도가 높아지면 가장 먼저 무너졌습니다. 어느 모델이 ‘더 뛰어나다’기보다는 각자 다른 방식으로 실패한다는 점이 이번 연구의 핵심 발견입니다.
Q. 이 연구가 실생활에서 AI를 사용할 때 어떤 의미가 있나요?
A. AI에게 도면, 의료 이미지, 지도, 그래프 등 텍스트가 없는 순수 시각 자료를 분석하게 할 때는 결과를 그대로 신뢰하지 않는 것이 좋습니다. 반면 이미지에 텍스트 레이블이나 좌표 정보가 포함되면 AI의 정확도가 크게 올라갑니다. 따라서 AI에게 시각 자료를 분석 요청할 때는 가능한 한 텍스트로 된 설명이나 주석을 함께 제공하는 것이 효과적입니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Can Vision-Language Models See Squares? Text-Recognition Mediates Spatial Reasoning Across Three Model Families
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





