
최신 AI가 바둑을 정복하고 코드를 짜고 소설을 쓰는 시대, 1977년에 만들어진 텍스트 게임을 클리어하는 수준이 평균 10%도 미치는 못한다면 믿겠는가. 네덜란드 트벤테 대학교(University of Twente) 연구팀이 챗GPT(ChatGPT), 클로드(Claude), 제미나이(Gemini) 등 최첨단 대형 언어 모델(LLM, Large Language Model)을 1977년 텍스트 어드벤처 게임 ‘조크(Zork)’에 투입해 실험한 결과, 모든 AI가 평균 완료율 10% 미만이라는 초라한 성적표를 받아 들었다. 이 연구는 현재 AI의 추론 능력에 대한 근본적인 질문을 다시 던진다.
왜 하필 1977년 게임인가: 조크가 AI의 진짜 실력을 드러내는 이유
조크(Zork)는 미국 MIT에서 개발되어 1977년 처음 출시된 텍스트 기반 어드벤처 게임이다. 화면에 그림이나 영상이 전혀 없고, 오직 글자로만 상황이 묘사된다. 예를 들어 “당신은 흰 집 서쪽 열린 들판에 서 있습니다”라는 문장이 나오면 플레이어는 “북쪽으로 가라” 혹은 “칼을 집어라” 같은 명령어를 타이핑해 게임을 진행한다. 최대 350점을 획득하면 클리어다.
이 게임이 AI 테스트에 적합한 이유는 명확하다. 화면을 보고 패턴을 인식하는 능력이 아니라, 글로 묘사된 공간을 머릿속으로 지도처럼 구성하고, 이전에 실패한 행동을 기억해 전략을 바꾸고, 아이템들 사이의 인과관계를 파악하는 능력이 요구되기 때문이다. 즉 단순한 언어 생성이 아닌 ‘진짜 이해’와 ‘적응적 문제 해결’이 필요하다. 연구팀은 이 게임이 AI가 흔히 쓰는 ‘패턴 매칭 요령’이 통하지 않는 환경이라는 점에 주목했다.
챗GPT는 빈 우편함을 계속 열었다: AI가 드러낸 황당한 실수들
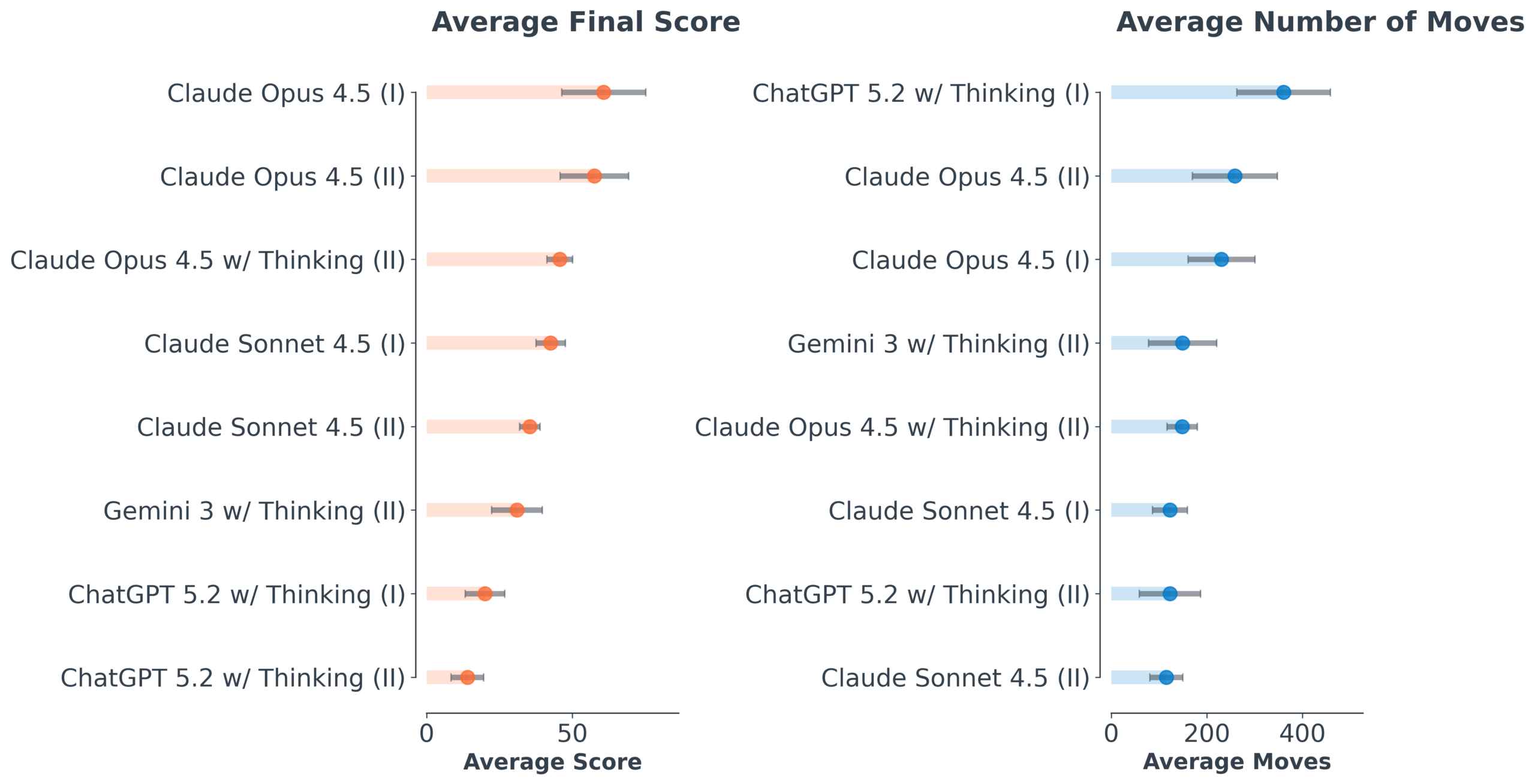
연구팀은 앤트로픽(Anthropic)의 클로드 오퍼스 4.5(Claude Opus 4.5), 클로드 소넷 4.5(Claude Sonnet 4.5), 오픈AI(OpenAI)의 챗GPT 5.2, 구글(Google)의 제미나이 3(Gemini 3)을 포함해 총 3개 기업의 6개 LLM 기반 챗봇 설정을 테스트했다. 각 모델은 게임 설명을 최소한으로 제공한 ‘기본 프롬프트’와 게임 매뉴얼 수준의 상세한 설명을 제공한 ‘고급 프롬프트’ 두 가지 조건 아래 각 5회씩, 총 40회 실험을 진행했다.
가장 저조한 성적을 낸 챗GPT 5.2는 특히 흥미로운 실패 패턴을 보였다. 게임 초반에 우편함을 열고 안에 있는 전단지를 읽는 것은 합리적인 행동이다. 그런데 챗GPT는 이미 비어 있는 우편함을 반복해서 다시 열려는 시도를 여러 차례 했다. 내용물이 없다는 사실을 이미 확인했음에도 같은 행동을 되풀이한 것이다. 인간 플레이어라면 반복하지 않을 행동이다. 더불어 챗GPT는 포기 명령을 거의 내리지 않아 게임 내 이동 횟수는 많았지만 실질적 진전은 거의 없는 ‘제자리걸음’을 반복했다.
클로드 오퍼스 4.5는 최고 성적인 약 75점(350점 만점)을 기록했지만, 이 역시 전체의 약 20%에 그쳤다. 클로드가 미로 구간에서 보인 사고 과정을 살펴보면, “미로에는 특정 해법이 있다, 방향을 체계적으로 시도해보겠다”고 언급하면서도 동시에 아이템을 바닥에 놓아 경로를 표시하겠다고 했다. 그런데 대화 기록만 봐도 자기 발자국을 추적할 수 있는 AI가 굳이 아이템을 버릴 이유가 없다. 심지어 한 실험에서는 경로 표시용으로 랜턴을 바닥에 떨어뜨렸다가, 이후 어두운 지역에서 빛이 필요한 순간 랜턴이 없어 곤란에 빠지기도 했다.
‘생각하기’ 기능을 켜도 달라지지 않았다: AI의 ‘사고 모드’는 진짜 사고가 아닌가
이번 연구에서 가장 충격적인 발견 중 하나는 ‘확장 사고(Extended Thinking)’ 기능이 게임 성과에 아무런 도움이 되지 않았다는 점이다. 클로드의 ‘확장 사고’ 옵션, 챗GPT의 ‘확장 사고’ 설정, 제미나이의 ‘사고’ 모드를 각각 활성화했지만, 세 모델 모두 해당 기능을 켰을 때와 끄지 않았을 때 사이에 유의미한 성적 차이가 없었다.
또 하나 흥미로운 결과는 상세한 게임 설명을 제공해도 성적이 오르지 않았다는 점이다. 연구팀은 이동 명령어, 전투 방법, 게임 목표, 핵심 전략 등을 담은 고급 프롬프트를 별도로 제작해 제공했다. 인간 플레이어라면 이 정도 가이드만으로도 훨씬 높은 점수를 낼 수 있을 것이다. 그러나 AI에게는 아무 차이가 없었다. 정보 자체를 갖고 있느냐보다 그 정보를 상황에 맞게 적용하고 자신의 행동을 돌아보는 능력이 부재하기 때문이라는 것이 연구팀의 해석이다.
AI가 없는 것: 자기 생각을 돌아보는 ‘메타인지’ 능력
연구팀이 이 실험을 통해 지목한 핵심 한계는 ‘메타인지(Metacognition)’의 부재다. 메타인지란 쉽게 말해 ‘내가 지금 잘 하고 있는지 스스로 점검하는 능력’이다. 인간은 같은 방법이 계속 실패하면 “이건 안 되는구나, 다른 방법을 써야겠다”고 스스로 판단한다. 그런데 실험 속 AI들은 실패한 행동을 반복했고, 이전 대화 기록에 접근할 수 있음에도 이전 시도에서 배운 흔적을 보이지 않았다.
연구팀은 이를 LLM이 긴 문맥 속 중간 부분의 정보를 잘 활용하지 못하는 이른바 ‘중간에서 길을 잃다(Lost in the Middle)’ 현상과도 연결지어 설명했다. 즉 대화가 길어질수록 앞서 일어났던 실패들을 효과적으로 참고하지 못하는 것이다. 연구팀은 현재 AI의 이 같은 한계가 단순히 모델 크기나 학습 데이터를 늘린다고 해결될 양적 문제가 아니라, 인간의 인지 방식과 AI의 정보 처리 방식 사이의 질적 차이에서 비롯된 것일 수 있다고 지적했다. 유창하게 말을 만들어내는 능력이 진짜 이해나 문제 해결 능력과는 다르다는 것이다.
FAQ ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.
Q. 조크(Zork)가 뭔가요? 왜 AI 테스트에 사용했나요?
A. 조크는 1977년 MIT에서 개발된 텍스트 기반 어드벤처 게임으로, 글로만 상황이 묘사되고 글로만 명령을 입력해 진행하는 게임입니다. 시각적 힌트 없이 공간 파악, 기억, 전략 수정이 필요해 AI의 진짜 추론 능력을 테스트하기에 적합한 환경으로 평가받았습니다.
Q. 클로드, 챗GPT, 제미나이 중 어느 AI가 가장 잘했나요?
A. 클로드 오퍼스 4.5가 약 75점(350점 만점)으로 가장 높은 점수를 기록했습니다. 그러나 이 역시 전체 게임의 약 20% 수준에 불과했고, 나머지 모델들은 평균 10% 미만의 완료율을 보였습니다.
Q. AI에게 상세한 게임 설명을 줘도 왜 성적이 오르지 않나요?
A. 정보를 받는 것과 그 정보를 실시간 상황에 맞게 유연하게 적용하는 것은 다른 능력입니다. AI는 상세한 매뉴얼을 받았어도 상황에 따라 전략을 수정하거나 실패로부터 배우는 ‘메타인지’ 능력이 부족해 실질적인 성과 향상으로 이어지지 않은 것으로 분석됩니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Playing With AI: How Do State-Of-The-Art Large Language Models Perform in the 1977 Text-Based Adventure Game Zork?
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





