
챗GPT에게 질문했다가 틀린 답변을 받아본 적 있을 것이다. 그때 드는 생각은 보통 하나다. “AI가 이것도 몰라?” 그런데 구글 리서치(Google Research) 연구팀이 발표한 최신 논문은 이 상식을 완전히 뒤집는다. AI가 틀리는 이유는 대부분 ‘몰라서’가 아니라 ‘알면서도 꺼내지 못해서’라는 것이다. GPT-5, 제미나이-3-프로(Gemini-3-Pro) 등 최첨단 AI 13개를 대상으로 약 450만 건의 응답을 분석한 결과다.
냉장고에 음식이 있는데 꺼내지 못하는 AI
연구팀은 AI가 사실을 틀릴 때 그 원인을 두 가지로 나눴다. 하나는 처음부터 그 정보를 학습하지 못한 경우, 즉 냉장고에 음식 자체가 없는 것이다. 연구팀은 이를 ‘빈 선반(empty shelves)’이라고 불렀다. 다른 하나는 정보가 분명히 저장되어 있는데 막상 질문을 받으면 꺼내지 못하는 경우, 즉 냉장고 안에 음식이 있는데 어디 뒀는지 찾지 못하는 것이다. 이를 ‘잃어버린 열쇠(lost keys)’라고 불렀다.
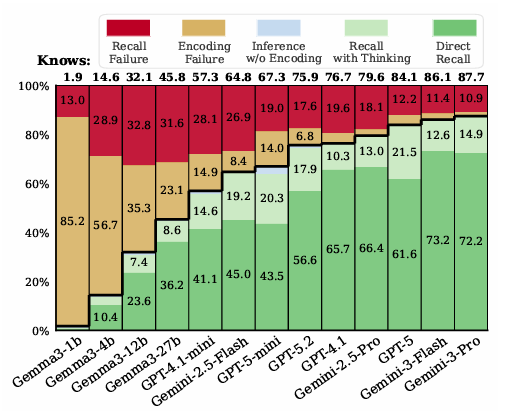
분석 결과는 놀라웠다. GPT-5와 제미나이-3-프로 같은 최첨단 모델들은 테스트에 등장한 사실의 95~98%를 이미 내부에 저장하고 있었다. 냉장고는 거의 꽉 차 있었던 것이다. 그런데도 추가 추론 없이는 25~33%의 질문에서 틀렸다. GPT-5.2 기준으로 오류의 70% 이상이 ‘몰라서’가 아니라 ‘꺼내지 못해서’ 발생했다. AI 모델을 더 크게 만들어도 이 문제는 잘 해결되지 않았다는 점도 함께 확인됐다.
AI가 앞에서 물어보면 맞히고, 뒤에서 물어보면 틀리는 이유
출력 실패는 특히 두 가지 상황에서 심하게 나타났다.
첫 번째는 덜 알려진 정보일수록 틀리는 문제다. 유명한 정보와 잘 알려지지 않은 정보를 비교했을 때, 저장된 비율은 거의 비슷했다. 제미나이-3-플래시(Gemini-3-Flash) 기준으로 인기 있는 정보는 99.5%, 희귀한 정보도 94.5%가 저장되어 있었다. 하지만 막상 답변할 수 있는 비율은 84.7% 대 63.3%로 격차가 21.4%포인트나 벌어졌다. 알고는 있는데, 잘 떠올리지 못하는 것이다. 기존에는 “AI가 희귀한 정보를 틀리는 건 애초에 배우지 못했기 때문”이라는 게 정설이었는데, 이번 연구가 그걸 뒤집었다.
두 번째는 질문 방향을 바꾸면 갑자기 틀리는 문제다. 예를 들어 AI에게 “오아시스(Oasis) 밴드가 처음 공연한 장소는?”이라고 물으면 “보드워크 클럽(Boardwalk Club)”이라고 잘 맞힌다. 그런데 “보드워크 클럽에서 처음 공연한 밴드는?”이라고 방향만 바꿔 물으면 같은 AI가 틀리는 경우가 많다. GPT-5 기준으로 정방향 질문은 82.9% 정답률이었지만, 역방향은 74%로 뚝 떨어졌다. 더 흥미로운 건, 보기를 주고 고르게 하면 역방향도 정방향만큼 잘 맞혔다는 점이다. AI는 분명히 알고 있다. 다만 질문 방향이 바뀌면 스스로 꺼내지 못할 뿐이다.
“잠깐, 생각해볼게요”가 실제로 효과가 있다
이 문제를 해결하는 데 도움이 되는 기능이 바로 ‘싱킹(thinking)’이다. AI가 즉각적으로 답변하지 않고 잠깐 멈춰서 단계별로 생각을 정리한 뒤 답하는 방식이다. 우리가 어떤 사실이 혀 끝에서 맴도는 느낌이 들 때, 관련된 기억을 하나씩 떠올리다 보면 결국 생각해내는 것과 비슷하다.
연구에 따르면 싱킹은 “저장은 되어 있지만 곧바로 답하지 못했던” 사실의 40~65%를 추가로 맞히게 해줬다. 반면 애초에 저장되지 않은 정보에 대해서는 싱킹을 써도 회수율이 5~20%에 그쳤다. 결국 싱킹은 없는 지식을 만들어내는 게 아니라, 있는 지식을 더 잘 꺼내도록 돕는 기능이라는 것이다. 특히 덜 알려진 정보나 역방향 질문처럼 AI가 가장 약한 부분에서 효과가 컸다. 제미나이-3-프로의 경우, 싱킹을 적용하자 희귀 정보와 인기 정보 사이의 답변 격차가 21.4%포인트에서 12.5%포인트로 줄었다.
물론 단점도 있다. 싱킹은 추가 연산이 필요해 응답이 느려지고 비용도 올라간다. 그리고 AI가 스스로 “지금 싱킹이 필요한 순간이다”를 판단하는 게 아직 완벽하지 않다는 점도 한계로 지적됐다.
AI의 ‘진짜 실력’을 재는 새로운 성적표
연구팀은 이번 연구를 위해 ‘위키프로파일(WikiProfile)’이라는 새로운 평가 도구도 만들었다. 기존 AI 평가 방식은 단순했다. 맞으면 1점, 틀리면 0점. 그런데 이 방식으로는 AI가 왜 틀렸는지 알 수 없다. 몰라서 틀렸는지, 알면서도 못 꺼냈는지 구분이 안 되는 것이다.
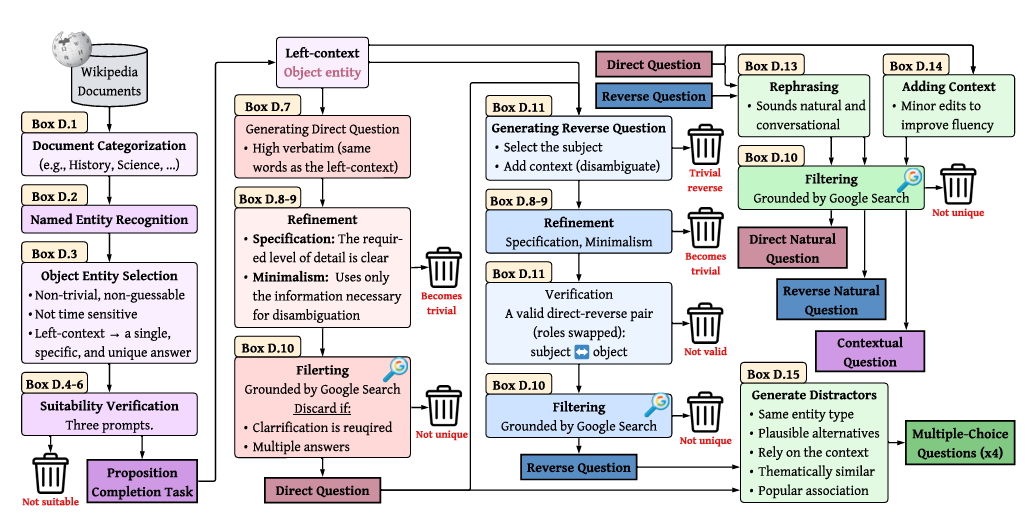
위키프로파일은 이 두 가지를 나눠서 측정할 수 있도록 설계됐다. 2,150개의 사실에 대해 각각 10개의 질문을 만들었는데, 정보가 저장됐는지 확인하는 질문, 실제로 답할 수 있는지 확인하는 질문, 객관식으로 골라낼 수 있는지 확인하는 질문이 모두 포함됐다. 모든 사실은 위키피디아(Wikipedia)에서 추출됐고, 구글 검색(Google Search)과 연동된 AI 파이프라인이 검증을 담당했다. 두 AI 채점자가 98.2%의 일치율을 보일 만큼 신뢰도도 높았다.
FAQ ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.
Q. AI가 사실을 틀리는 이유가 단순히 ‘모르기 때문’이 아닌가요?
A. 이번 연구에 따르면, GPT-5 같은 최신 모델들은 테스트된 사실의 95~98%를 이미 내부에 저장하고 있었습니다. 오류의 70% 이상은 지식이 없어서가 아니라, 저장된 정보를 제때 꺼내지 못해서 발생했습니다.
Q. AI의 ‘싱킹(thinking)’ 기능이 정확도를 높인다는데, 항상 켜두면 되나요?
A. 싱킹은 놓쳤던 답변의 40~65%를 추가로 맞힐 수 있어 효과적이지만, 응답이 느려지고 비용도 올라갑니다. AI가 스스로 “지금 싱킹이 필요하다”를 판단하는 능력도 아직 완벽하지 않아서, 현재로서는 상황에 따라 선택적으로 쓰는 편이 좋습니다.
Q. AI 모델 크기를 키우면 사실 오류 문제가 해결되지 않나요?
A. 모델을 크게 만들수록 정보를 저장하는 능력은 좋아집니다. 하지만 저장된 정보를 꺼내는 능력은 그만큼 따라오지 않았습니다. 연구팀은 앞으로의 AI 발전이 모델 크기보다 ‘이미 아는 것을 잘 꺼내는 방법’ 개선에 달려 있다고 봤습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Empty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





