
챗GPT가 작성한 코드인지, 클로드가 만든 코드인지 구별할 수 있을까? 최근 중국 쓰촨대학교 연구팀이 AI가 생성한 코드의 출처를 추적하는 기술을 개발해 주목받고 있다. 마치 필적 감정처럼 각 AI 모델이 남긴 ‘코딩 지문’을 분석해 누가 작성했는지 밝혀내는 이 기술은, AI 코드 생성이 보편화된 시대에 보안 사고와 저작권 분쟁을 해결할 새로운 열쇠가 될 전망이다.
91,804개 코드 샘플로 만든 세계 최초 AI 코드 추적 데이터셋
연구팀은 딥시크, 클로드, 큐원, 챗GPT 등 4개의 주요 AI 모델이 생성한 91,804개의 코드 샘플을 수집했다. 이는 Python, Java, C, Go 등 4개 프로그래밍 언어를 망라하며, 주석이 있는 버전과 없는 버전을 모두 포함한 대규모 데이터셋이다. 이 데이터셋은 AI 코드 출처 추적 연구를 위한 세계 최초의 공개 벤치마크로, 연구팀은 이를 통해 각 AI 모델이 코드를 작성할 때 남기는 독특한 패턴을 분석할 수 있었다.
흥미로운 점은 같은 프로그래밍 과제를 주더라도 AI 모델마다 미묘하게 다른 방식으로 코드를 작성한다는 사실이다. 마치 사람마다 글씨체가 다르듯, AI 모델도 각자의 ‘코딩 스타일’을 가지고 있다. 이는 각 모델이 학습한 데이터, 내부 구조, 그리고 코드를 생성하는 방식이 다르기 때문이다. 예를 들어 어떤 AI는 변수명을 짧게 짓는 경향이 있고, 다른 AI는 불필요한 라이브러리를 자주 불러오는 습관을 보인다.
“기능은 같지만 스타일은 다르다”…AI 코드의 이중성 발견
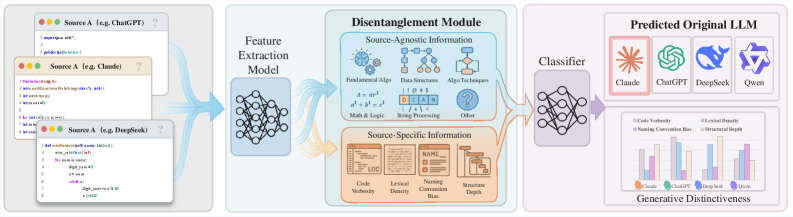
연구팀이 주목한 핵심은 AI가 생성한 코드에 두 가지 정보가 동시에 담겨 있다는 점이다. 첫 번째는 ‘출처와 무관한 정보(Source-Agnostic Information)’로, 프로그래밍 과제 자체가 요구하는 기능적 의미다. 예를 들어 “두 숫자를 더하는 함수”를 만들라고 하면, 어떤 AI든 덧셈 로직을 구현해야 한다. 두 번째는 ‘출처 특정 정보(Source-Specific Information)’로, 각 AI 모델만의 독특한 코딩 습관과 구조적 특징이다.
문제는 기존의 AI 코드 탐지 기술들이 이 두 가지를 구분하지 못했다는 것이다. 대부분의 방법은 “사람이 쓴 코드인가, AI가 쓴 코드인가”를 판별하는 데 집중했고, 여러 AI 중 누가 작성했는지까지 구별하지는 못했다. 이는 마치 “이 글씨가 손으로 쓴 것인지, 프린터로 출력한 것인지”는 알 수 있지만, “어떤 프린터 모델로 출력했는지”는 모르는 상황과 비슷하다.
연구팀은 논문의 방법론(Methodology) 섹션에서 이 문제를 해결하기 위해 ‘분리된 코드 출처 추적 네트워크(Disentangled Code Attribution Network, DCAN)’라는 새로운 시스템을 제안했다. 이 시스템은 코드에서 과제 자체의 의미와 AI 모델 특유의 스타일을 분리해낸다. 마치 요리에서 기본 레시피와 셰프만의 특별한 손맛을 구분하는 것처럼, 코드의 기능적 부분과 스타일적 부분을 나누어 분석하는 것이다.
보안 사고 발생 시 책임 소재 명확히…실용적 가치 주목
이 기술이 중요한 이유는 실제 소프트웨어 개발 현장에서 발생하는 문제들 때문이다. 최근 많은 개발자들이 챗GPT나 클로드 같은 AI를 활용해 코드를 작성하고 있다. 문제는 이렇게 만들어진 코드에서 보안 취약점이나 악성 로직이 발견됐을 때, 어떤 AI가 만들었는지 알 수 없다는 점이다. 또한 저작권 분쟁이나 라이선스 충돌이 발생했을 때도 코드의 출처를 밝혀야 책임 소재를 명확히 할 수 있다.
연구팀은 논문의 서론(Introduction)에서 이러한 상황을 ‘LLM 코드 출처 추적(LLMCSA)’ 문제로 정의했다. 이는 단순히 학술적 호기심이 아니라, 소프트웨어 거버넌스, 보안 책임성, 지적재산권 준수 등 실질적인 산업 문제를 해결하기 위한 것이다. 예를 들어 금융 앱에서 보안 결함이 발견됐을 때, 그 코드가 어떤 AI에서 나왔는지 알 수 있다면 해당 AI 제공업체에 책임을 물을 수 있고, 같은 AI로 만든 다른 코드들도 점검할 수 있다.
실험 결과는 고무적이었다. DCAN 시스템은 다양한 프로그래밍 언어와 상황에서 신뢰할 만한 출처 추적 성능을 보여줬다. 이는 AI가 생성한 코드에도 각 모델만의 ‘디지털 지문’이 존재하며, 이를 추적하는 것이 가능하다는 것을 입증한다. 마치 범죄 현장에서 지문을 채취해 용의자를 특정하듯, 코드에서도 생성 모델을 특정할 수 있게 된 것이다.
기존 방법론의 한계 극복…대조 학습으로 미묘한 차이 포착
기존의 코드 출처 추적 방법들은 크게 두 가지로 나뉜다. 하나는 ‘능동적 방법’으로, AI가 코드를 생성할 때 미리 워터마크를 심어놓는 것이다. 예를 들어 특정 유니코드 패턴을 삽입하거나, 문법적으로 불필요한 구조를 일부러 넣는 식이다. 하지만 이 방법은 AI 생성 과정에 직접 접근할 수 있어야 하므로, 이미 만들어진 코드를 분석하는 실제 상황에서는 사용할 수 없다.
다른 하나는 ‘수동적 방법’으로, 이미 생성된 코드만 보고 출처를 추적하는 것이다. 최근 연구들은 특정 프로그래밍 언어에서 나타나는 스타일 패턴을 분석하거나, 수작업으로 만든 특징들을 기계학습에 활용했다. 하지만 이런 접근은 언어마다 다시 특징을 설계해야 하고, 여러 언어에 범용적으로 적용하기 어렵다는 한계가 있었다.
연구팀의 DCAN은 이러한 한계를 극복했다. 대조 학습(Contrastive Learning)이라는 기법을 활용해, 같은 과제를 해결한 서로 다른 AI의 코드들을 비교하면서 각 모델 특유의 신호를 자동으로 추출한다. 이는 마치 쌍둥이의 미묘한 차이를 찾아내듯, 겉보기에 비슷해 보이는 코드들 사이의 미세한 스타일 차이를 포착하는 것이다. 중요한 점은 이 과정이 자동화되어 있어, 새로운 프로그래밍 언어나 AI 모델이 추가되어도 쉽게 확장할 수 있다는 것이다.
일상 속 AI 코드의 숨겨진 위험…추적 기술이 필수인 이유
일반인들에게는 낯설게 느껴질 수 있지만, AI가 생성한 코드는 이미 우리 일상 곳곳에 스며들어 있다. 스마트폰 앱, 온라인 쇼핑몰, 은행 시스템 등 많은 소프트웨어가 개발 과정에서 AI의 도움을 받는다. 문제는 이렇게 만들어진 코드가 항상 안전하다고 보장할 수 없다는 점이다.
예를 들어 의료 상담 앱의 코드 일부가 AI로 작성됐는데, 그 코드에 개인정보 유출 취약점이 있다고 가정해보자. 만약 어떤 AI가 그 코드를 만들었는지 알 수 있다면, 같은 AI로 만든 다른 의료 앱들도 즉시 점검할 수 있다. 또한 교육용 프로그래밍 플랫폼에서 학생들이 제출한 코드가 실제로 본인이 작성한 것인지, AI가 대신 만든 것인지 판별할 수도 있다.
연구팀이 관련 연구(Related Work) 섹션에서 언급했듯, 기존 연구들은 주로 “사람이 쓴 코드 vs AI가 쓴 코드”를 구분하는 데 집중했다. 하지만 실제 산업 현장에서는 “어떤 AI가 쓴 코드인가”를 아는 것이 더 중요한 경우가 많다. 이는 책임 추적, 품질 관리, 보안 감사 등 다양한 목적으로 활용될 수 있다. 투자 자문 앱이 잘못된 알고리즘으로 손실을 발생시켰을 때, 그 코드의 출처를 알면 법적 책임 소재를 명확히 할 수 있는 것처럼 말이다.
이번 연구는 AI 시대의 소프트웨어 개발에서 투명성과 책임성을 확보하는 첫걸음이다. 앞으로 AI가 더 많은 코드를 작성하게 될수록, 이러한 추적 기술의 중요성은 더욱 커질 것이다. 마치 식품에 원산지 표시가 의무화된 것처럼, AI가 생성한 코드에도 ‘제조사 표시’가 필요한 시대가 오고 있는 것이다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. AI가 작성한 코드와 사람이 작성한 코드는 어떻게 다른가요?
A. AI가 작성한 코드는 문법적으로는 정확하지만, 불필요한 라이브러리를 자주 불러오거나 특정 변수명 패턴을 반복하는 등 미묘한 스타일 차이가 있습니다. 또한 AI는 자신이 이전에 생성한 코드를 다시 작성할 때 스타일 변화가 적은 특징을 보입니다. 이러한 차이는 육안으로 구별하기 어렵지만, 기계학습 모델을 통해 감지할 수 있습니다.
Q. 이 기술이 실제로 어디에 사용될 수 있나요?
A. 보안 취약점이 발견됐을 때 원인 AI를 추적하거나, 저작권 분쟁 시 코드 출처를 증명하거나, 교육 현장에서 학생들의 과제 대필 여부를 판별하는 데 활용될 수 있습니다. 또한 기업이 특정 AI 서비스의 코드 품질을 평가하거나, 소프트웨어 감사 과정에서 AI 생성 코드의 비율을 파악하는 데도 유용합니다.
Q. 모든 AI 모델의 코드를 구별할 수 있나요?
A. 현재 연구는 DeepSeek, Claude, Qwen, ChatGPT 등 4개 주요 모델을 대상으로 했지만, 시스템 구조상 새로운 AI 모델이 추가되어도 확장이 가능합니다. 다만 AI 모델들이 계속 업데이트되면서 코딩 스타일이 변할 수 있으므로, 추적 시스템도 지속적으로 학습 데이터를 업데이트해야 정확도를 유지할 수 있습니다.
기사에 인용된 논문 원문은 arXiv에서 확인할 수 있다.
논문명: Code Fingerprints: Disentangled Attribution of LLM-Generated Code
이미지 출처: AI 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





