
Developing a 172B LLM with Strong Japanese Capabilities Using NVIDIA Megatron-LM
생성형 AI의 한계와 일본어 모델의 필요성
현재 상위권 언어모델들은 일본어를 포함한 비영어 언어에서 충분한 성능을 보여주지 못하고 있다. 대표적으로 GPT-3의 학습 데이터셋에서 일본어가 차지하는 비중은 0.11%에 불과하다.
일본 경제산업성(METI)은 자국의 플랫폼 모델 개발 역량을 높이고 기업들의 창의성을 촉진하기 위해 생성형 AI 액셀러레이터 챌린지(GENIAC)를 출범했다. GENIAC은 컴퓨팅 자원 제공, 기업 및 데이터 보유자와의 매칭 지원, 글로벌 기술 기업과의 협력 촉진, 커뮤니티 이벤트 개최, 개발된 플랫폼 모델의 성능 평가 등을 수행한다.
LLM-jp 프로젝트는 172B 파라미터를 가진 완전 개방형 모델(허깅페이스에서 이용 가능)을 개발하는 것을 목표로 GENIAC에 선정됐다. 이는 2024년 2월부터 8월 사이 일본 최대 규모의 모델 개발 프로젝트다. 주로 NII의 자연어 처리와 컴퓨터 시스템 분야 연구자들이 주도하는 LLM-jp는 대규모 모델이 일반화 성능을 획득하는 방식과 학습 효율성에 대한 수학적 원리를 규명하는 것을 목표로 한다.
NVIDIA 메가트론-LM을 활용한 모델 학습
메가트론-LM은 메가트론-코어를 활용하는 연구 지향적 프레임워크로, 전례 없는 속도로 LLM을 학습시킬 수 있다. 메가트론-코어는 GPU에 최적화된 기술과 최첨단 시스템 수준의 최적화를 포함하는 오픈소스 라이브러리다. 텐서, 시퀀스, 파이프라인, 컨텍스트, MoE 전문가 병렬 처리를 포함한 다양한 고급 모델 병렬화 기술을 지원한다.
특히 메가트론-코어는 빠른 분산 체크포인팅과 같은 학습 복원력 기능과 맘바(Mamba) 기반 하이브리드 모델 학습과 같은 혁신 기능을 제공한다. 모든 NVIDIA 텐서 코어 GPU와 호환되며, NVIDIA 호퍼 아키텍처에서 도입된 FP8 정밀도를 지원하는 트랜스포머 엔진(TE)을 지원한다.
혁신적인 모델 아키텍처와 학습 설정
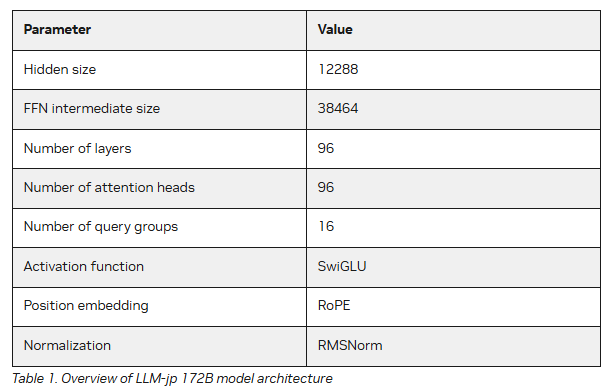
LLM-jp 172B 모델은 라마 2(Llama 2) 아키텍처를 따르며, 주요 사양으로는 히든 사이즈 12288, FFN 중간 사이즈 38464, 96개의 레이어와 어텐션 헤드를 포함한다. 모델의 주요 하이퍼파라미터 설정에는 학습률 1E-4, 최소 학습률 1E-5, 학습률 웜업 반복 횟수 2000, 가중치 감쇠 0.1, 그래디언트 클립 1.0, 전역 배치 크기 1728, 컨텍스트 길이 4096이 포함된다.
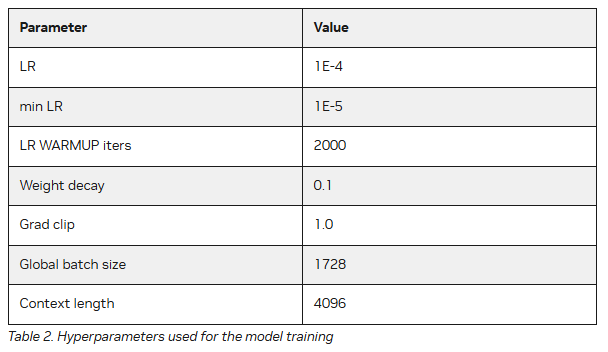
학습 과정의 안정성을 높이기 위해 PaLM에서 사용된 z-손실과 배치 건너뛰기 기법을 도입했으며, 학습 속도를 더욱 향상시키기 위해 플래시 어텐션을 사용했다. 이러한 설정의 자세한 내용은 llm-jp/Megatron-LM에서 확인할 수 있다. 학습에는 주로 일본어와 영어로 구성된 2.1조 개의 토큰이 사용됐으며, 구글 클라우드 A3 인스턴스의 NVIDIA H100 텐서 코어 GPU에서 FP8 하이브리드 훈련을 실시했다.
획기적인 학습 성과와 처리 속도 향상
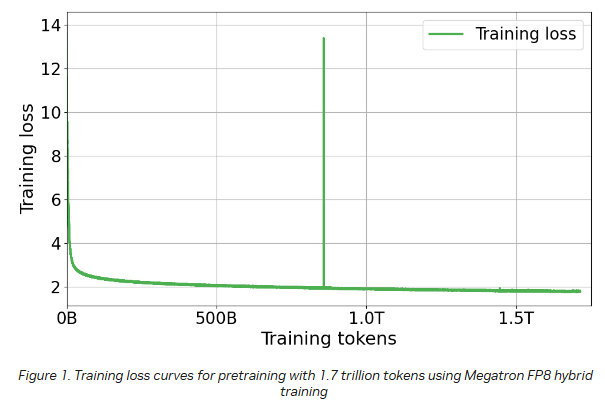
현재 모델 학습은 목표인 2.1조 토큰의 80% 이상이 완료됐다. 특히 주목할 만한 점은 약 7,000회 반복 이후 TFLOP/s가 급격히 증가했다는 것이다.
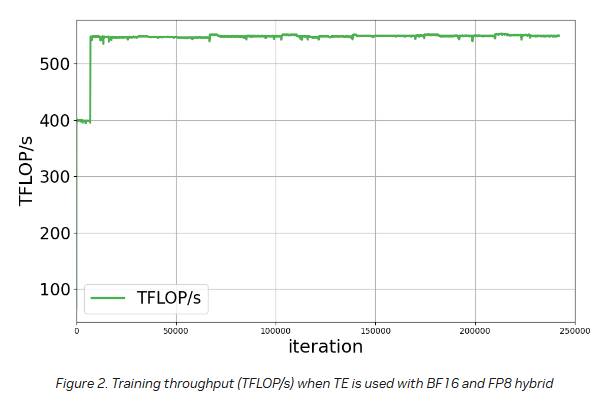
BF16에서 FP8 하이브리드 정밀도로 전환한 결과, 학습 속도가 400 TFLOP/s에서 550 TFLOP/s로 1.4배 향상됐다.
향후 전망
LLM-jp 172B 모델은 현재 체크포인트 데이터를 통한 평가에서도 우수한 일본어 처리 능력을 보여주고 있으며, 완성된 모델은 2025년 초에 공개될 예정이다. 대규모 LLM 사전학습에서 가장 큰 과제인 학습 시간을 메가트론-LM과 FP8 하이브리드 방식을 통해 효과적으로 단축했다는 점에서, 이번 프로젝트는 비영어권 언어 처리를 위한 대규모 언어모델 개발의 새로운 이정표가 될 것으로 기대된다.
기사에 인용된 리포트의 원문은 링크에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기







