
Data quality – vital to optimizing GenAI: NASCIO & EY Survey Report
생성형 AI 시대, 데이터 품질 관리가 더욱 중요해진다
전국주정보책임자협회(NASCIO)와 EY가 46개 주정부의 최고정보책임자(CIO)와 최고데이터책임자(CDO)를 대상으로 실시한 조사에 따르면, 응답자의 95%가 생성형 AI 도입이 데이터 관리의 중요성을 높일 것이라고 전망했다. 그러나 체계적인 데이터 품질 관리 프로그램을 갖춘 주정부는 22%에 불과한 것으로 나타났다.
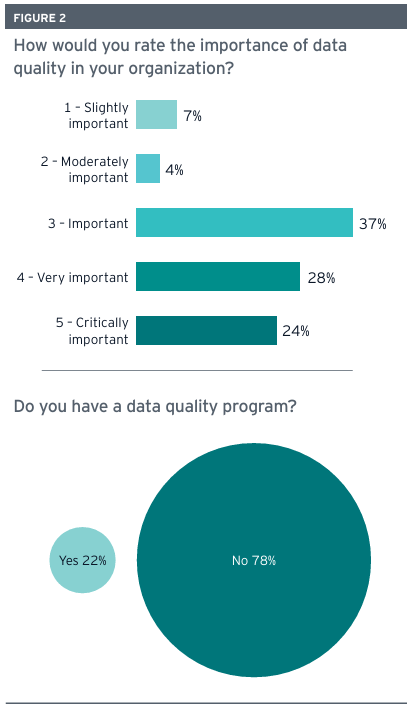
알라바마주의 대니얼 어카트(Daniel Urquhart) CIO는 “각 기관에서 생성형 AI에 대한 관심이 높지만, 생성형 AI의 잠재력은 기반이 되는 데이터의 무결성에 달려있다”고 지적했다. 알래스카주의 빌 스미스(Bill Smith) CIO는 “AI 애플리케이션을 위해 특별히 큐레이팅된 데이터셋을 만드는 방식으로 기초 데이터의 품질 문제를 우회하려는 유혹이 있다”며 우려를 표명했다.
AI 시대의 데이터 품질 관리, 7가지 핵심 고려사항
NASCIO는 AI 시대의 데이터 품질 관리를 위해 여러 핵심 요소를 제시했다. AI와 생성형 AI 솔루션의 신속한 개발과 배포를 위한 데이터 전략 수립이 우선시되어야 하며, 구조화 및 비구조화된 데이터 소스의 조직 지식을 통합하고 재구성하는 것이 중요하다. 또한 데이터 과학자와 AI/ML 엔지니어가 새로운 데이터 소스를 신속하게 발견하고 탐색할 수 있도록 지원하는 데이터 거버넌스 체계가 필요하다.
핵심 데이터셋의 단일 진실 공급원을 확보하는 것도 중요하며, 부정확하거나 관리가 미흡한 데이터로 인한 AI/생성형 AI 솔루션의 리스크를 감소시켜야 한다. 큐레이팅되고 검증된 데이터를 통한 AI 품질 보장도 필수적이며, 신속한 프로토타이핑과 대규모 AI 솔루션을 지원하는 데이터 아키텍처 구축이 요구된다.
데이터 품질 관리의 현주소와 과제
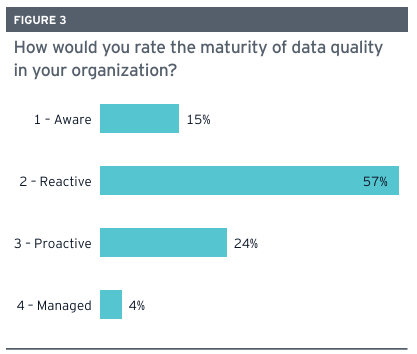
조사 결과, 주정부들의 데이터 품질 성숙도는 아직 초기 단계인 것으로 나타났다. 응답자의 57%가 자신들의 데이터 품질 성숙도를 ‘반응적’ 수준으로, 15%는 ‘인지’ 수준으로 평가했다. 이는 데이터 품질 원칙에 대한 이해 부족, 개선을 위한 공식 프로그램의 부재, 데이터 품질을 기술 부서의 책임으로만 여기는 경향을 반영한다.
예산과 정책 측면에서도 데이터 품질의 중요성과 실제 투자 간의 불일치가 두드러졌다. 대부분의 주정부가 데이터 품질을 중요하거나 매우 중요하다고 인식하지만, 예산 배정은 이러한 인식을 반영하지 못하고 있다.
데이터 전문인력 확보의 중요성
데이터 품질 관리를 위해서는 다양한 전문 인력이 필요하다. 데이터 라이프사이클 전반을 관리하는 데이터 스튜어드와 데이터 품질 문제를 식별, 분석, 해결하는 데이터 품질 분석가의 역할이 중요하다. 핵심 비즈니스 엔티티를 관리하는 마스터 데이터 관리 분석가와 데이터를 해석하고 비즈니스 의사결정을 지원하는 데이터 분석가도 필수적이다.
비즈니스 목표에 부합하는 IT 시스템을 설계하는 솔루션 아키텍트와 데이터 시각화 도구를 개발하는 대시보드 개발자, 데이터 파이프라인을 구축하고 유지보수하는 데이터 엔지니어도 중요한 역할을 담당한다.
데이터 거버넌스 운영 모델의 중요성
NASCIO는 데이터 거버넌스 운영 모델에 대한 스펙트럼을 제시했다. 분산형 모델에서는 개별 기관이 자신들의 특정 운영과 가장 관련성이 높은 데이터 품질 문제를 해결할 수 있고, 다양한 데이터 유형을 관리하는 전문성을 개발할 수 있다. 그러나 조직 전반에 걸친 일관된 데이터 품질 표준을 보장하기 어렵다는 단점이 있다.
유타주의 앨런 풀러(Alan Fuller) CIO는 이러한 과제를 직접 경험했다고 말했다. “유타주는 정부 서비스의 디지털 제공을 확대하려 노력하고 있으며, 데이터 프라이버시, 데이터 공유, 기관 간 협력을 통한 사회 문제 해결이라는 다른 과제도 안고 있다”고 설명했다.
인디애나주의 트레이시 반스(Tracy Barnes) CIO는 데이터 소유권 문제도 지적했다. “일부 기관은 자신들이 생성한 데이터를 자신들의 소유라고 여기며, 주정부 전체의 일부라는 인식이 부족하다”고 말했다.
향후 과제와 권고사항
NASCIO는 데이터 품질 향상을 위해 여러 권고사항을 제시했다. 우선 데이터 거버넌스 체계 구축과 운영 모델 수립이 필요하다. 이는 기업 전반의 데이터 품질을 다루고 사일로를 방지하기 위해 필수적이다. 데이터 거버넌스 프레임워크는 관리 위원회나 협의회, 데이터 스튜어드 네트워크의 지원을 받아 데이터 품질이 조직 전략의 핵심 고려사항이 되도록 해야 한다.
또한 주정부의 영향력과 가치에 기반한 데이터 자산 평가가 중요하다. 한정된 자원으로 인해 데이터 품질 사용 사례는 노력과 가치를 기준으로 평가되어야 하며, 이는 더 넓은 주정부 전략 이니셔티브와의 연계를 바탕으로 우선순위가 결정되어야 한다.
데이터 생성 시점부터 품질 표준을 적용하는 것도 중요하다. 이는 정확성과 일관성을 처음부터 보장하며, 나중에 비용이 많이 드는 수정의 필요성을 줄인다. 적절한 데이터 품질 관리 도구를 선택하고, 데이터 접근 및 보안 정책을 수립하며, 강력한 메타데이터 및 데이터 카탈로그 역량을 확보하는 것도 필수적이다.
모든 기술 수준의 데이터 실무자들 사이에서 더 높은 데이터 리터러시가 요구되며, 이는 데이터를 더 효과적으로 관리할 수 있게 한다. 마지막으로, 견고한 데이터 파이프라인을 구축하는 데 필요한 전문성과 도구를 확보하기 위해 데이터 엔지니어링 역량을 강화해야 한다.
기사에 인용된 리포트의 원문은 링크에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기







