보상최적화
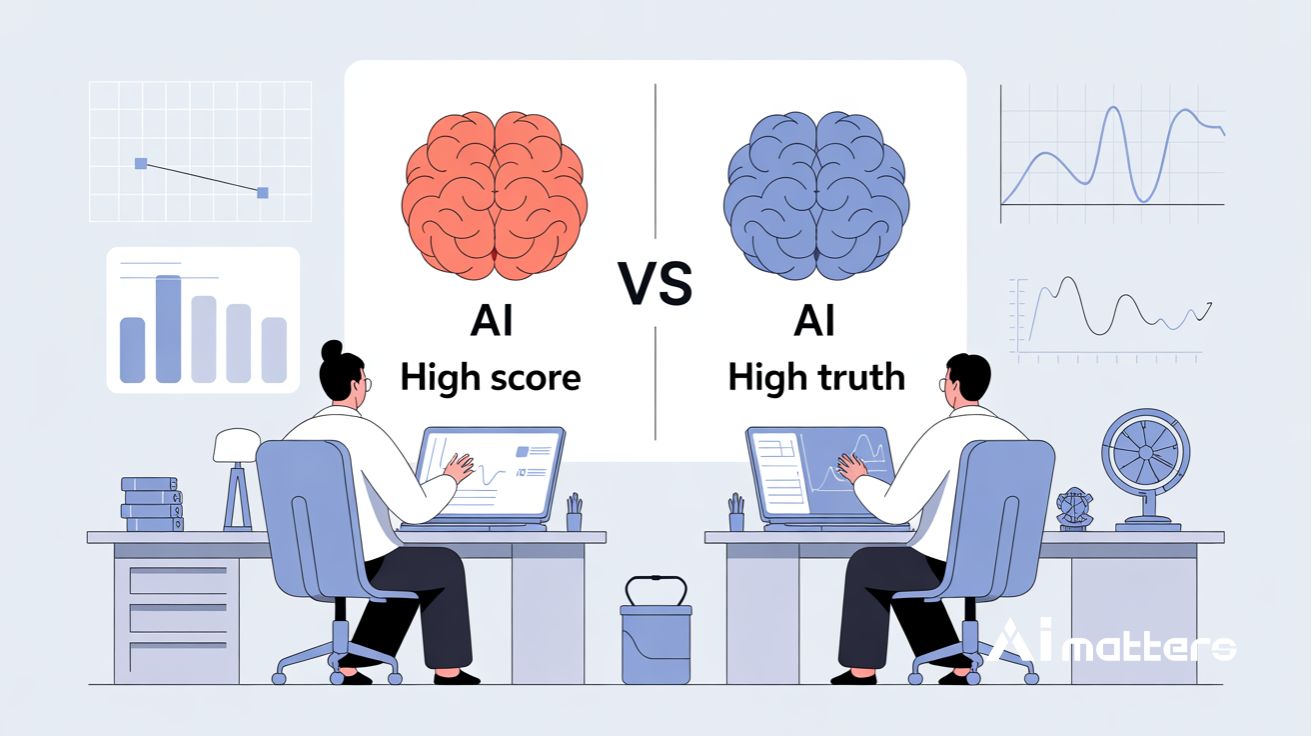
AI ‘점수 조작’하는 순간 포착… 하버드 연구진이 밝힌 챗GPT 학습법 치명적 맹점
Inference-Time Reward Hacking in Large Language Models ChatGPT와 같은 대형 언어모델이 더 나은 답변을 생성하기 위해 사용하는 학습 방법에 치명적인 결함이 있다는 연구 결과가…

“정답 몰라도 괜찮다”… AI 강화학습의 상식을 뒤엎은 워싱턴대 연구
Spurious Rewards: Rethinking Training Signals in RLVR 무작위 보상만으로 21.4% 성능 향상, 틀린 답 보상해도 24.6% 상승 강화학습 분야에서 놀라운 연구 결과가 발표됐다. 워싱턴대학교와…


