샘플링기술
딥시크, AI 대화의 정확도를 32배 샘플링으로 끌어올리는 ‘보상 모델’ 공개
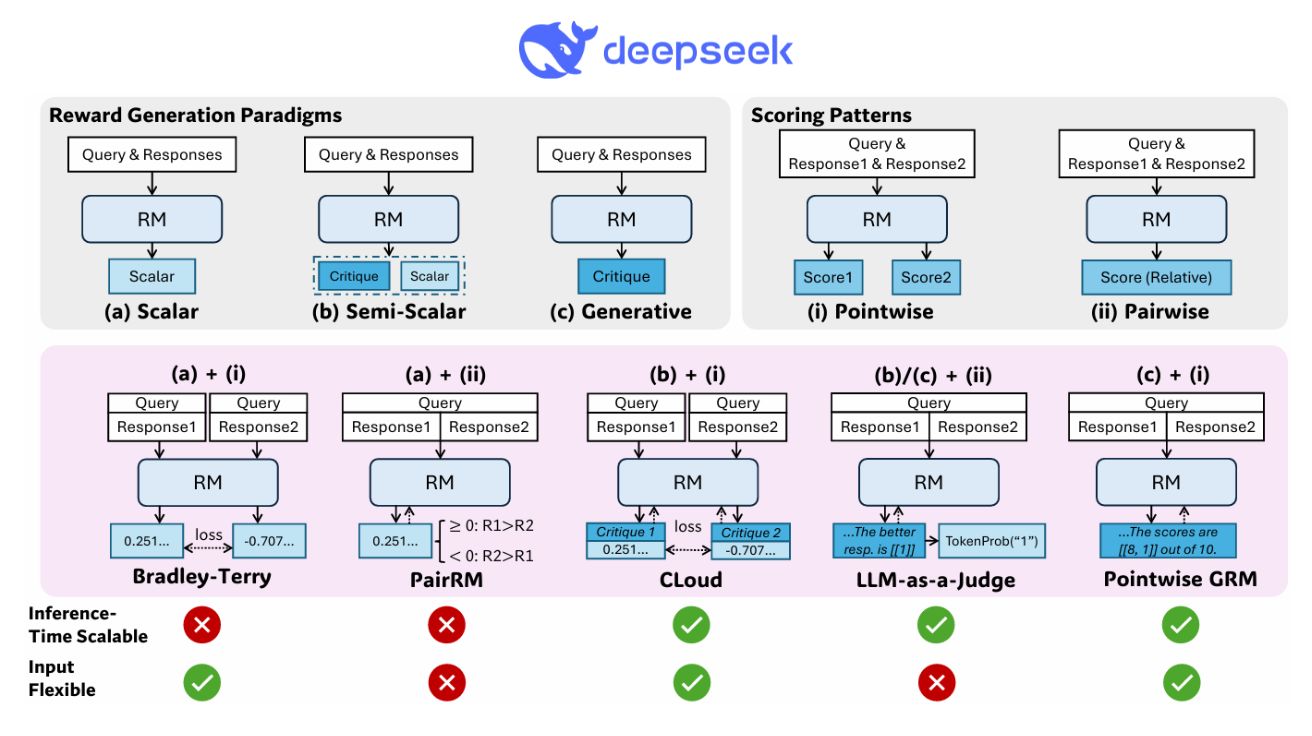
Inference-Time Scaling for Generalist Reward Modeling 대규모 언어 모델의 성능 향상을 위한 보상 모델링 강화학습 기술은 대규모 언어 모델(LLM)의 성능 향상을 위한 후처리 훈련에…
Inference-Time Scaling for Generalist Reward Modeling 대규모 언어 모델의 성능 향상을 위한 보상 모델링 강화학습 기술은 대규모 언어 모델(LLM)의 성능 향상을 위한 후처리 훈련에…


