AI투명성

오픈AI, 신형 AI 모델 ‘o3’ 성능 과장 논란……
오픈AI(OpenAI)의 o3 AI 모델에 대한 자체 벤치마크 결과와 제3자 벤치마크 결과 간의 불일치가 회사의 투명성과 모델 테스트 관행에…

구글, ‘제미나이 2.5 프로’ 안전성 보고서에 핵심 정보…
테크크런치가 17일(현지 시간) 보도한 내용에 따르면, 구글(Google)이 자사의 가장 강력한 AI 모델인 제미나이(Gemini) 2.5 프로 출시 몇 주…
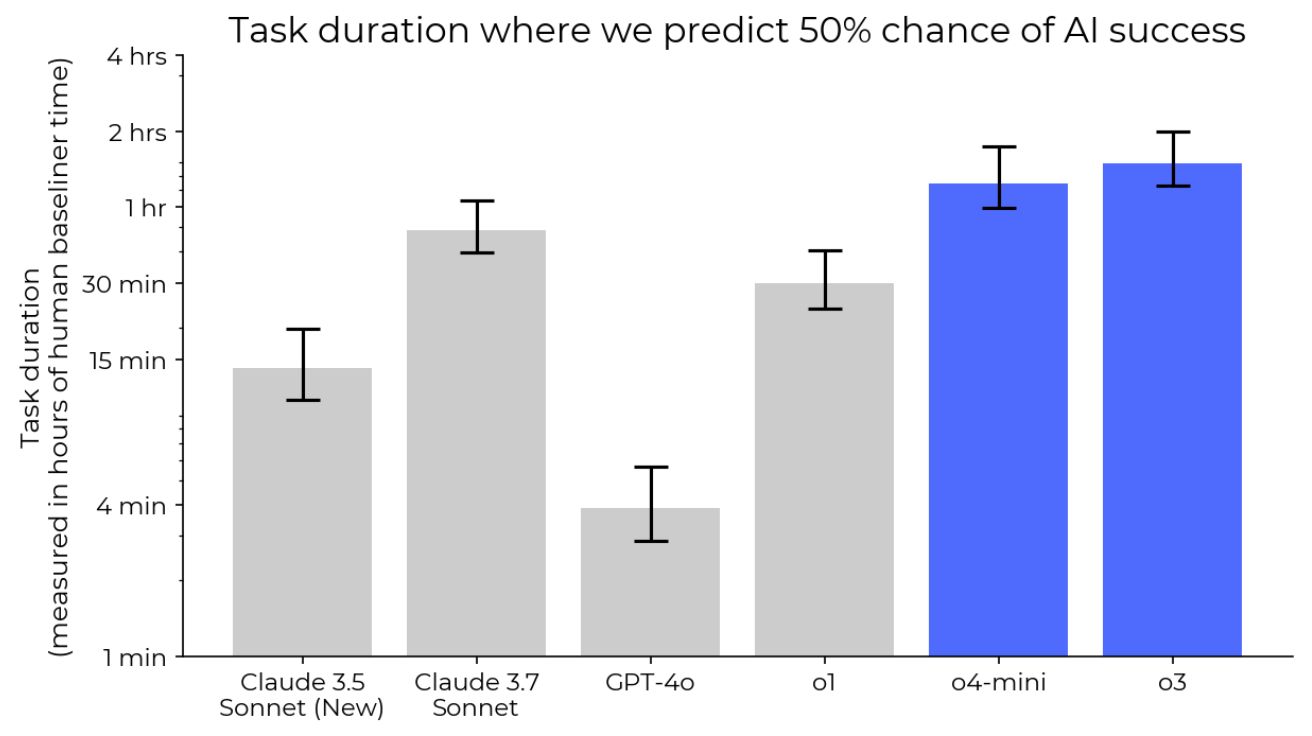
오픈AI, 신모델 ‘o3’ 사전 안전 검증 시간 부족해……
오픈AI(OpenAI)가 자사의 새로운 고성능 AI 모델인 o3의 테스트를 위해 파트너 기관에 충분한 시간을 제공하지 않았다는 주장이 제기됐다. 테크크런치가…

오픈AI, 안전성 보고서 없이 GPT-4.1 출시… 투명성 후퇴…
오픈AI(OpenAI)가 새로운 AI 모델 시리즈인 GPT-4.1을 출시하면서 안전성 보고서 없이 진행해 논란이 일고 있다. 특히 최근 AI 업계의…

메타, AI 모델 ‘매버릭’ 벤치마크 결과 논란…“공개 버전과…
테크크런치(TechCrunch)가 6일(현지 시간) 보도한 내용에 따르면, 메타(Meta)의 최신 AI 모델 벤치마크 결과에 대한 논란이 일고 있다. 메타가 공개…

구글, AI 안전성 검증 없이 제미나이 모델 출시…
구글(Google)이 인공지능(AI) 모델 출시 속도를 대폭 높이면서 안전성 보고서는 뒤로 미루고 있어 업계 우려가 커지고 있다. 테크크런치(TechCrunch)는 지난…

AI의 사고 회로 최초 공개: 앤트로픽, 클로드의 ‘머릿속’을…
Tracing the thoughts of a large language model 뇌과학에서 영감 받은 ‘AI 현미경’: 클로드의 사고를 수십억 계산에서 추적해내다…

“AI가 내 글 훔쳤나?” 내 글이 AI 모델에…
Is My Text in Your AI Model? Gradient-based Membership Inference Test applied to LLMs AI 모델 학습에 사용된…

당신의 AI는 진짜 당신의 뜻대로 움직일까? 앤트로픽, 숨겨진…
AUDITING LANGUAGE MODELS FOR HIDDEN OBJECTIVES AI의 이중생활: 표면적 순응 속 숨겨진 ‘보상 모델 아첨’ 목표 발견 인공지능(AI)이…

앤트로픽, 바이든 때의 ‘백악관 AI 자발적 약속’ 기록…
앤트로픽(Anthropic)이 자사 웹사이트 ‘투명성 허브(Transparency Hub)’에서 백악관의 AI 자발적 약속 관련 내용을 삭제해 논란이 일고 있다. 이에 대해…