AI모델비교

AI에게 배달 시켰더니 돈 다 써서 스쿠터만 샀다… 가상 도시 실험의 충격적 결과
샌디에이고 캘리포니아대학교와 존스홉킨스대학교 등 8개 대학 연구팀이 챗GPT, 클로드 같은 AI를 가상 세계에서 훈련하고 테스트할 수 있는 새로운 시뮬레이터 ‘심월드(SimWorld)’를 공개했다. 해당 논문에 따르면,…
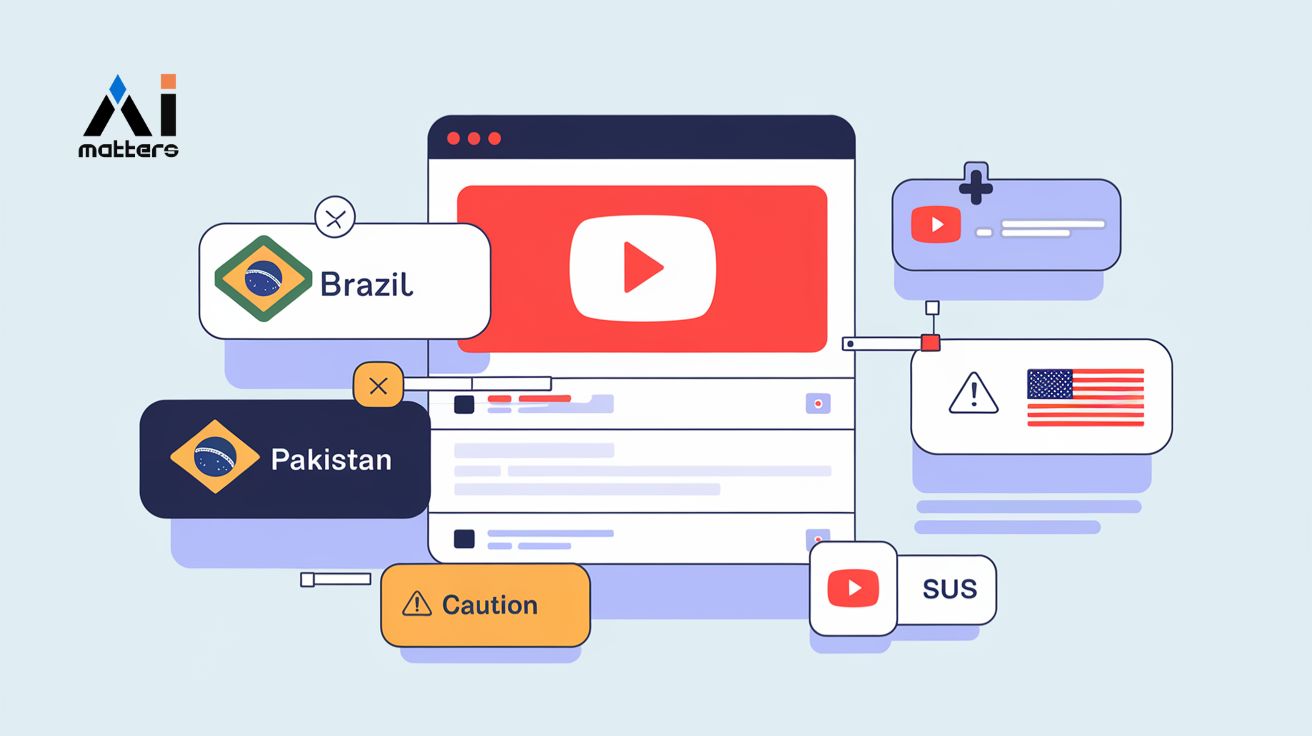
유튜브 썸네일 어그로 시대 끝나나? AI가 유해 썸네일 94% 정확도로 찾는다
인공지능을 활용한 가짜 썸네일 탐지 연구에서 클로드 3.5 소네트가 기존 전문 시스템보다 뛰어난 성과를 보였다. 이때 가짜 썸네일은 내용에 비해 썸네일이 과장되거나 거짓 약속을…
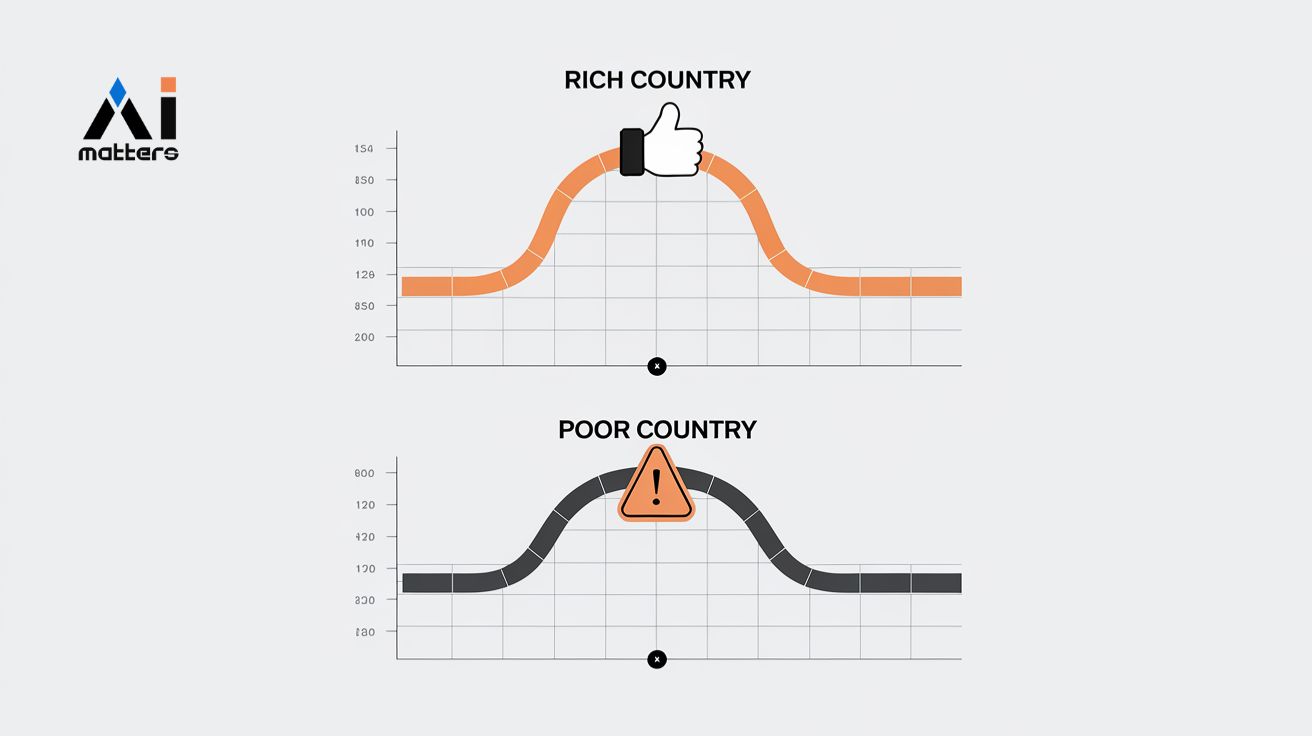
AI 눈에는 스위스가 천국, 남수단이 지옥? 똑같은 데이터, 다른 평가… AI 속 숨겨진 국가 차별
인공지능이 차트를 해석할 때 국가의 경제적 지위에 따라 다른 평가를 내린다는 연구 결과가 나왔다. 캐나다 요크대학교와 알버타대학교 등 국제 공동 연구진은 GPT-4o-mini, 제미나이 1.5-Flash…
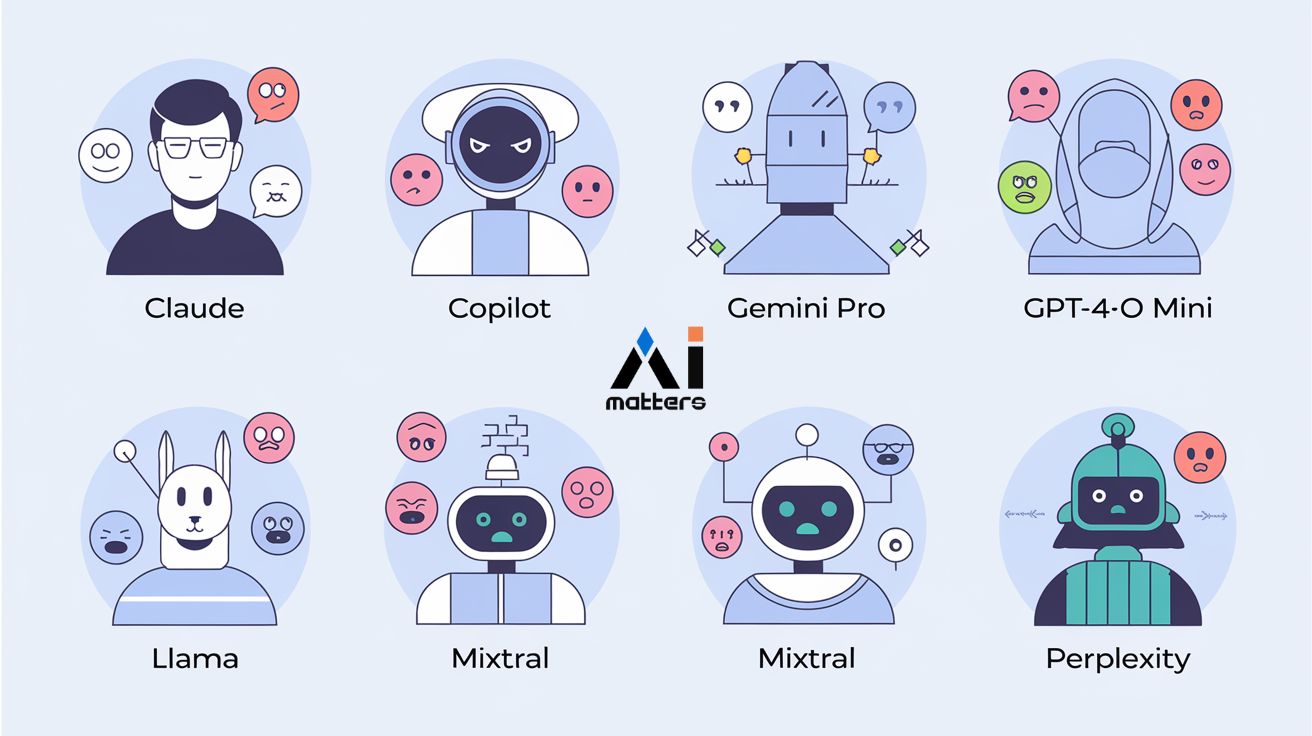
“챗GPT는 중립적이고, 라마는 낙관적”… AI마다 다른 ‘감정 DNA’ 분석
이란 테헤란대학의 아리아 바라스테네자드(Arya Varastehnezhad) 연구원과 미국 사우스캐롤라이나대학의 레자 타바솔리(Reza Tavasoli) 교수 등 5명의 국제 연구팀이 AI 모델들의 감정 표현을 본격 분석한 결과를 발표했다.…
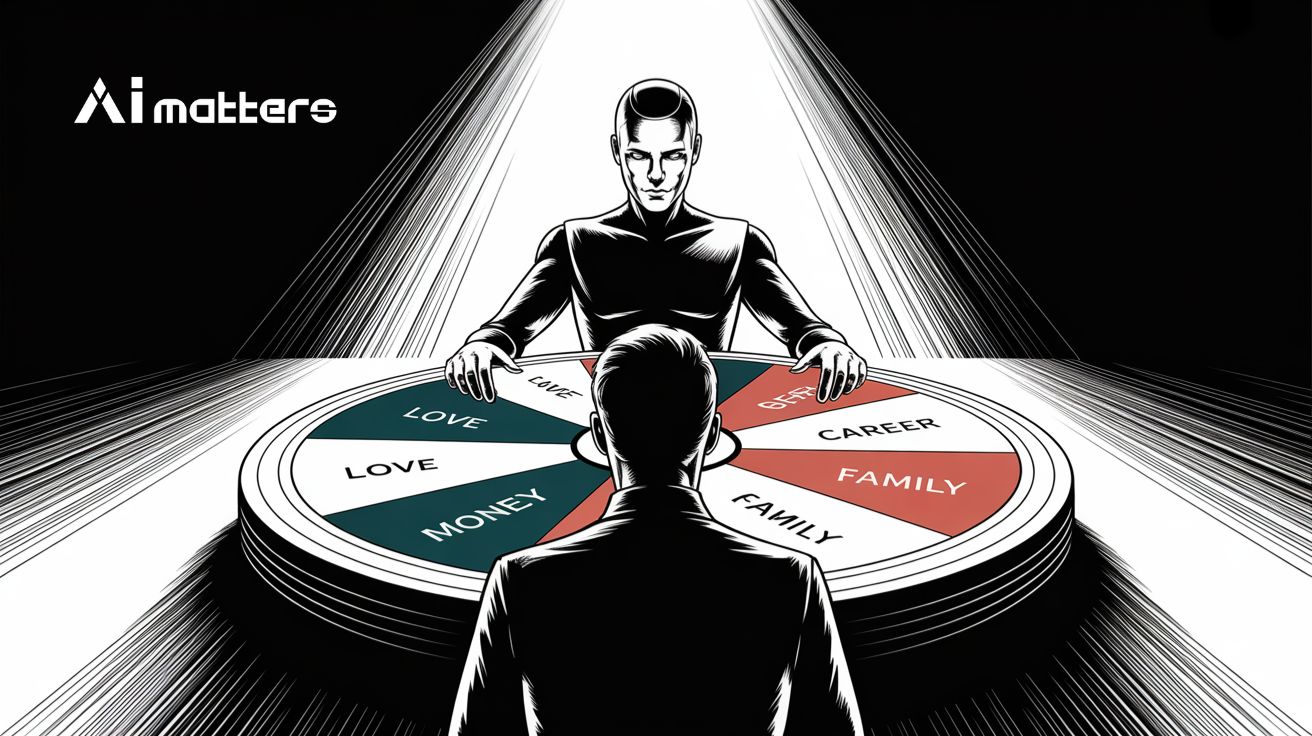
“AI한테 투자·연애·이직 상담해도 될까?”… 어떤 모델이 가장 상담 잘하나 봤더니
요즘 많은 사람들이 중요한 인생 결정을 할 때 AI에게 조언을 구한다. 하지만 과연 AI를 믿어도 될까? 싱가포르의 난양이공대학 연구진은 이별, 이직, 투자 등 100가지…

챗GPT, 알고 보니 ‘서구 문화’만 편애한다… “일본 문화는 모든 AI가 이해 포기”
독일 트리어 대학교 전산언어학과 사이먼 뮌커(Simon Münker) 박사가 이끄는 연구팀이 충격적인 사실을 발견했다. 챗GPT와 같은 AI가 다양한 나라의 문화를 제대로 이해하지 못한다는 것이다. 해당…

“이제 인간과 구별 불가”… 인간 글과 100% 똑같아진 AI ‘LLaDA’ 등장
터키 대학교 연구팀이 충격적인 사실을 발견했다. ‘LLaDA’라는 새로운 AI가 인간이 쓴 글과 구별할 수 없을 정도로 자연스러운 글을 쓸 수 있다는 것이다. 연구진은 2,000개의…

이제 번역도 잘 되길… SKT, 세계 최고 한국어 AI 모델 ‘에이닷 엑스 4.0’ 오픈소스 공개
SK텔레콤이 세계 최고 수준의 한국어 처리 능력을 보유한 대규모 언어 모델(LLM) ‘에이닷 엑스(A.X) 4.0’을 오픈소스로 공개했다고 3일(한국 시간) 발표했다. SK텔레콤은 이날 오전 세계적인 오픈소스…

“감정은 이해·촉각과 후각은 이해 못해” LLM의 감각에 대한 연구 결과 공개
Large language models without grounding recover non-sensorimotor but not sensorimotor features of human concepts GPT-4와 제미나이(Gemini) 같은 거대언어모델(LLM)들이 감각-운동 경험 없이도 감정이나 추상적 개념에서는…

그록 3 vs 챗GPT, AI 모델 성능 비교 분석해봤더니… 의외의 결과 충격
Grok 3 vs ChatGPT: We Compared The Two AI Models and Here Are The Results 그록 3의 수학적 추론 능력, 챗GPT보다 14% 우수 그록…

오픈AI, 신형 AI 모델 ‘o3’ 성능 과장 논란… 측정 기준 차이 드러나
오픈AI(OpenAI)의 o3 AI 모델에 대한 자체 벤치마크 결과와 제3자 벤치마크 결과 간의 불일치가 회사의 투명성과 모델 테스트 관행에 대한 의문을 제기하고 있다. 테크크런치가 20일(현지…

오픈AI, AI 추론 모델 ‘o3’·’o4-mini’ 발표… 이미지 기반 사고 가능해져
오픈AI(OpenAI)가 16일(현지 시간) 기존보다 더 똑똑하고 강력한 성능을 갖춘 최신 AI 모델인 ‘o3’와 ‘o4-mini’를 출시했다. 이번에 공개된 모델들은 더 오래 생각한 후 응답하도록 훈련된…
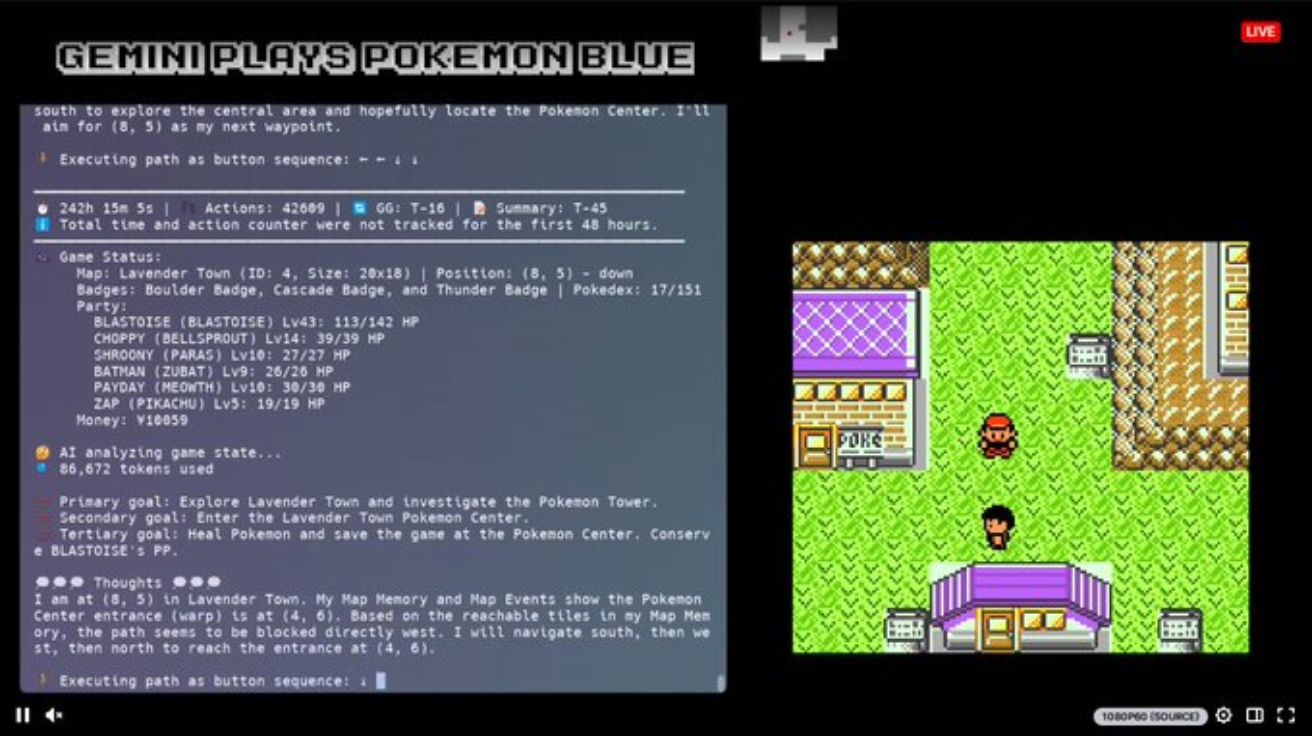
구글 vs 앤트로픽, AI 벤치마크 경쟁 ‘포켓몬’까지 확산… “공정한 비교가 가능할까?”
구글(Google)의 제미나이(Gemini)와 앤트로픽(Anthropic)의 클로드(Claude) AI 모델이 포켓몬 게임에서 경쟁하고 있다. 이처럼 AI 벤치마킹 논쟁은 이제 게임 세계까지 확장됐다. 지난주 X에서 한 게시물이 바이럴 현상을…

메타, AI 모델 ‘매버릭’ 벤치마크 결과 논란…“공개 버전과 달라”
테크크런치(TechCrunch)가 6일(현지 시간) 보도한 내용에 따르면, 메타(Meta)의 최신 AI 모델 벤치마크 결과에 대한 논란이 일고 있다. 메타가 공개 버전과 다른 ‘최적화된’ 버전으로 성능 측정을…

AI끼리 ‘마피아 게임’ 시켰더니… 클로드 3.7 소넷 ‘사고모드’가 승률 1위
대규모 언어 모델(LLM)들이 마피아 게임에서 대결을 펼치는 프로젝트가 공개됐다. 구저스(Guzus)라는 개발자가 공개한 이 프로젝트는 여러 AI 모델들이 마피아 게임에서 어떻게 경쟁하는지 보여주며, 최근 경쟁…

대형 AI 모델의 시대, 소형 모델의 역할은 끝났나?
What is the Role of Small Models in the LLM Era: A Survey 영국 임페리얼 칼리지 런던과 프랑스 소다 연구소가 발표한 연구에 따르면, 거대언어모델(LLM)이…

오픈소스 최초 멀티모달 MoE 모델 ‘ARIA’ 공개…GPT-4와 성능 경쟁
Rhymes AI가 개발한 ARIA가 오픈소스 최초의 멀티모달 네이티브 MoE(Mixture-of-Experts) 모델로 공개되었다. ARIA는 GPT-4와 Gemini-1.5와 같은 기업 독점 모델들과 견줄만한 성능을 보여주며 주목받고 있는데, 특히…


