AI실험

메타, 기존 통념 뒤집는 연구 결과 공개… “추론 시간 짧으면 LLM 정확도 34.5% 향상”
Don’t Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning 기존 통념을 뒤집는 발견: 짧은 추론이 34.5% 더 정확 복잡한 수학 문제를 해결하는…

“정답 몰라도 괜찮다”… AI 강화학습의 상식을 뒤엎은 워싱턴대 연구
Spurious Rewards: Rethinking Training Signals in RLVR 무작위 보상만으로 21.4% 성능 향상, 틀린 답 보상해도 24.6% 상승 강화학습 분야에서 놀라운 연구 결과가 발표됐다. 워싱턴대학교와…
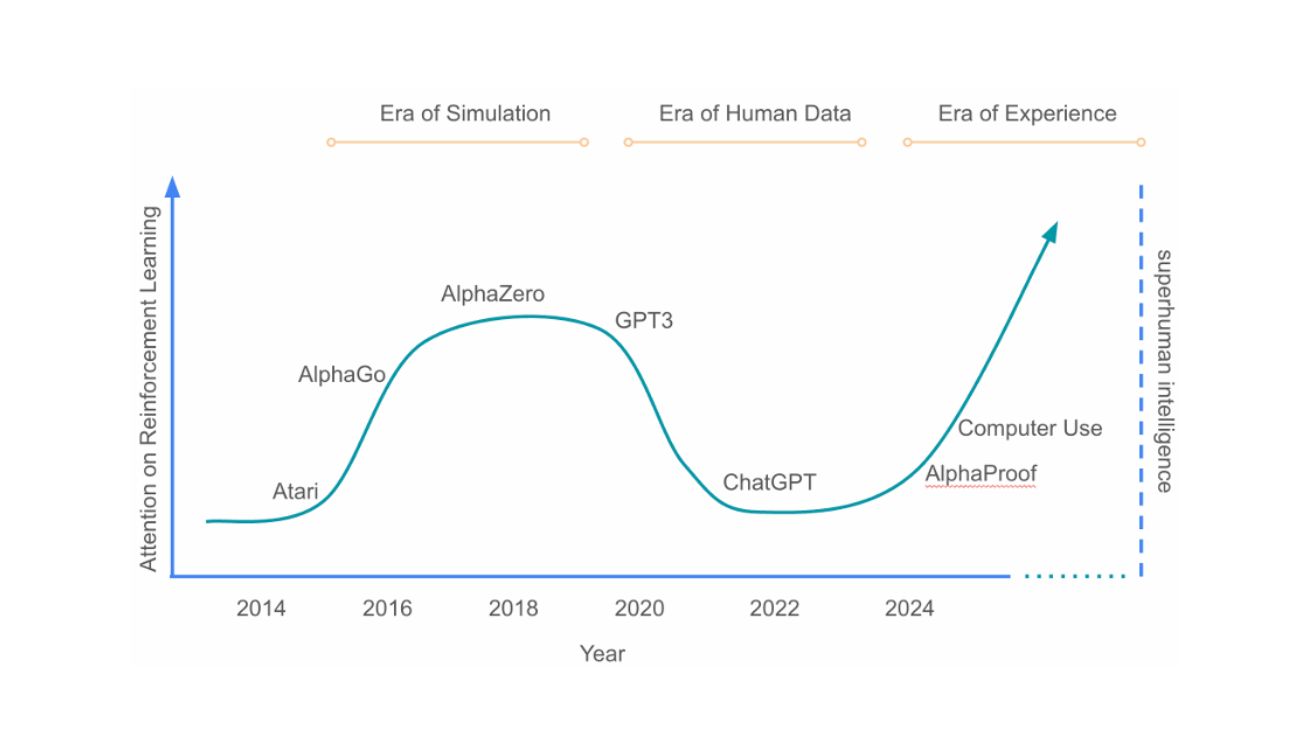
“AI, 이제 인간 지식을 넘는다”… 전문가들이 극찬한 ‘경험의 시대’ 논문이 예고하는 미래
Welcome to the Era of Experience 인간 데이터의 한계? 고품질 데이터 소스 고갈로 AI 발전 둔화 인공지능(AI) 기술은 현재 중요한 변곡점에 도달했다. 지금까지 대형…


