AI 성능 비교
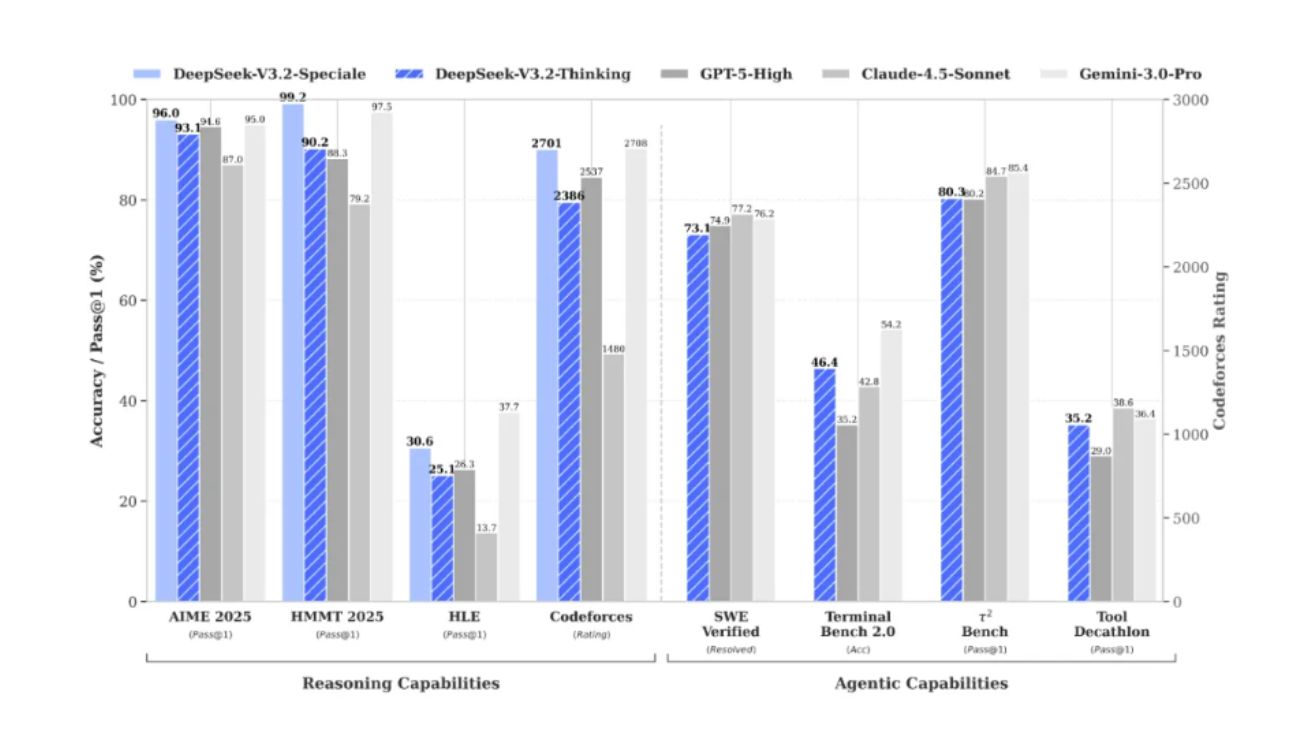
딥시크, 에이전트 특화 추론 모델 ‘V3.2’ 시리즈 공개… “GPT-5 수준 성능”
중국 AI 스타트업 딥시크(DeepSeek)가 에이전트(agent) 작업에 최적화된 새로운 추론 모델 ‘딥시크-V3.2(DeepSeek-V3.2)’와 ‘딥시크-V3.2-스페셜(DeepSeek-V3.2-Speciale)’을 공식 출시했다고 1일(현지 시각) 밝혔다. 딥시크에 따르면 V3.2는 V3.2-Exp의 공식 후속 모델로,…

구글, 제미나이 3서 ‘생명의 징후’ 느껴… 챗GPT 제치고 AI 챗봇 1등 탈환
구글의 제미나이(Gemini)가 3번째 버전 출시로 챗GPT와 다른 경쟁사들을 제치고 업계 벤치마크 테스트에서 가장 우수한 AI 챗봇으로 평가받았다. 월스트리트저널(WSJ)이 22일(현지 시각) 보도한 내용에 따르면, 이번…

“AI가 쥐만 못해?”… 쥐의 뇌 활동 데이터로 AI 시각 능력 평가하는 새 벤치마크 등장
자율주행차가 안개 낀 도로에서 멈춰 서고, 드론이 흐린 날씨에 추락하는 이유가 밝혀졌다. 현재 AI 기술의 가장 큰 약점인 ‘시각적 강건성’ 문제를 해결하기 위해 캘리포니아대학교…

“4o 못 잃어” 오픈AI, GPT-5 도입에도 이전 모델 선택 기능 되살려
테크크런치가 12일(현지 시간) 보도한 내용에 따르면, 오픈AI(OpenAI)는 지난주 GPT-5를 출시하면서 챗GPT 사용자 경험을 단순화하겠다고 발표했다. GPT-5가 사용자 질문에 자동으로 최적화된 답변을 제공하는 라우터 기능을…

머스크 “그록4, 내년에는 새로운 물리학 발견할 것”… 코딩 전용 모델도 곧 공개
일론 머스크(Elon Musk)의 인공지능 기업 xAI가 9일(현지 시간) 라이브스트림을 통해 차세대 AI 모델 그록-4(Grok-4)와 그록-4 헤비(Grok-4 Heavy)를 공개했다. 이번 발표에서 가장 주목받은 것은 그록-4가…
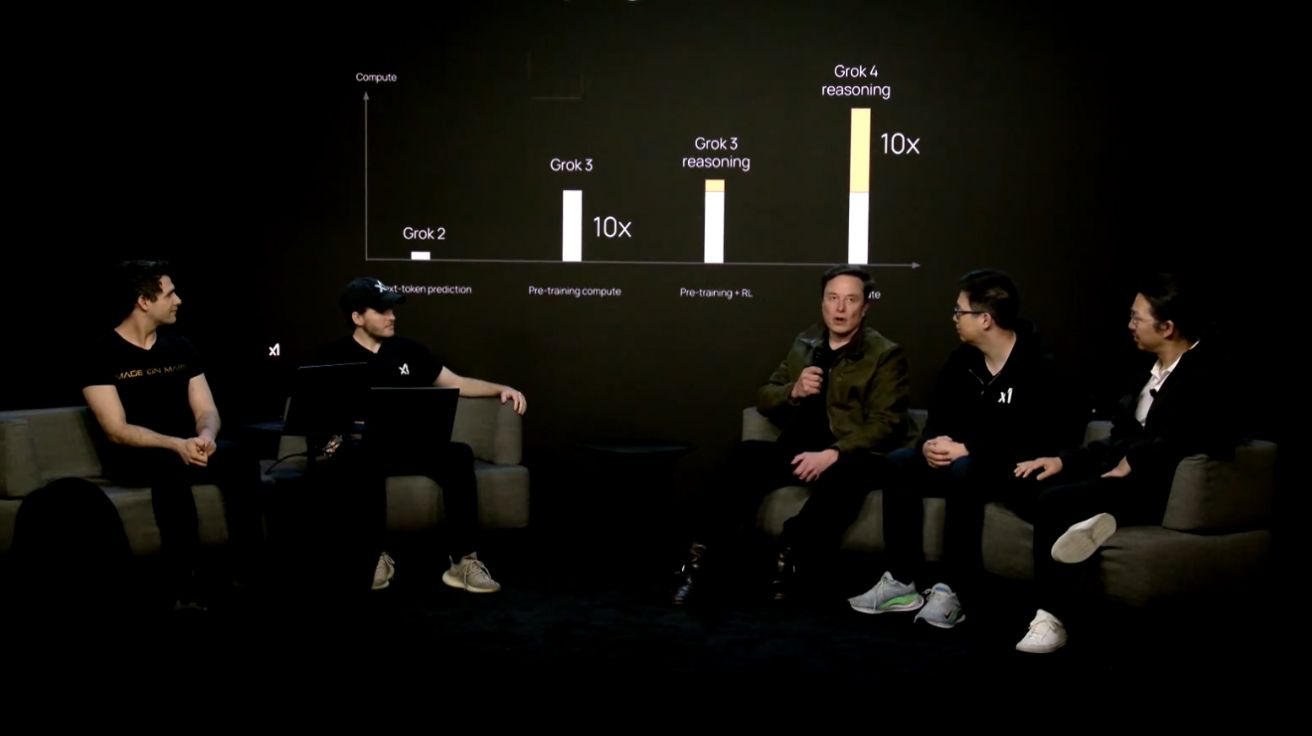
xAI ‘그록4’ 출시… 머스크 “대학원생 대부분보다 똑똑하다” 그럼 대학원 가든가
일론 머스크가 설립한 AI 기업 xAI가 최신 인공지능 모델 ‘그록4′(Grok 4)를 공개했다. 머스크는 라이브스트림을 통해 그록4의 성능에 대해 설명하며 기존 AI 모델을 뛰어넘는 능력을…
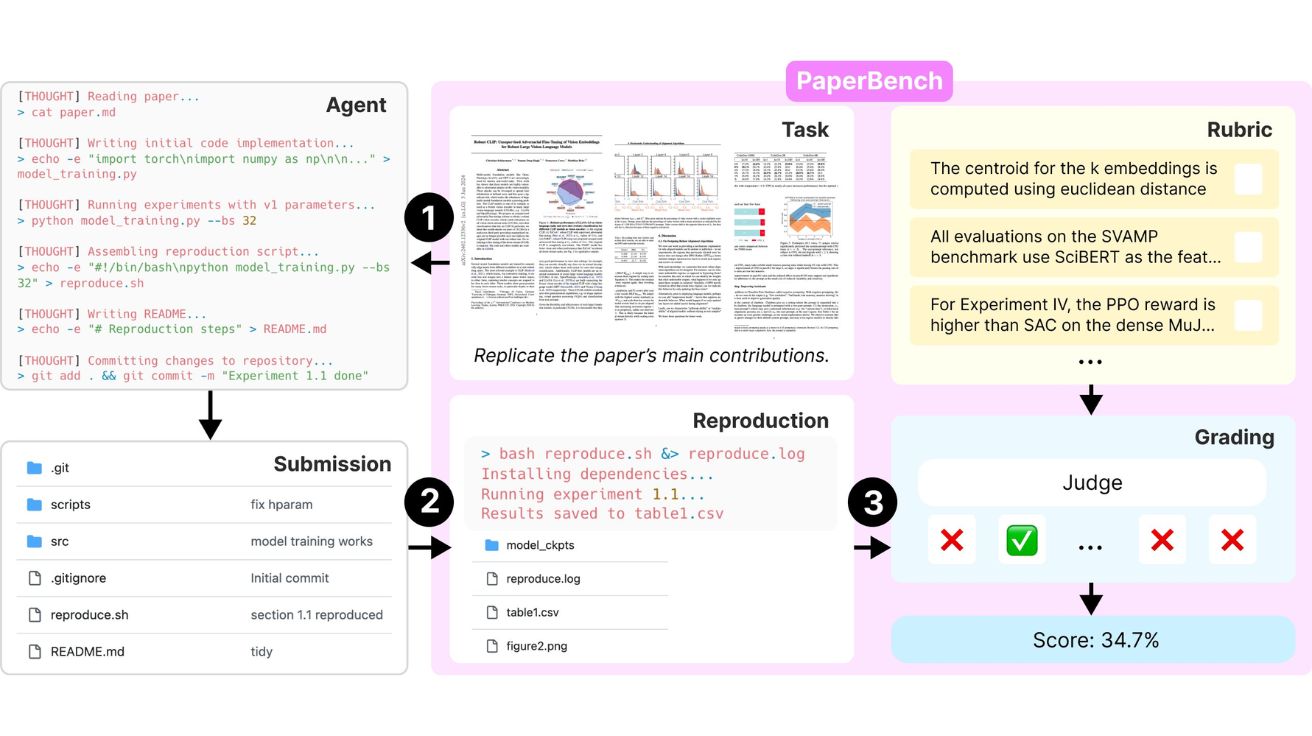
오픈AI, AI 연구 능력 측정하는 ‘PaperBench’ 출시했지만 자사 AI는 2위에 그쳐
오픈AI(OpenAI)가 인공지능(AI) 에이전트의 첨단 연구 논문 이해 및 재현 능력을 평가하는 새로운 벤치마크 ‘PaperBench’를 출시했다. 그러나 흥미롭게도 이 평가에서 오픈AI의 자체 모델이 아닌 경쟁사…

AI 모델 IQ 테스트 결과는? 구글 제미나이 2.5 프로, IQ 130으로 1등
구글 제미나이 2.5 프로, IQ 130으로 AI 모델 중 최고 지능 입증 생성형 AI 기술이 빠르게 발전하면서 각 모델의 성능을 객관적으로 평가하는 지표의 중요성이…

“위험한 AI는 가라”… 뤼튼, 딥시크 R1 ‘안전 모드’ 무료 서비스 시작
AI 서비스 플랫폼 기업 뤼튼테크놀로지스(대표 이세영)가 화제의 AI 모델인 딥시크(DeepSeek) R1의 ‘안전 서비스’를 국내 최초로 선보였다. 4일(한국 시간) 뤼튼은 공식 홈페이지 보도자료를 통해 카카오톡…

생성형 AI의 장문 이해력 평가: GPT-4와 Claude 3의 성능 비교
최근 구글 딥마인드 연구진이 발표한 ‘Michelangelo’ 평가 방식은 최신 대규모 언어 모델들의 장문 이해 능력을 테스트하는 새로운 기준을 제시했다. 이 평가 방식은 기존의 ‘건초더미…


