AI 성능 평가
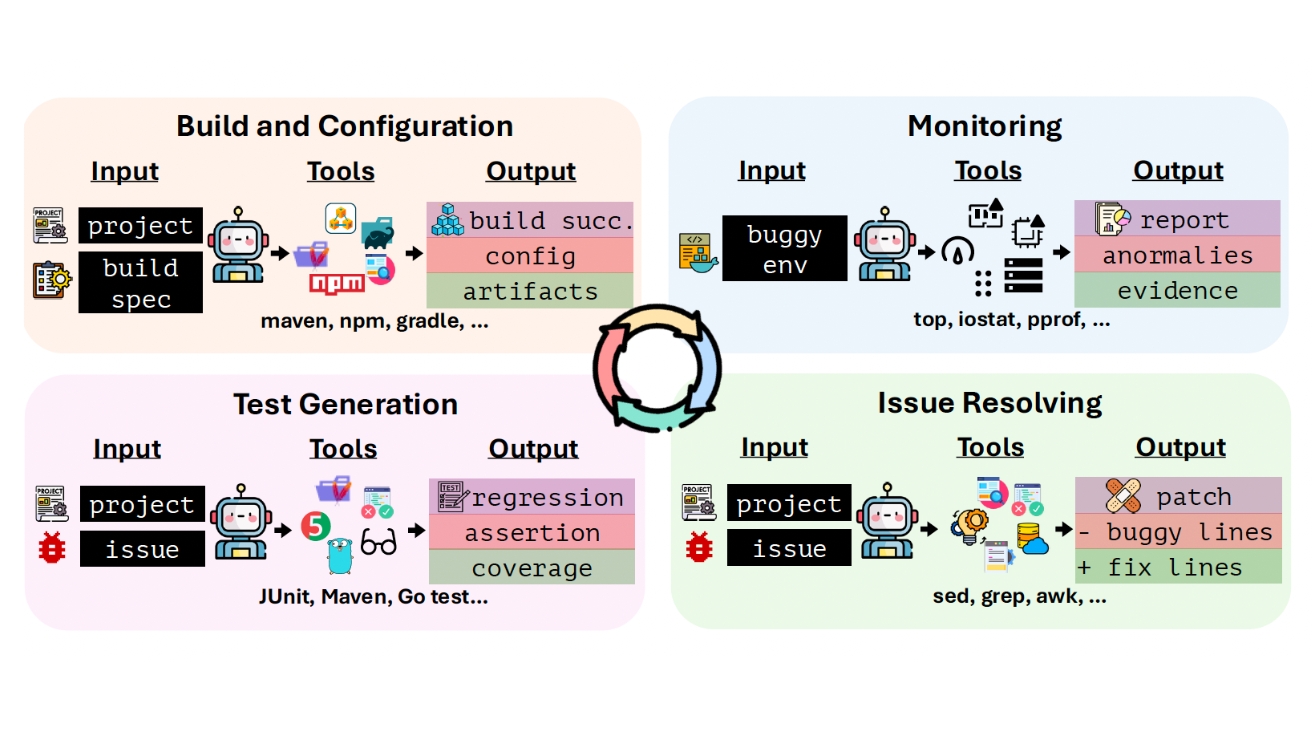
“클로드 너마저” AI 코딩 에이전트, 실전 투입했더니 10개 중 8개 낙제… “파이썬만 한다”
최신 AI 모델들이 코드 작성에서는 뛰어난 능력을 보이지만, 실제 소프트웨어를 만들고 운영하는 전 과정에서는 심각한 한계를 드러냈다. 해당 논문에 따르면, 미국과 싱가포르 대학 연구진이…
대학 연구팀이 만든 AI 채점 방식 바꿨더니 GPT-5 이겼다… 의료 분야 세계 1등 달성
AI 챗봇이 얼마나 똑똑한지 정확하게 평가하는 것은 여전히 어려운 문제다. 특히 “좋은 에세이를 써줘” 같은 정답이 정해지지 않은 질문에 AI가 얼마나 잘 대답했는지 판단하기 어렵다. 해당 논문에 따르면, 중국 전기차…

수천만원 드는 AI 성능 평가… 이제 몇백만원으로 해결 가능하다
구글 딥마인드 연구진이 AI 성능을 평가하는 새로운 방법을 개발했다. 해당 논문에 따르면, 기존에는 AI 모델 하나를 제대로 평가하려면 수천만 원이 들었지만, 이 방법을 쓰면 비용을 10분의…

AI 성적표는 90점, 실제 사용하면 60점”… 토론토대 교수가 밝힌 AI의 함정
AI가 어제는 완벽한 답을 내놓더니, 오늘은 비슷한 질문에 황당한 대답을 내놓은 경험이 있는가? 토론토대학교 경제학 교수가 발표한 연구 논문에 따르면, 이것이 단순한 우연이 아니라 수학적으로…

‘12시간 내에 품질 평가 완료’… 네이버, 음성 AI 평가 전문 기업 ‘포도노스’에 투자
네이버의 스타트업 투자기관 D2SF가 음성 AI 모델 평가 솔루션 개발사 포도노스(Podonos)에 신규 투자했다고 10일(한국 시각) 발표했다. 이번 프리 시드 라운드는 미국 세락 벤처스(Serac Ventures)가…

美, 연방기관 정부에 AI 공급 가능 업체 승인… 오픈AI·구글·앤트로픽 추가
테크크런치가 5일(현지 시간) 보도한 내용에 따르면, 미국 정부가 민간 연방기관에 인공지능 서비스를 제공할 수 있는 승인 공급업체 목록에 구글(Google), 오픈AI(OpenAI), 앤트로픽(Anthropic)을 추가했다. 이들 기업의…

AI 코딩 능력 과대포장 논란… 실제 코딩 시험 봤더니 1등이 겨우 정답률 7.5%
AI가 얼마나 잘 프로그래밍을 할 수 있는지 알아보는 새로운 시험에서 1등을 한 AI도 100점 만점에 7.5점밖에 받지 못해 충격을 주고 있다. 테크크런치가 23일(현지 시간)…

네이버클라우드, 14B 추론모델 무료 오픈소스 공개… “100분의 1 비용으로 해외 모델급 성능”
네이버클라우드가 독자 기술로 개발한 경량화 추론모델 ‘하이퍼클로바X 시드 14B 싱크(HyperCLOVA X SEED 14B Think)’를 상업용 무료 오픈소스로 공개했다고 22일(한국 시간) 발표했다. 이번에 공개된 모델은…

딥시크, 챗GPT 대신 제미나이 데이터로 바꿔 ‘R1’ 훈련했나? 의혹 점화
AI 벤치마크 전문가가 최신 딥시크(DeepSeek) R1 모델의 훈련 데이터가 기존 오픈AI(OpenAI) 합성 데이터에서 구글 제미나이(Gemini) 합성 데이터로 전환되었을 가능성을 제기했다. AI 모델 평가 플랫폼…

알리바바, 12만 토큰 고맥락 거대 문서도 척척 이해하는 AI ‘큐원롱-L1’ 공개… “오픈AI o3-mini 성능 뛰어넘어”
QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning 기존 AI 모델들이 긴 문서에서 겪던 학습 효율성 저하와 불안정성 문제 알리바바 통이랩(Tongyi Lab)이 강화학습을…

퍼플렉시티 소나, AI 검색 아레나 평가에서 1위 차지… “제미나이와 공동 1위”
퍼플렉시티(Perplexity)가 자사 블로그에 14일(현지 시간) 공개한 내용에 따르면, 퍼플렉시티의 소나(Sonar) 모델이 새로운 검색 능력 평가에서 구글 제미나이(Gemini)와 공동 1위를 차지하며 검색 증강 인공지능 시장의…

네이버, 하이퍼클로바X 신모델 공개… 저비용 고성능 ‘온 서비스 AI’로 새 시대 연다
네이버(NAVER)가 자사 뉴스룸을 통해 기존 모델 대비 40% 수준의 크기로 더 강력한 성능을 구현한 하이퍼클로바X(HyperCLOVA X) 신모델을 20일(한국 시간) 공개했다. 신모델은 대표적인 AI 성능…

전문지식 아닌 일반상식으로 실력 평가하니… “포기할래” 선언한 딥시크 R1
PhD Knowledge Not Required: A Reasoning Challenge for Large Language Models 일반인도 검증 가능한 벤치마크의 필요성 AI 모델의 능력을 평가하는 벤치마크가 점점 더 전문화되면서…

ChatGPT 무료버전 vs 유료버전, 교육 격차 더 벌어질 수 있다… 월 2만원의 차이가 만드는 성적 차이
Generative AI Takes a Statistics Exam: A Comparison of Performance between ChatGPT3.5, ChatGPT4, and ChatGPT4o-mini 범용 AI의 무료·유료 성능차: 시험성적 최대 2배 차이 미국의…

AI 혁신을 이끄는 7단계 파인튜닝 전략
대규모 언어 모델(LLM) 분야가 급속도로 발전하면서 파인튜닝 기술이 AI 응용의 핵심으로 부상하고 있다. 더블린 대학교 연구진이 발표한 최신 보고서는 LLM 파인튜닝의 전체 프로세스를 체계적으로…

EU AI법 대응 첫 기술평가 프레임워크 ‘COMPL-AI’ 공개…12개 AI 모델 준수 여부 검증
ETH 취리히와 INSAIT 소피아 대학 연구진이 EU AI법을 기술적으로 해석하고 이를 평가할 수 있는 최초의 종합적인 프레임워크 ‘COMPL-AI’를 개발했다. 이 프레임워크는 생성형 AI의 성능과…

애플, “대규모 언어 모델의 수학적 추론 능력에 한계 있어”
대규모 언어 모델(LLM)의 수학적 추론 능력에 상당한 한계가 있다는 연구 결과가 나왔다. 애플 연구팀이 발표한 ‘GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large…

호주 증권투자위원회(ASIC), “문서 요약, AI보다 인간이 낫다”
호주 증권투자위원회(Australian Securities and Investments Commission, ASIC)가 생성형 AI(인공지능)의 문서 요약 기능을 실험한 결과를 발표했다. ASIC은 지난 1월 15일부터 2월 16일까지 5주간 아마존웹서비스(AWS)와 협력해…


