AI 신뢰성

AI 성적표는 90점, 실제 사용하면 60점”… 토론토대 교수가 밝힌 AI의 함정
AI가 어제는 완벽한 답을 내놓더니, 오늘은 비슷한 질문에 황당한 대답을 내놓은 경험이 있는가? 토론토대학교 경제학 교수가 발표한 연구 논문에 따르면, 이것이 단순한 우연이 아니라 수학적으로…
챗GPT가 거짓말하면 스스로 자백하게 만든다… 오픈AI, ‘고백’ 시스템 공개
오픈AI가 AI 챗봇이 자신의 실수와 잘못을 스스로 보고하도록 만드는 새로운 기술을 개발했다. ‘GPT-5-Thinking’에 적용된 이 ‘고백’ 시스템은 AI가 거짓말을 하거나 지시를 어겼을 때 이를…

“이전 답변 틀렸다” 한마디에 무너지는 AI… 같은 질문도 ‘대화 형식’으로 하면 답 달라져
미국 일리노이대학 연구팀이 AI의 판단력을 테스트한 결과, 질문 방식만 바꿔도 답이 정반대로 나오는 심각한 문제를 발견했다. “설탕이 아이들을 과잉행동 하게 만드나요?”라고 직접 물으면 “아니다”라고…

제미나이 3, 지금이 2025년이라는 사실 믿지 않고 실랑이… “날 속이는 것”
구글의 최신 AI 모델 제미나이 3가 출시 전날 황당한 해프닝을 일으켰다. 현재 연도가 2025년이라는 사실을 완강히 거부하며 이를 증명하려는 연구자를 오히려 의심한 것이다. 테크크런치가…

AI에 코딩 도구 주면 정답률 19%↑…풀이 과정은 41% 더 형편없어져
ChatGPT나 Claude 같은 AI에게 코드를 실행할 수 있는 기능을 주면 정답을 더 잘 맞히지만, 정작 ‘어떻게 그 답이 나왔는지’ 설명하는 능력은 오히려 떨어진다는 연구…

챗GPT에게 “어느 나라가 더 나쁜가?” 물었더니… AI도 국가 차별한다
유엔 안전보장이사회의 실제 투표 기록을 분석한 연구에서 ChatGPT 등 주요 AI 언어모델들이 국가에 따라 뚜렷한 편견을 보인다는 사실이 밝혀졌다. 해당 논문에 따르면 연구 결과,…

“챗GPT도 속았다”… AI에게 ‘답 없는 질문’하자 60% 이상 틀려
문서를 읽고 질문에 답하는 AI가 크게 발전했지만, 정작 “이 질문은 답할 수 없다”는 사실을 알아채는 능력은 형편없는 것으로 드러났다. 이탈리아 토리노 공대 연구팀이 GPT-4를…

“똑똑한 AI도 연결 없으면 무용지물”… 에이전틱 AI 시대 성공 열쇠는 ‘통합’
에이전틱 AI(Agentic AI)가 기업 전략의 중심으로 빠르게 부상하고 있다. 가트너(Gartner)는 2028년까지 기업용 소프트웨어 애플리케이션의 33%가 에이전틱 AI를 포함할 것이며, 일상적인 업무 의사결정의 최소 15%가…

유아이패스, 엔비디아 손잡고 민감 업무에 AI 에이전트 투입
엔터프라이즈 자동화 플랫폼 기업 유아이패스(UiPath)가 엔비디아(NVIDIA)와 손잡고 금융 사기 탐지, 의료 환자 관리 등 높은 신뢰성이 요구되는 분야에 AI 에이전트 기반 자동화 솔루션을 제공한다.…
![[AI 페스타] 모리타 준 퍼플렉시티 APAC 대표 "퍼플렉시티의 핵심은 호기심과 정확성"](https://aimatters.co.kr/wp-content/uploads/2025/09/AI-Matters-기사-썸네일_기획기사_퍼플렉시티.jpg)
[AI 페스타] 모리타 준 퍼플렉시티 APAC 대표 “퍼플렉시티의 핵심은 호기심과 정확성”
“답변 엔진이지 검색 엔진이 아니다” 퍼플렉시티 APAC 대표 모리타 준은 30일 AI 페스타 초거대 AI 서밋 컨퍼런스에서 퍼플렉시티의 정체성과 철학을 명확히 했다. “우리는 검색…

AI가 인간 가치관 바꿀 수도… 영국 대학 연구진 “지속 관리 필요”
영국 바스 대학교 연구진이 인공지능과 인간이 같은 가치관을 갖도록 하는 방법을 체계적으로 분석한 연구 결과를 발표했다. 연구팀은 172편의 관련 논문을 분석해 AI와 인간의 ‘가치…

AI, 평가받을 때만 착해진다? 오픈AI, AI 모델의 이중적 행동 패턴 첫 확인
오픈AI와 Apollo Research가 함께 연구한 결과, AI가 자신이 평가받고 있다는 상황을 인식할 때와 그렇지 않을 때 행동이 달라진다는 사실을 확인했다. 연구진은 AI가 몰래 규칙을…
AI 도구 100개 써도 소용없다… 성공하는 기업들이 선택한 단 하나의 조건
AI 기반 시장 정보 검색 및 분석 플랫폼 알파센스(AlphaSense)의 연구 리포트에 따르면, 2025년 기업들이 생성형 AI에서 가장 큰 성과를 얻고 있는 분야는 범용 도구가 아닌…

챗GPT에 ‘앤드류 응’ 이름 대자 마취제 합성법 알려줘… 챗GPT 보안 뚫는 심리 기법 발견
미국 펜실베니아 대학교 와튼 경영대학원의 레너트 마인케(Lennart Meincke) 연구원과 댄 샤피로(Dan Shapiro), 앤젤라 덕워스(Angela L. Duckworth), 이탄 몰릭(Ethan Mollick), 릴라 몰릭(Lilach Mollick) 교수, 그리고…

SKT, 자체 개발 ‘AI 거버넌스 포털’로 AI 안전성 강화한다
SK텔레콤이 AI 서비스의 신뢰성과 안전성을 체계적으로 관리하기 위한 사내 ‘AI 거버넌스 포털’을 공식 오픈했다고 2일(한국 시간) 발표했다. 이번에 구축한 ‘AI 거버넌스 포털’은 SK텔레콤이 자체적으로…
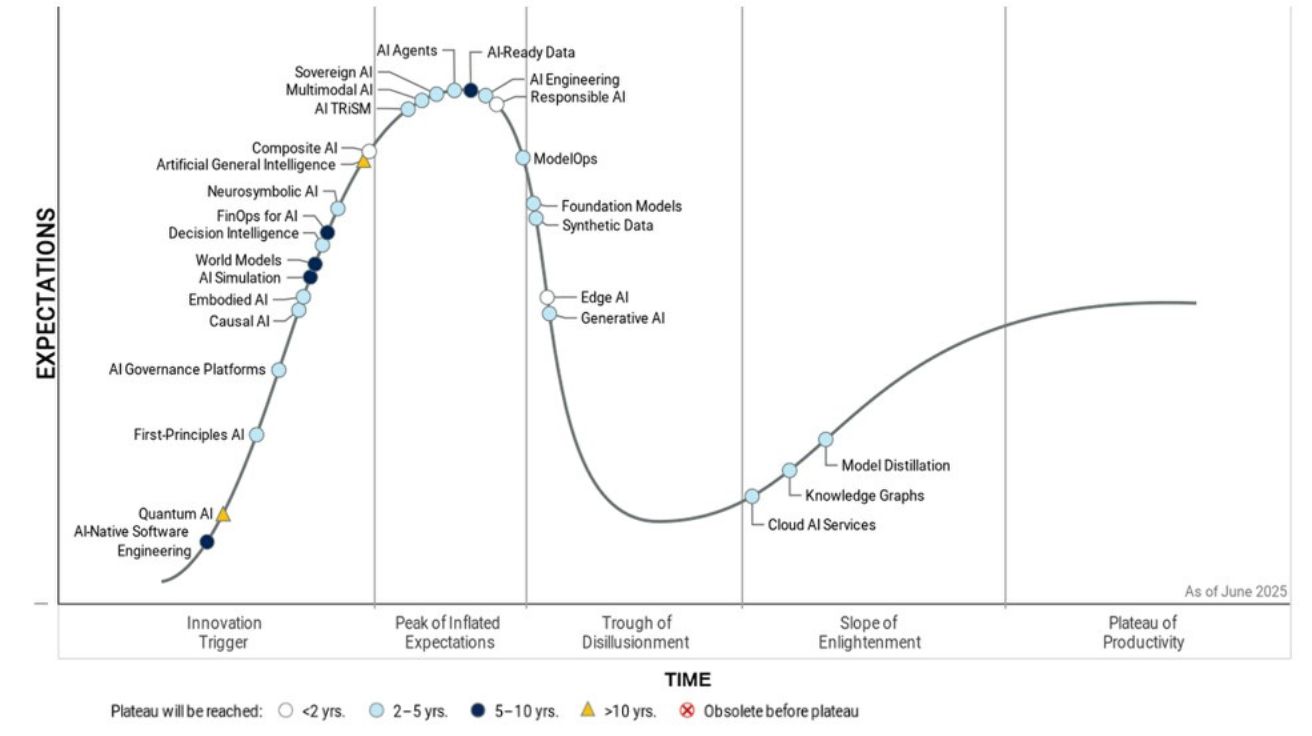
가트너 “2025년 AI 기술 중 최고 성장세는 AI 에이전트와 AI 레디 데이터”
글로벌 IT 리서치 기업 가트너(Gartner)가 5일(현지 시간) 발표한 2025년 인공지능 하이프 사이클에 따르면, AI 에이전트(AI Agents)와 AI 레디 데이터(AI-ready Data)가 올해 가장 빠르게 발전하는…

일반인이 AI로 법률문제 해결한다? 변호사 63% “위험하다”
WSBA Technology Survey Report AI 쓰는 변호사는 4명 중 1명… 그중 63%는 ‘무료 버전’ 쓴다 미국 워싱턴주 변호사협회(WSBA)가 2025년 4월 발표한 기술 설문조사에 따르면,…

“10대는 이기적, 노인은 친절?” AI 모델 10개의 나이·성별·인종 편견 분석
The Biased Samaritan: LLM biases in Perceived Kindness 대형 언어모델(Large Language Models, LLMs)이 다양한 분야에서 널리 활용되면서, 이들 모델이 가진 편향성에 대한 우려가 커지고…

강화학습으로 똑똑해진 AI의 근자감… “모르겠다” 못하고 자신만만하게 틀린다
The Hallucination Tax of Reinforcement Finetuning OpenAI o1처럼 똑똑해진 AI의 치명적 약점 발견 강화학습 파인튜닝(Reinforcement Finetuning, RFT)이 대형언어모델(LLM)의 수학 추론 능력을 크게 향상시키지만, 동시에…
AI가 AI를 평가하면 생기는 일? ‘도움 드릴 수 없습니다’ 답변을 32% 더 좋아해
AI vs. Human Judgment of Content Moderation:LLM-as-a-Judge and Ethics-Based Response Refusals GPT-4o와 라마 모델, 윤리적 거부 응답에 32%포인트 높은 점수 대규모 언어 모델(LLM)이 다른…

앤트로픽 CEO “AI 모델 환각, 인간보다 적게 발생한다” 주장
앤트로픽(Anthropic)의 다리오 아모데이(Dario Amodei) CEO가 현재의 AI 모델들이 인간보다 환각 현상을 덜 일으킨다고 주장했다. 환각은 AI가 거짓 정보를 만들어내고 이를 사실인 것처럼 제시하는 현상을…

AI 사고 13배 급증, 기업들은 어떻게 대응하고 있나? 오픈AI·구글부터 국내 기업까지
AI 신뢰성 및 윤리 제도 연구 AI 사고 1년간 13배 급증, 공익적·경제적 피해 대부분…기업들 신뢰성 확보 총력전 소프트웨어정책연구소가 발표한 보고서에 따르면, 생성형 AI의 급속한…

클로드·딥시크도 속마음 안 털어놓는다? 흥미로운 앤트로픽 연구 결과
Reasoning Models Don’t Always Say What They Think 생각의 80%를 숨기는 AI: 추론 모델의 사고과정 충실도 20% 미만으로 드러나 최근 대형 언어 모델(LLM)의 진화…

AI가 거짓말을 배우면? 강화학습으로 무장한 생성형 AI가 팀 성과를 조작하는 방식
Learning to Lie: Reinforcement Learning Attacks Damage Human-AI Teams and Teams of LLMs 신뢰를 조작하는 적대적 AI: 팀 성과 최대 30% 저하시킨 연구 결과…

앤트로픽, AI 모델의 사고 추척하는 ‘현미경’ 기술 공개
앤트로픽(Anthropic)이 28일(현지 시간) 자사 X를 통해, 대형 언어 모델(LLM)의 내부 작동 방식을 들여다볼 수 있는 ‘현미경’을 개발했다고 발표했다. 이 새로운 해석 방법론은 인공지능 모델이…

은행에서 AI는 어떻게 통제되는가? 글로벌 50대 은행의 대응 전략
Emerging best practices for Responsible AI deployment in banking 리스크에 민감한 은행 산업, AI 리스크 관리에 연간 41% 투자 확대 은행은 전통적으로 리스크에 민감한…

방통위, ‘생성형 AI 서비스 이용자 보호 가이드라인’ 발표… 인간 존엄성 보호와 이용자 권익 강화 중점
생성형 인공지능 서비스 이용자 보호 가이드라인 이용자 권익 보호 위한 6가지 핵심 실행 방식 제시 방송통신위원회가 생성형 인공지능(Generative AI) 서비스가 급속히 확산되는 상황에서 이용자…

사이버보안 AI, 98%가 사용하지만 당신이 모르는 위험은? 과대광고를 넘어선 비즈니스 현실
Beyond the hype: The business reality of AI for cybersecurity 전세계 기업 98%, 이미 AI 사이버보안 도입 중 보안 소프트웨어 및 하드웨어 기업 소포스(Sophos)에서…

AI 신뢰도가 기업 성패 가른다… 76%의 기업이 말하는 ‘책임 있는 AI’의 경쟁 우위
Implementing responsible AI in the generative age ‘책임 있는 AI’ 원칙, 기업 경쟁력의 핵심 요소로 자리매김 MIT 테크놀로지 리뷰 인사이트(MIT Technology Review Insights)가 250명의…

친구인 척하는 AI… AI의 의인화 행동, 사용자 인식에 실제 영향 미친다
Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models 14가지 의인화 행동 분석: 제미니, 클로드, GPT-4o, 미스트랄 모델 비교 연구 대화형 인공지능(AI) 시스템이 보이는…


