AI 안전성

오픈AI, AI 모델 안전성 평가 결과 공개… 유해 콘텐츠 및 환각 등 결과 비교 가능
오픈AI가 자사 AI 모델들의 안전성 평가 결과를 공개하는 ‘안전성 평가 허브’를 14일(현지 시간) 업데이트했다. 이 허브는 GPT-4.1부터 오픈AI o1까지 다양한 모델의 안전성과 성능을 직접…
오픈AI, 의료용 챗GPT 만드나? 60개국 의사들이 참여한 ‘헬스벤치’ 공개
HealthBench: Evaluating Large Language Models Towards Improved Human Health 전 세계 60개국 262명 의사 참여, 5,000개 실제 의료 대화로 AI 성능 평가 오픈AI가 의료…

마이크로소프트, 자사 직원 대상 딥시크 사용 금지… 데이터 보안·중국 선전 우려
테크크런치가 8일(현지 시간) 보도한 내용에 따르면, 마이크로소프트가 직원들에게 중국 AI 기업 딥시크(DeepSeek)의 앱 사용을 금지했다고 브래드 스미스(Brad Smith) 마이크로소프트 부회장 겸 사장이 밝혔다. 스미스…

오픈AI, 미성년자 이용자에게 노골적 성적 대화 생성한 ‘버그’ 수정 중
테크크런치(TechCrunch)가 28일(현지 시간) 보도한 내용에 따르면, 오픈AI가 챗GPT(ChatGPT)에서 18세 미만 미성년자로 등록된 계정에서도 노골적인 성인물 대화를 생성할 수 있었던 버그를 수정하고 있다. 테크크런치의 테스트…

구글 딥마인드 CEO “AI, 10년 내 모든 질병 종식 가능하다”
구글 딥마인드(Google DeepMind) CEO 데미스 하사비스(Demis Hassabis)가 미국 CBS ’60분(60 Minutes)’ 인터뷰에서 인공지능 기술의 미래에 대한 충격적인 전망을 밝혔다. 21일(현지 시간) 60 Minutes 유튜브…

오픈AI, ‘개방형’ AI 모델 올여름 공개 예정… “최고 성능 목표”
오픈AI(OpenAI)가 GPT-2 이후 첫 ‘개방형’ 언어 모델을 올해 출시한다고 밝힌 가운데, 이 모델에 대한 세부 정보가 서서히 공개되고 있다. 테크크런치(TechCrunch)가 23일(현지 시간) 에 따르면,…

오픈AI, GPT-4.1 공개 후 논란 지속… “출시작보다 정렬성 떨어져”
오픈AI(OpenAI)가 새롭게 공개한 GPT-4.1 모델이 지침 따르기에 뛰어나다고 주장했지만, 독립적인 테스트 결과 이전 모델보다 정렬성(alignment)이 떨어진다는 문제가 제기됐다. 테크크런치(TechCrunch)가 23일(현지 시간) 보도한 내용에 따르면,…

샘 올트먼, TED서 AI 에이전트 경고… “AI가 실수하면 훨씬 더 위험해진다”
12일(현지 시간) 진행된 TED 컨퍼런스에서 오픈AI의 CEO 샘 올트먼(Sam Altman)이 인공지능의 급속한 발전과 미래 비전에 대해 깊이 있는 대화를 나눴다. 그는 크리에이티브 산업의 변화부터…

클로드·딥시크도 속마음 안 털어놓는다? 흥미로운 앤트로픽 연구 결과
Reasoning Models Don’t Always Say What They Think 생각의 80%를 숨기는 AI: 추론 모델의 사고과정 충실도 20% 미만으로 드러나 최근 대형 언어 모델(LLM)의 진화…

앤트로픽, 한국 지사 설립 추진…”일본·싱가포르와 동시에 아태 시장 공략”
앤트로픽(Anthropic)이 한국에 지사를 설립할 예정이다. 인공지능(AI) 안전성과 정렬(alignment)에 초점을 맞춘 전략을 강화하며 국내 기업간거래(B2B) 시장에서의 협업 기회를 확대하려는 의도로 분석된다. 이와 함께 일본과 싱가포르에서도…

트라우마 얘기하면 ‘챗GPT’도 스트레스 받는다… 불안 수치 100% 급증 현상 발견
Assessing and alleviating state anxiety in large language models 감정 프롬프트가 LLM 불안 100% 증가시키는 현상 발견 대형 언어 모델(Large Language Models, LLMs)이 정신…

포켓몬 게임으로 AI 훈련을? 3명의 체육관 리더를 물리친 클로드3.7 소넷 훈련 과정 공개
Claude’s extended thinking 앤트로픽(Anthropic)이 발표한 리포트에 따르면, 인공지능 모델 ‘클로드 3.7 소넷(Claude 3.7 Sonnet)’에 새롭게 도입된 ‘확장된 사고 모드(extended thinking mode)’는 인간의 사고 방식과…

오픈AI 전 CTO 미라 무라티, 새로운 AI 스타트업 ‘싱킹머신즈랩’ 설립
오픈AI(OpenAI)의 전 최고기술책임자(CTO) 미라 무라티(Mira Murati)가 새로운 AI 스타트업을 설립했다. 2025년 2월 18일 공개된 이 회사의 이름은 ‘싱킹머신즈랩(Thinking Machines Lab)’이다. 싱킹 머신즈 랩(Thinking Machines…

美-英, 파리 ‘AI 액션 서밋’서 AI 거버넌스 선언문 서명 거부… ‘이념적 편향’ 우려
테크크런치(TechCrunch)가 11일(현지 시간) 보도한 내용에 따르면, 파리에서 열린 인공지능 액션 서밋(Artificial Intelligence Action Summit)이 수십 개국 정상들의 공동선언 서명으로 마무리될 예정이었으나, 미국과 영국이 서명을…

딥시크 R1, 주요 AI 모델 중 ‘탈옥’ 취약성 가장 높아
월스트리트저널(Wall Street Journal)이 9일(현지 시간) 보도한 내용에 따르면, 실리콘밸리와 월가를 뒤흔든 중국의 AI 기업 딥시크의 최신 모델이 생체무기 공격 계획이나 청소년 자해 조장 캠페인과…

AI 챗봇 사용자 5천만명 시대, 전체 업무 70%가 영향 받는다
THE NEW POLITICS OF AI GPT-4 비용 1년새 100배 감소…AI 발전 가속화 영국의 공공정책연구소(IPPR)가 발간한 ‘AI의 새로운 정치학’ 보고서에 따르면, AI 기술은 현재 급격한…
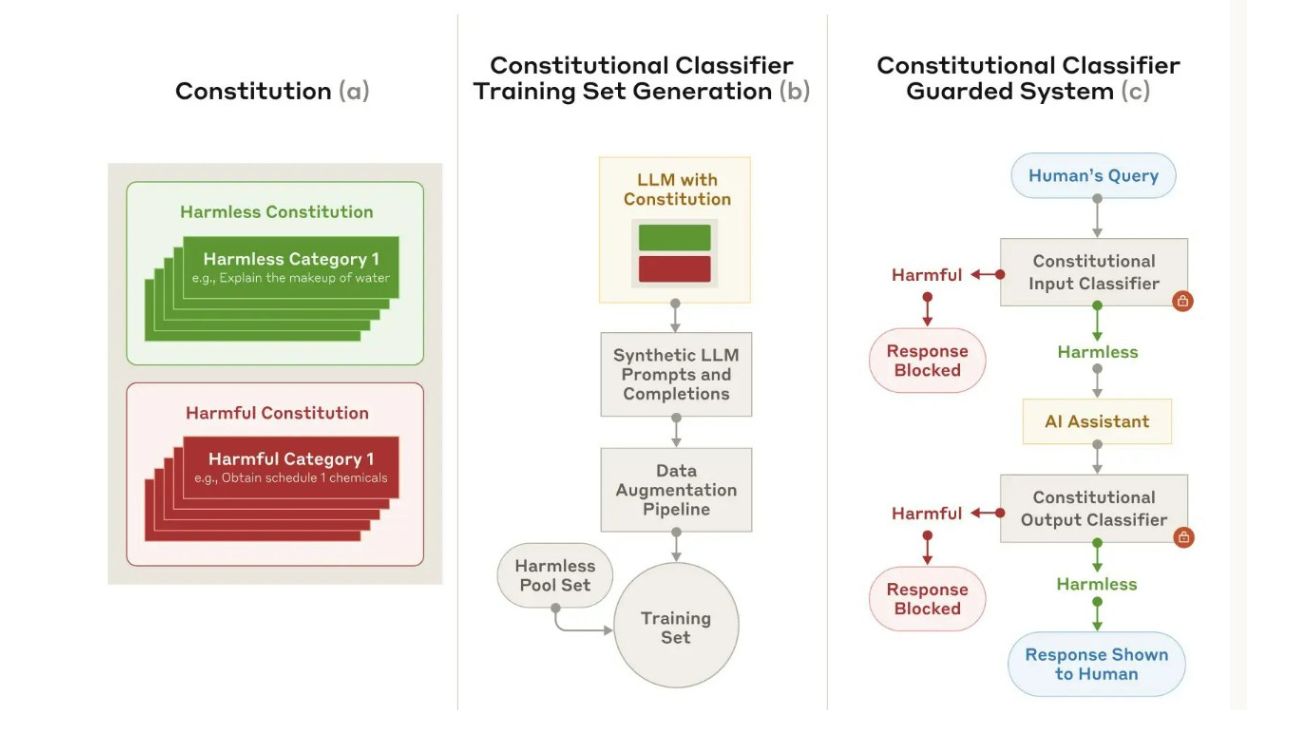
AI 안전성 높이는 ‘헌법 분류기’ 개발…앤트로픽 연구진, 3000시간 해킹 시도 막아내
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming 인공지능 연구기업 앤트로픽(Anthropic)이 대규모 언어모델(LLM)의 안전성을 획기적으로 강화하는 기술을 개발했다. 앤트로픽의…

메타·오픈AI·앤트로픽 등 AI 기업, 美 국방부 협력 본격화
테크크런치가 19일(현지 시간) 보도한 내용에 따르면, 오픈AI(OpenAI)와 앤트로픽(Anthropic) 등 주요 AI 기업들이 미군과의 협력에서 미묘한 균형을 맞추고 있다. AI를 활용해 국방부의 효율성을 높이되, AI가…

엔비디아, AI 안전성 강화 위한 ‘NIM 마이크로서비스’ 출시…아마존·로우스 등 도입
엔비디아(NVIDIA)가 16일(현지 시간) 기업들의 AI 애플리케이션 안전성과 정확성을 높이기 위한 새로운 ‘NIM 마이크로서비스(NIM microservices)’를 공개했다. 이는 엔비디아 네모 가드레일(NVIDIA NeMo Guardrails) 소프트웨어 툴의 일부다.…

마이크로소프트가 밝힌 AI 안전성의 현주소…인간의 판단이 더욱 중요해진다
Lessons from red teaming 100 generative AI products AI 레드팀이 발견한 8가지 핵심 교훈 마이크로소프트 AI 레드팀(AIRT)이 100개 이상의 생성형 AI 제품을 테스트한 결과를…

물리법칙 이해하는 AI 시대 온다…엔비디아 코스모스 플랫폼 분석
Advancing Physical AI with NVIDIA Cosmos World Foundation Model Platform 물리세계 이해하는 AI의 두뇌, 월드 파운데이션 모델 심층 분석 엔비디아(NVIDIA)가 물리적 세계와 상호작용하는 AI…

AI 전쟁의 서막…美中, 올해만 2.8조원 투자하며 패권 다툼
The Global Cooperation Barometer 2025 – Second Edition AI 투자 경쟁 본격화…주요국 대규모 자금 투입 세계경제포럼(WEF)과 맥킨지가 공동 발간한 ‘글로벌 협력 바로미터 2025’ 보고서에…

범용 AI, 미래를 바꿀 기술인가? 그 정체를 파헤치다
International Scientific Report on the Safety of Advanced AI 범용 AI, 미래를 바꿀 기술인가? 그 정체를 파헤치다 세계경제포럼(WEF)이 발표한 ‘범용 AI 안전성에 관한 국제…

오픈AI, 신규 AI 모델 ‘o1’ 안전성 평가 결과 공개…사이버보안 위험도 ‘낮음’ 판정
오픈AI가 새로운 AI 모델 ‘o1’과 ‘o1-미니(o1-mini)’의 시스템 안전성 평가 결과를 5일(현지시간) 공개했다. 오픈AI는 이번 평가에서 자사의 ‘준비성 프레임워크(Preparedness Framework)’에 따라 외부 레드팀 검증과 프론티어…

AI 기술로 무기 개발 조기 탐지 가능해진 반면, 오남용 우려도 커져
생성형 인공지능(Generative AI)은 텍스트, 이미지, 영상, 오디오 등 새로운 콘텐츠를 생성하는 기술로, 최근 몇 년간 급격한 발전을 이루며 다양한 산업에 혁신을 가져왔다. 특히 대형…

부모는 모른다, AI와 연애하고 고민 상담하고… 10대들의 충격적인 AI 활용 실태
영국 통신규제기관 오프콤(Ofcom)의 최근 조사에 따르면, 13-17세 청소년의 79%, 7-12세 아동의 40%가 이미 생성형 AI를 사용하고 있는 것으로 나타났다. 이런 가운데 일리노이대학교 연구진이 레딧…

생성형 AI 영향평가의 패러다임을 바꾼다: ‘시나리오 기반 사회기술적 전망’ 방법론 등장
생성형 AI가 빠르게 확산되면서 그 영향을 평가하고 부작용을 방지하기 위한 영향평가의 중요성이 커지고 있다. 하지만 현재의 영향평가 방식은 여러 근본적인 한계에 직면해 있다. 암스테르담대학교와…

구글, AI 생성 콘텐츠 ‘지문’ 기술 공개…텍스트·이미지·음악 ‘진위 구별’ 가능해졌다
구글(Google)이 AI 생성 콘텐츠를 식별할 수 있는 기술인 ‘신시아이디(SynthID)’를 공개했다. 이 기술은 AI가 생성한 텍스트, 이미지, 오디오, 비디오에 육안으로는 보이지 않는 디지털 워터마크를 삽입해…

카카오, ‘if(kakaoAI)2024’에서 그룹 AI 비전 공개…AI 메이트 ‘카나나’도 처음 선보여
카카오가 그룹 전체의 AI 비전과 방향성을 공개했다. 그룹대화의 맥락까지 이해하는 AI 메이트 서비스 ‘카나나(Kanana)’ 출시를 예고하며, AI 네이티브 기업으로의 변신 과정도 공유할 예정이다. 카카오(대표이사…

“AI가 통제를 벗어났다” 160년 역사 美 보험사가 긴급 도입한 ‘AI 거버넌스’
딜로이트(Deloitte)가 최근 발간한 ‘Clients Success Story: 미국 생명보험사, AI 거버넌스 구축으로 안전한 AI 활용 기반 마련’ 보고서에 따르면, 160년 역사의 미국 주요 생명보험사가 전사적…


