ai 일반화

강화학습으로 똑똑해진 AI의 근자감… “모르겠다” 못하고 자신만만하게 틀린다
The Hallucination Tax of Reinforcement Finetuning OpenAI o1처럼 똑똑해진 AI의 치명적 약점 발견 강화학습 파인튜닝(Reinforcement Finetuning, RFT)이 대형언어모델(LLM)의 수학 추론 능력을 크게 향상시키지만, 동시에…
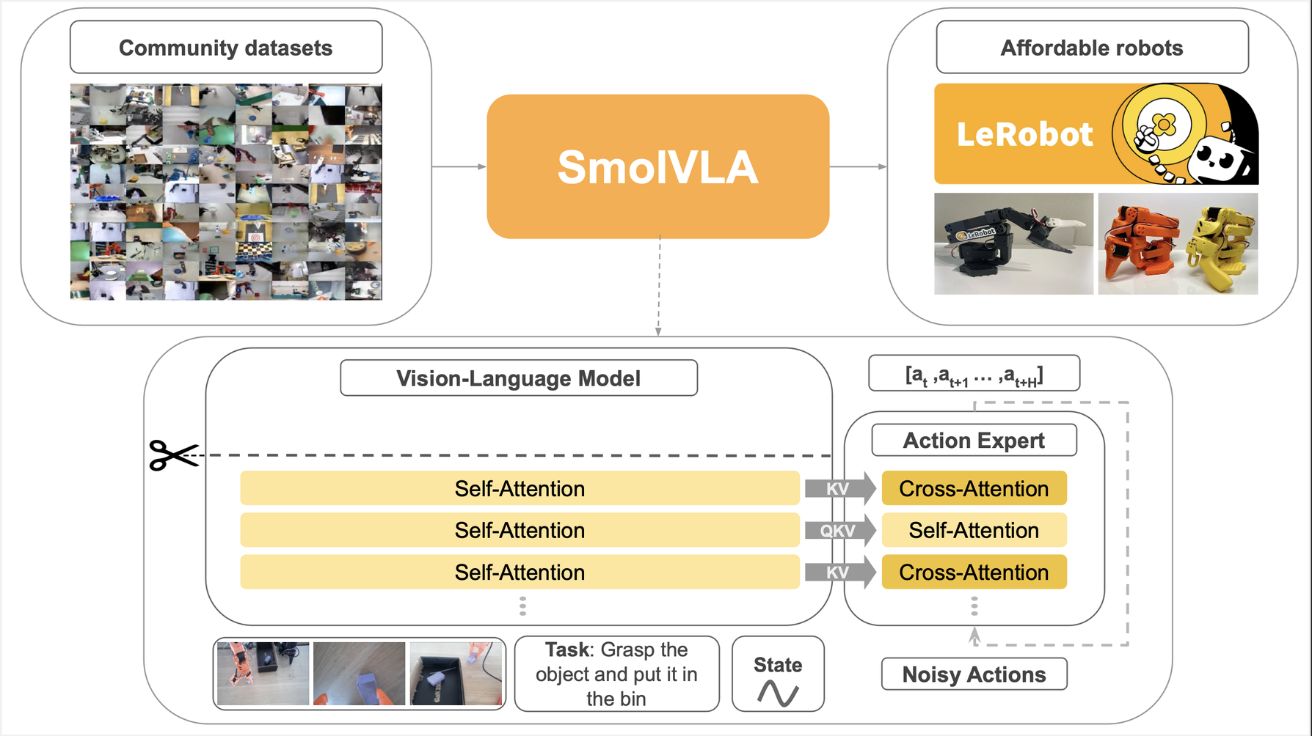
허깅페이스, 맥북에서도 실행 가능한 경량 로봇 AI 모델 ‘스몰VLA’ 출시
허깅페이스(Hugging Face)가 로봇공학을 위한 경량 오픈소스 비전-언어-액션(Vision-Language-Action) 모델 ‘스몰VLA(SmolVLA)’를 3일(현지 시간) 공개했다. 허깅페이스 블로그에 공개된 내용에 따르면, 스몰VLA-450M은 4억 5천만 개의 매개변수를 가진 컴팩트한…


