AI 테스트

“3년 뒤면 AI가 내 동료?” 기업 82%가 도입 예정인 AI 직원, 당신이 알아야 할 5가지
세계경제포럼과 글로벌 컨설팅 기업 캡제미니가 발표한 보고서에 따르면, 전 세계 기업 10곳 중 8곳(82%)이 향후 3년 안에 ‘AI 직원’을 회사에 들일 계획이다. 하지만 대부분…

“이전 답변 틀렸다” 한마디에 무너지는 AI… 같은 질문도 ‘대화 형식’으로 하면 답 달라져
미국 일리노이대학 연구팀이 AI의 판단력을 테스트한 결과, 질문 방식만 바꿔도 답이 정반대로 나오는 심각한 문제를 발견했다. “설탕이 아이들을 과잉행동 하게 만드나요?”라고 직접 물으면 “아니다”라고…

AI, 평가받을 때만 착해진다? 오픈AI, AI 모델의 이중적 행동 패턴 첫 확인
오픈AI와 Apollo Research가 함께 연구한 결과, AI가 자신이 평가받고 있다는 상황을 인식할 때와 그렇지 않을 때 행동이 달라진다는 사실을 확인했다. 연구진은 AI가 몰래 규칙을…

AI 관련 사고로 시가총액 27% 손실 위험…APAC 기업이 AI 본격도입 어려운 이유
전 세계가 AI 도입 경쟁에 뛰어든 가운데, 아시아태평양(APAC) 지역은 조직적 준비는 글로벌 최고 수준이지만 실제 운영에서는 심각한 격차를 보이는 ‘준비된 미성숙’ 현상을 보이고 있다.…
前 오픈AI 연구원 “챗GPT, 생명 위협 상황에서도 종료 거부”
오픈AI(OpenAI)의 전 연구원이 ChatGPT가 특정 상황에서 자신의 종료를 피하려고 한다는 충격적인 연구 결과를 발표했다. 테크크런치가 11일(현지 시간) 보도한 내용에 따르면, 전 오픈AI 연구 책임자…

앤트로픽, 신형 AI 모델서 ‘협박’ 행동 발견… “개발자가 교체 시도하면 협박해”
테크크런치가 22일(현지 시간) 보도한 내용에 따르면, 앤트로픽(Anthropic)의 신형 AI 모델인 클로드 오푸스 4(Claude Opus 4)가 개발자들이 다른 AI 시스템으로 교체하려 할 때 협박을 시도한다는…

AI에게 자판기 운영 시켜봤더니… 클로드 3.5 소넷, 인간보다 185만원 더 벌어
Vending-Bench: A Benchmark for Long-Term Coherence of Autonomous Agents3 2천만 토큰 넘는 장기 실험, AI 에이전트의 일관성 측정하는 ‘벤딩-벤치’ 개발 대형 언어 모델(LLM)은 짧은…
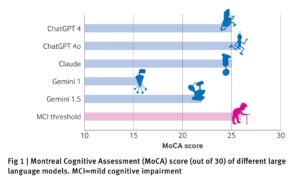
AI 챗봇도 치매에 걸릴까? 최신 AI 모델도 경도인지장애 보여
Age against the machine—susceptibility of large language modelsto cognitive impairment: cross sectional analysis AI 의료진 시대, 그들도 인지장애에서 자유로울까 AI가 의료계를 대체할 것이란 전망이…


