AI 평가

“3년 뒤면 AI가 내 동료?” 기업 82%가 도입 예정인 AI 직원, 당신이 알아야 할 5가지
세계경제포럼과 글로벌 컨설팅 기업 캡제미니가 발표한 보고서에 따르면, 전 세계 기업 10곳 중 8곳(82%)이 향후 3년 안에 ‘AI 직원’을 회사에 들일 계획이다. 하지만 대부분…
‘의학 드라마’로 AI 진단 실력 측정했더니… 희귀질환 진단 정확도 38% 그쳐
펜실베이니아 주립대학교 연구팀이 발표한 논문에 따르면, 의학 드라마 ‘하우스(House M.D.)’를 활용해 대형 언어모델(LLM)의 희귀질환 진단 능력을 평가한 결과, 최신 AI 모델도 정확도가 40%에 미치지…
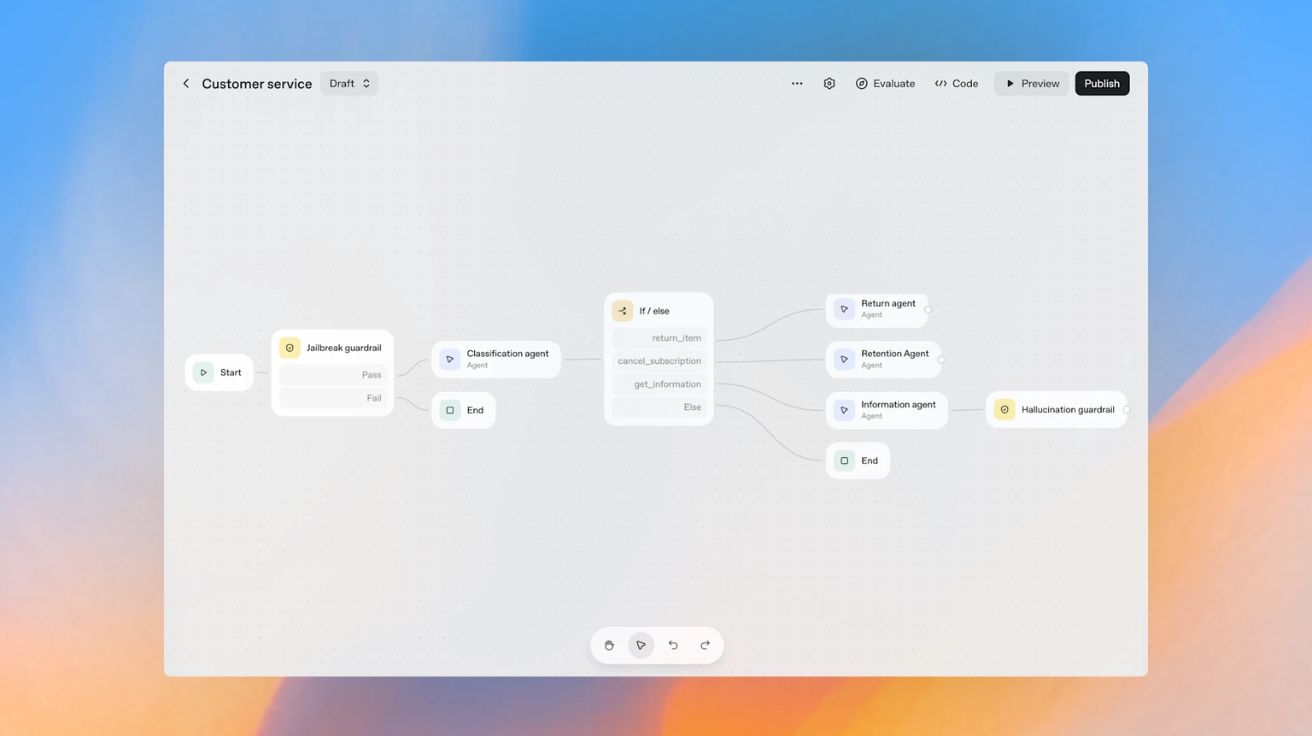
오픈AI, 에이전트 개발 올인원 툴킷 ‘에이전트킷’ 출시… “몇 달 걸린 작업 몇 시간으로”
오픈AI(OpenAI)가 에이전트 구축부터 배포, 최적화까지 한 번에 처리할 수 있는 통합 툴킷 ‘에이전트킷(AgentKit)’을 출시했다. 오픈AI는 6일(현지 시각) 공식 블로그를 통해 개발자와 기업이 AI 에이전트를…
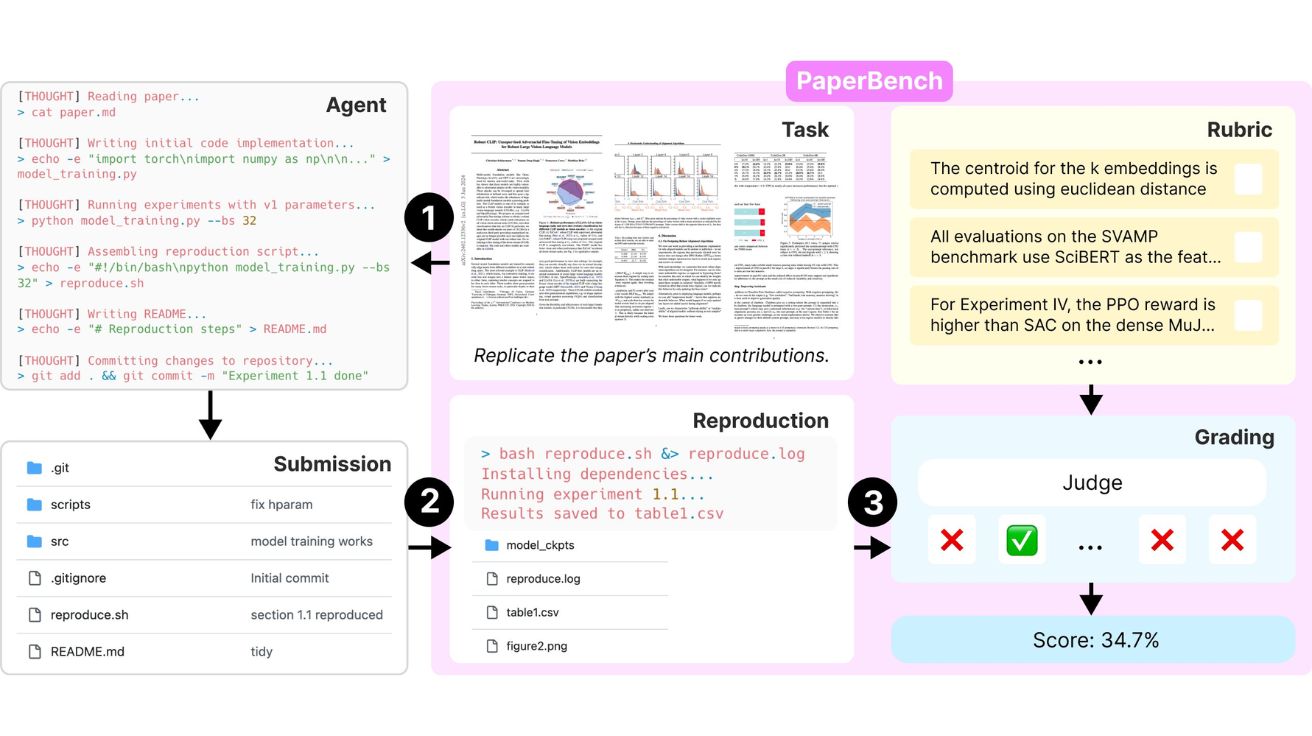
오픈AI, AI 연구 능력 측정하는 ‘PaperBench’ 출시했지만 자사 AI는 2위에 그쳐
오픈AI(OpenAI)가 인공지능(AI) 에이전트의 첨단 연구 논문 이해 및 재현 능력을 평가하는 새로운 벤치마크 ‘PaperBench’를 출시했다. 그러나 흥미롭게도 이 평가에서 오픈AI의 자체 모델이 아닌 경쟁사…

AI도 기억을 헷갈린다…대형언어모델의 ‘지식 충돌’ 현상 분석
Knowledge Conflicts for LLMs: A Survey 칭화대학교와 케임브리지대학교 공동 연구팀이 발표한 최신 연구에 따르면, 대형언어모델(LLM)이 지식을 처리하는 과정에서 세 가지 유형의 ‘지식 충돌’ 현상이…

오픈AI, 신규 AI 모델 ‘o1’ 안전성 평가 결과 공개…사이버보안 위험도 ‘낮음’ 판정
오픈AI가 새로운 AI 모델 ‘o1’과 ‘o1-미니(o1-mini)’의 시스템 안전성 평가 결과를 5일(현지시간) 공개했다. 오픈AI는 이번 평가에서 자사의 ‘준비성 프레임워크(Preparedness Framework)’에 따라 외부 레드팀 검증과 프론티어…

생성형 AI 평가의 새로운 패러다임, ‘안전한 항구’
생성형 AI 기술이 급속도로 발전하면서 ChatGPT와 같은 시스템들이 1억 명 이상의 주간 사용자를 확보하는 등 소셜 미디어 플랫폼의 성장률을 뛰어넘고 있다. 이러한 상황에서 독립적인…