AI 해석 가능성

AI에 코딩 도구 주면 정답률 19%↑…풀이 과정은 41% 더 형편없어져
ChatGPT나 Claude 같은 AI에게 코드를 실행할 수 있는 기능을 주면 정답을 더 잘 맞히지만, 정작 ‘어떻게 그 답이 나왔는지’ 설명하는 능력은 오히려 떨어진다는 연구…
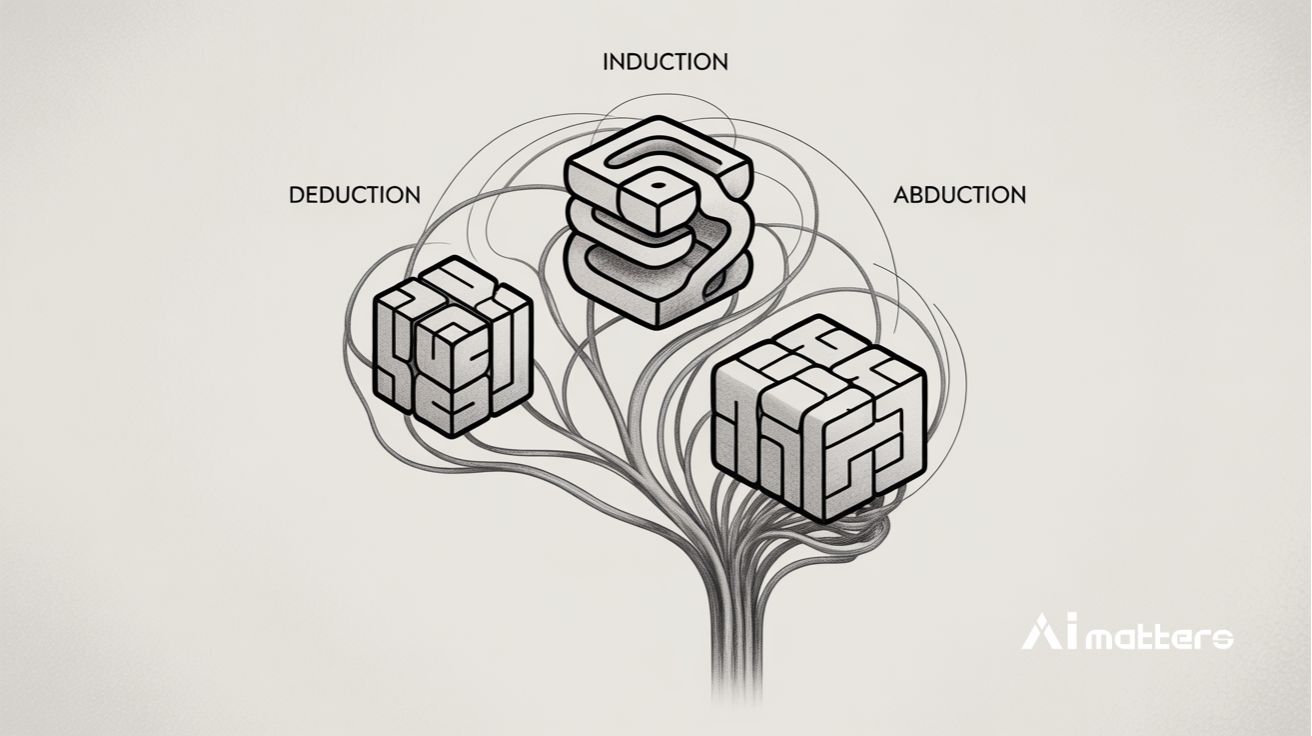
‘번뜩’ 하는 순간에 의존하던 AI, 드디어 체계적으로 생각하는 법을 배웠다! 수학·코딩 성능 10% 급상승의 비밀
Beyond ‘Aha!’: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models 오픈AI o1·딥시크 R1도 겪는 ‘아하!’ 순간의 예측 불가능성 문제 세일즈 포스 AI 연구소 및…

위험한 AI, 어떻게 통제할 것인가? 구글 딥마인드의 AGI 안전성 마스터플랜
An Approach to Technical AGI Safety and Security 오용과 오정렬 차단: 구글의 AGI 안전성 핵심 전략 인공지능이 점점 더 강력해지면서 일반인공지능(AGI)의 안전성 확보가 중요한…


