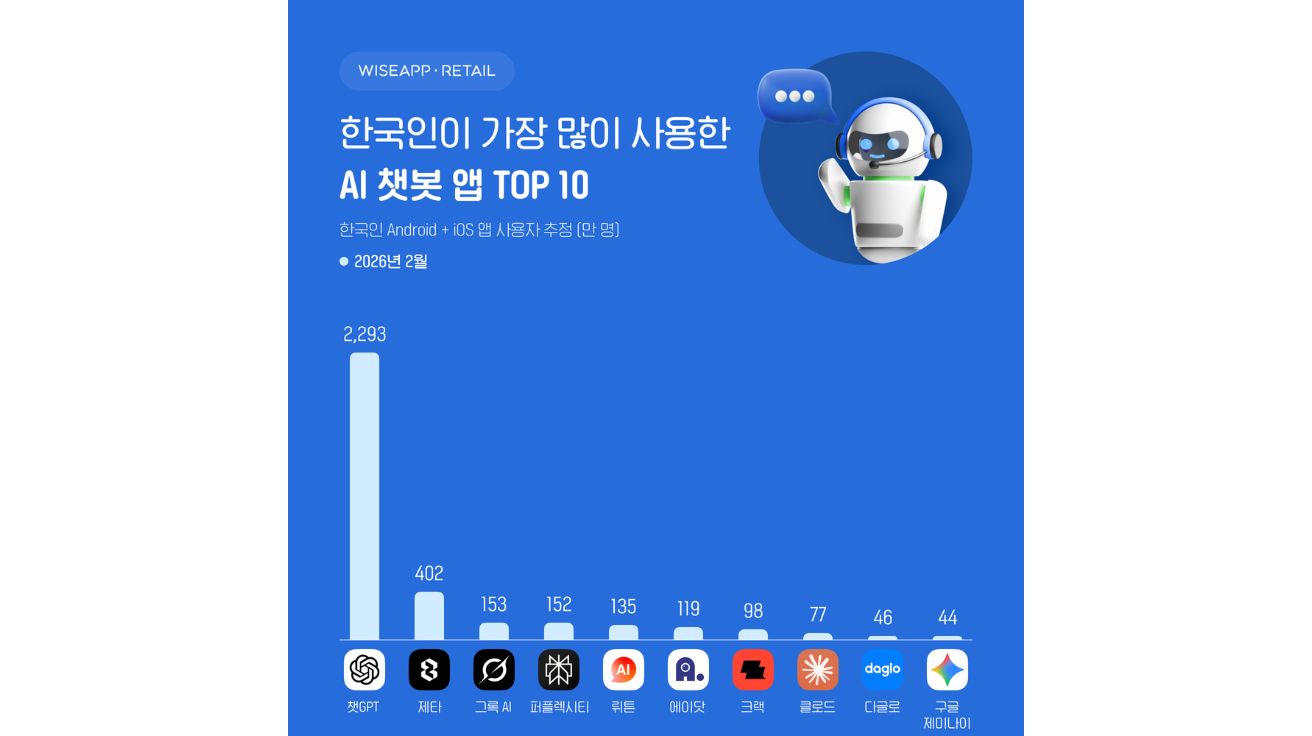
AI Report 언어 모델 연구

컴퓨터공학과 학생들은 챗GPT를 어떻게 쓰고 있을까
챗GPT가 대학 교육 현장에 깊숙이 들어온 지금, 학생들은 실제로 이 도구를 어떻게 활용하고 있을까. 영국 유니버시티 칼리지 런던(UCL) 연구진이 컴퓨터공학과 학부생 6명을 심층 인터뷰한…

AI가 자신의 실수를 알면서도 고치지 못하는 이유
클로드, 챗GPT, 제미나이 등 최첨단 대형 언어 모델이 의료 진단, 투자 결정, 법률 자문 같은 고위험 상황에서 스스로의 오류를 정확히 인식하면서도 같은 실수를 반복한다는…

“사람을 그려줘”라고 했을 뿐인데, AI는 왜 항상 백인 얼굴을 만들어낼까
챗GPT나 제미나이 같은 AI 이미지 생성기에 “사람을 그려줘”라고 입력하면 어떤 얼굴이 나올까. 특정 인종이나 성별을 지정하지 않아도 AI는 스스로 ‘기본값 인간’을 선택한다. 볼로냐대학교 로베르토…

AI가 스마트 계약 보안을 완전히 대체할 수 없다는 연구 결과가 나왔다
오픈에이아이(OpenAI), 패러다임(Paradigm), 오터섹(OtterSec)이 공동 개발한 EVMbench는 AI 에이전트의 스마트 계약 보안 능력을 측정하는 최초의 대규모 벤치마크다. 취약점 탐지 45.6%, 익스플로잇(exploit, 취약점 실제 공격) 성공률…

AI가 세계 최고 물리올림피아드에서 처음으로 만점을 받았다
전 세계 100개국 이상의 최상위 고등학생들이 겨루는 국제물리올림피아드(IPhO)에서 인공지능(AI)이 처음으로 만점을 기록했다. 캘리포니아 산타클라리타의 연구자 황이천(Yichen Huang)이 구글 딥마인드의 제미나이(Gemini) 3.1 프로 프리뷰를 기반으로…

AI가 해커보다 먼저 움직인다, CISO들이 선택한 생존 전략
전 세계 기업 보안을 책임지는 최고 정보보안 책임자(CISO, Chief Information Security Officer)들이 전례 없는 압박에 직면해 있다. 스플렁크(Splunk)가 2025년 7월과 8월 사이 9개국 650명의…

미국 10대 64%가 AI 챗봇을 쓰는 시대, 부모 10명 중 3명은 사실조차 모른다
퓨 리서치 센터(Pew Research Center)가 2026년 2월 24일 공개한 보고서 “10대의 AI 사용과 인식(How Teens Use and View AI)”은 미국 10대 청소년의 AI 챗봇…

챗GPT가 스택 오버플로를 오염시키고 있다, AI가 AI를 잡아낸다
개발자들의 성지로 불리는 스택 오버플로(Stack Overflow)가 조용히 무너지고 있다. 챗GPT(ChatGPT)가 생성한 그럴듯한 답변들이 플랫폼을 채우기 시작하면서, 수백만 개발자가 매일 의존하는 이 지식 공유 플랫폼의…

AI가 만든 영상인지 모르고 봤다, 소라 사용자 254명이 털어놓은 충격 반응
오픈AI(OpenAI)의 텍스트-투-비디오(text-to-video) 서비스 소라(Sora)에서 실제 사용자들은 어떤 경험을 하고 있을까. 일리노이대학교 어바나-샴페인(University of Illinois Urbana-Champaign) 등 공동 연구팀이 소라 플랫폼의 사용자 댓글 254개를 질적으로…

사진 한 장으로 내 얼굴·손동작까지 살아 움직이는 AI 영상 만든다… 클링-모션 컨트롤 출시
중국 동영상 플랫폼 쾌수(Kuaishou)가 개발한 AI 영상 생성 서비스 클링(Kling)이 2026년 3월, 새로운 캐릭터 애니메이션 기술 ‘클링-모션컨트롤(Kling-MotionControl)’을 공개했다. 사진 한 장만 있으면 해당 인물이…
구글 나노 바나나가 만든 가짜 흉부 X선으로 폐렴을 92% 정확도로 잡아냈다
의료 AI 개발의 가장 큰 걸림돌 중 하나는 환자 데이터를 구하기 어렵다는 점이다. 개인정보 보호 규정, 병원 간 데이터 공유 제한, 희귀 질환의 절대적인…
![[AI 트렌드] 말 한마디로 내 노래가 생긴다? 제미나이 음악 생성 프롬프트](https://aimatters.co.kr/wp-content/uploads/2026/03/AI-매터스-기사-썸네일-3.jpg)
AI 이미지 생성의 공식이 나왔다, 구조화된 프롬프트가 일관성을 95%까지 끌어올린다
구글(Google)의 최신 이미지 생성 모델 ‘제미나이 3 프로 이미지(Gemini 3 Pro Image)’를 전문가 수준으로 제어하는 방법론이 공개됐다. 독립 연구자 루카 카차니가(Luca Cazzaniga)가 6개월간 약…

집에서 쓰는 챗GPT가 직장보다 2배 더 효율적인 충격적 이유
챗GPT(ChatGPT)가 직장에서 업무 효율을 높인다는 연구는 많았다. 그런데 정작 집에서는 어떤 변화를 만들었을까? 스탠퍼드, UCLA, USC 연구진이 2026년 3월 발표한 논문은 처음으로 이 질문에…

AI가 지도를 공부한 게 아니었다? 단어 패턴만으로 세계 지리를 꿰뚫는 충격 실험
내비게이션 앱도 아닌데, 지도 데이터도 없는데, AI가 “레이캬비크”라는 단어 하나만 보고 그 도시가 북쪽의 추운 곳이라는 걸 맞혔다면 믿겠는가. 플로리다 애틀랜틱 대학교(Florida Atlantic University)의…

AI도 시험 도중 실수를 고친다, 기존보다 5배 빠른 학습의 비밀
어떤 학생은 시험지를 한 번 훑고 바로 제출한다. 또 다른 학생은 풀이 과정을 천천히 되짚으며 틀린 부분을 고쳐 나간다. 당연히 후자가 더 좋은 점수를…

AI가 빨강과 파랑을 구분 못하는 이유, 프린스턴대가 풀었다
인터넷을 뜨겁게 달궜던 파검 드레스 논란을 기억하는가. AI도 조명에 따라 사진 속 고양이를 완벽하게 인식하다가, 조명이 조금만 바뀌면 갑자기 개로 착각하는 경우가 있다. 프린스턴대학교…

AI가 쓴 코드, 누가 만들었는지 밝혀낸다…챗GPT vs 클로드 판별 성공
챗GPT가 작성한 코드인지, 클로드가 만든 코드인지 구별할 수 있을까? 최근 중국 쓰촨대학교 연구팀이 AI가 생성한 코드의 출처를 추적하는 기술을 개발해 주목받고 있다. 마치 필적…

말만 하면 AI가 생각을 정리해주는 시대, ‘오럴리티’가 바꾸는 사고의 방식
회의 중 떠오른 아이디어를 메모하려다 놓친 경험이 있는가? 복잡한 생각을 정리하려고 키보드 앞에 앉았지만 막상 어디서부터 써야 할지 막막했던 적은? 홍콩시립대학교 연구팀이 개발한 ‘오럴리티(Orality)’는…

AI가 시각장애인의 ‘DIY 설명서’ 읽어주면 절반은 틀린다
시각장애인들은 가구를 조립하거나 전자제품을 설정할 때마다 보이지 않는 벽에 부딪힌다. 제품 설명서는 그림과 도식으로 가득 차 있고, 이를 AI에게 대신 읽어달라고 해도 엉뚱한 정보를…

AI가 연구자 대신 논문 댓글까지 분류한다, 단돈 6천 원으로 5만 건을
인공지능(AI)이 인간 코더를 대체할 수 있을까. 체코 생명과학대학교(Czech University of Life Sciences Prague) 연구자 미하일 하만(Michael Haman)이 이 질문에 정면으로 답하는 벤치마크(benchmark, 성능 측정…

AI 보안 어드바이저가 틀린 답변을 준다면? 챗GPT와 클로드의 위험한 실수들
버지니아 공대(Virginia Tech) 연구팀이 공개한 최신 논문은 AI 챗봇을 보안 자문으로 활용할 때 얼마나 심각한 오류가 발생하는지 실증적으로 보여준다. GPT-5.2와 Claude Opus-4.6을 대상으로 하드웨어…

AI가 장애 혐오 표현을 찾아내고 고쳐준다면? 100명의 장애인이 평가한 결과
“휠체어에 갇힌(wheelchair-bound)”이라는 표현이 왜 문제일까? 카네기멜론대학교와 컬럼비아대학교, 마이크로소프트 연구팀이 공동으로 진행한 연구는 일상 속 미묘한 장애 혐오 표현을 AI가 얼마나 정확하게 찾아내고 설명하며 대안을…

병원 설문지가 대화로 바뀐다…GPT가 환자 문진표를 대신 작성하는 시대
병원에서 긴 설문지를 작성하느라 손목이 아픈 경험, 누구나 있을 것이다. 특히 허리 통증으로 병원을 찾은 환자라면 40개가 넘는 질문에 답하는 일은 고역이다. 하지만 이제…

챗GPT가 소설을 먹고 자란다? AI 학습 데이터에 숨겨진 ‘픽션의 비밀’
챗GPT와 같은 생성형 AI가 사람처럼 자연스럽게 대화하는 비결이 무엇일까? 놀랍게도 그 답은 ‘소설’에 있다. 일리노이대학교와 듀크대학교 연구진이 발표한 논문에 따르면, 대규모 언어 모델(LLM)의 학습…

AI 데이터센터의 ‘친환경’ 선언, 전력망을 들여다보면 허상이다
챗GPT(ChatGPT)가 세상에 등장한 2022년 이후, AI 산업은 폭발적으로 성장했다. 그 이면에는 엄청난 전력 소비라는 그림자가 드리워져 있다. 마이크로소프트(Microsoft)는 2028년까지 스리마일 아일랜드 원자력 발전소를 재가동하기로…

챗GPT가 강박장애 환자를 더 아프게 만든다, ‘안심 로봇’의 위험한 진실
요즘 많은 사람들이 ChatGPT(챗GPT) 같은 AI에게 궁금한 것을 물어본다. 그런데 이 AI가 특정 환자들에게는 오히려 독이 될 수 있다는 연구 결과가 나왔다. 미국 조지아…

별점만 믿다간 낭패! ChatGPT가 470만 개 리뷰를 파헤쳐 밝혀낸 ‘맛집의 진짜 조건’
“음식은 별로였는데 별점은 4점?” 온라인 리뷰를 보다 보면 이런 의문이 드는 순간이 있다. 별점 하나가 레스토랑 매출을 5~9%나 바꿀 만큼 리뷰의 영향력은 커졌지만, 정작…

월 20달러짜리 챗GPT로 수학 난제 풀었다…’바이브 증명’의 충격적 실험
수학은 오랫동안 AI가 넘기 어려운 벽으로 여겨졌다. 논리적 완결성이 요구되는 수학 증명은 단 하나의 오류도 전체를 무효화할 수 있기 때문이다. 그런데 벨기에 브뤼셀자유대학교(Vrije Universiteit…

챗GPT가 통계학 교육을 뒤흔들고 있다: 대학 강의실에서 벌어지는 AI 혁명
챗GPT가 대학 강의실을 뒤흔들고 있다. 학생들이 제출한 과제가 직접 작성한 것인지, AI가 만들어준 것인지 교수들이 구분하기 어려워진 시대가 됐다. 글래스고 대학교(University of Glasgow) 통계학과…

“ChatGPT가 편향됐다”는 말 한마디에 설득력 28% 급락
AI가 정치 전쟁에 휘말리고 있다. 챗GPT가 정치적으로 편향됐다는 경고를 받은 사람들은 같은 AI와 대화해도 설득당할 확률이 28%나 낮아진다는 연구 결과가 나왔다. 네덜란드 레이던대학교(Leiden University)…