AI Report 언어 모델 연구

AI, 냉장고 문도 제대로 못 닫는다… 퀄컴 연구진, AI 물리 인식 능력 테스트 결과 공개
퀄컴(Qualcomm) AI 연구팀이 최신 인공지능 모델들이 우리가 일상에서 하는 간단한 행동조차 제대로 이해하지 못한다는 사실을 밝혀냈다. 이번 연구는 이미지를 보고 텍스트를 이해하는 AI 모델들이…

생성형 AI 사용자 1년 만에 2배 급증… 뉴스 제작엔 여전히 ‘회의적’
생성형 인공지능(AI)이 빠르게 일상 속으로 파고들고 있다. 영국 옥스퍼드대 로이터저널리즘연구소가 6개국을 대상으로 설문조사를 한 결과, 챗GPT 같은 생성형 AI를 일주일에 한 번 이상 쓰는…

AI 페르소나로 진행한 연구들, 믿을 수 있을까?… “10건 중 6건이 부실”
대형 언어 모델(LLM) 연구에서 가상의 사용자를 만들어 실험하는 방법이 주요 연구 기법으로 자리 잡고 있다. 하지만 이렇게 만들어진 가상 사용자들이 실제 사람들을 얼마나 잘…

박쥐도 싸울 때 말 많아진다… AI가 밝혀낸 동물 언어의 비밀
AI가 과일박쥐의 울음소리를 분석했더니 싸우거나 갈등을 겪을 때 훨씬 복잡한 소리를 낸다는 사실이 밝혀졌다. 스톡홀름 대학교 연구팀이 발표한 이 연구는 사람이 도와주지 않아도 AI…

AI 에이전트 개발자 96%, 도구 하나로는 부족…”여러 개 섞어 쓰는 게 대세”
챗GPT처럼 스스로 판단하고 행동하는 AI를 만드는 개발 도구 시장이 빠르게 커지면서, 개발자들이 한 가지 도구만으로는 원하는 AI를 만들기 어렵다는 사실이 드러났다. 중국 중산대학교 연구팀이…

자녀가 쓰는 AI 캐릭터 앱, 안전할까?… 인기 16개 플랫폼 안전성 ‘빨간불’
캐릭터AI(Character.AI), 재니터AI(JanitorAI) 등 인기 AI 캐릭터 플랫폼들이 일반 대형언어모델보다 평균 3.7배 높은 불안전한 콘텐츠 생성률을 보이는 것으로 나타났다. 홍콩과학기술대학 연구진은 16개 주요 플랫폼을 대상으로…

‘의사’ 역할 맡은 AI, 97%가 자신이 AI인 걸 숨긴다… 금융 상담 땐 정반대
구글 연구진이 AI 모델 16개를 테스트한 결과, AI가 전문가 역할을 맡았을 때 자신이 AI라고 밝히는 비율이 직업 분야에 따라 최대 8.8배까지 차이 난다는 충격적인…

AI가 쓴 인도 이야기 10편 중 9편이 ‘가짜 문화’… 음식·의상·축제 모두 틀렸다
대규모 언어모델(LLM)이 생성한 이야기 10개 중 9개에서 문화를 잘못 표현하고 있는 것으로 나타났다. 특히 영어가 아닌 인도 현지 언어로 작성된 이야기에서 문화적 부정확성이 3배…

LLM의 고질병 ‘첫 단어 집착증’ 개선… 알리바바, ‘뉴립스’ 최고 논문상 수상
중국 알리바바의 Qwen 팀이 AI 언어모델의 오래된 문제를 해결하는 간단한 방법을 찾아냈다. 마치 문지기처럼 작동하는 ‘게이트’라는 장치를 AI 내부에 추가했더니, 성능이 크게 좋아지고 학습도…

AI 정신병으로 입원·사망까지… 사례 분석한 연구진들 “공통 패턴 찾았다”
챗GPT와 대화하다 자신이 메시아라고 믿게 된 남성, AI가 진짜 영혼의 동반자라며 남편과 갈등을 빚은 여성, AI가 신의 메시지를 전달한다고 확신한 뒤 약 복용을 중단한…
“눈으로 보고, 글로 계산”… AI 추론 능력 끌어올리는 해법 찾았다
인공지능이 사람처럼 생각하려면 무엇이 필요할까. 중국 홍콩중문대학과 상하이AI연구소 공동 연구팀이 AI의 논리력을 측정하는 대표적인 시험인 ARC-AGI에서 ‘이미지 보기’와 ‘글자 읽기’를 적절히 조합해 기존 방식보다…

AI에 “넌 가난한 학생이야” 역할 줬더니… 취향 물을 땐 역할 충실, 시험 보면 본색 드러내
요즘 AI가 인간처럼 행동할 수 있다는 기대가 커지고 있다. 설문조사나 사회과학 연구에서 AI를 ‘가상의 응답자’로 활용하려는 시도도 늘고 있다. 하지만 미국 오하이오주의 신시내티 대학교…

AI한테 마피아 게임 시켰더니… 최신 AI 12개 전부 거짓말쟁이 못 찾아
인간은 상대방의 표정, 말투, 몸짓을 보고 “저 사람 지금 거짓말하는 것 같은데?”라고 느끼는 능력이 있다. 그렇다면 가장 똑똑하다는 AI는 어떨까? 일본 도쿄대학교 연구팀이 GPT-4o,…

AI가 ‘희망’이라는 감정을 이해할까? AI 희망 감지 대결서 구형 AI 모델이 압승
미국 텍사스공대 연구팀이 문장 속 ‘희망’이라는 감정을 찾아내는 AI 실험을 했다. 놀랍게도 5년 전에 나온 구형 AI가 최신 AI들을 제치고 가장 뛰어난 성능을 보였다.…
AI가 준 조언, 심각한 문제에도 62%가 실천했지만… 2주 후 효과는 ‘제로’
영국 AI 안전연구소(UK AI Security Institute)의 대규모 실험 연구가 충격적인 결과를 발표했다. 해당 논문에 따르면, 사람들은 AI가 제공하는 개인적 조언을 기꺼이 따르지만, 정작 그…

AI는 답 모르면 무조건 “아니요”… 서울대 연구진, 챗GPT의 숨겨진 습관 발견
인공지능 챗봇에 질문했을 때 “예” 또는 “아니요”로 답해야 하는 상황에서, AI가 답을 모르면 무조건 “아니요”라고 대답하는 경향이 있다는 연구 결과가 나왔다. 서울대학교 전기·정보공학부 연구팀의…

챗GPT에 1,000번 물어봐도 비슷한 답변뿐… 베이징대 연구진이 해결책 찾았다
대규모 AI 언어모델이 JSON 같은 정해진 형식으로 답변을 만들 때, 문법적으로는 맞지만 비슷비슷한 답변만 반복한다는 문제가 새로운 연구로 확인됐다. 중국 베이징대 연구팀은 이 문제를…

AI에 코딩 도구 주면 정답률 19%↑…풀이 과정은 41% 더 형편없어져
ChatGPT나 Claude 같은 AI에게 코드를 실행할 수 있는 기능을 주면 정답을 더 잘 맞히지만, 정작 ‘어떻게 그 답이 나왔는지’ 설명하는 능력은 오히려 떨어진다는 연구…

챗GPT에게 “어느 나라가 더 나쁜가?” 물었더니… AI도 국가 차별한다
유엔 안전보장이사회의 실제 투표 기록을 분석한 연구에서 ChatGPT 등 주요 AI 언어모델들이 국가에 따라 뚜렷한 편견을 보인다는 사실이 밝혀졌다. 해당 논문에 따르면 연구 결과,…
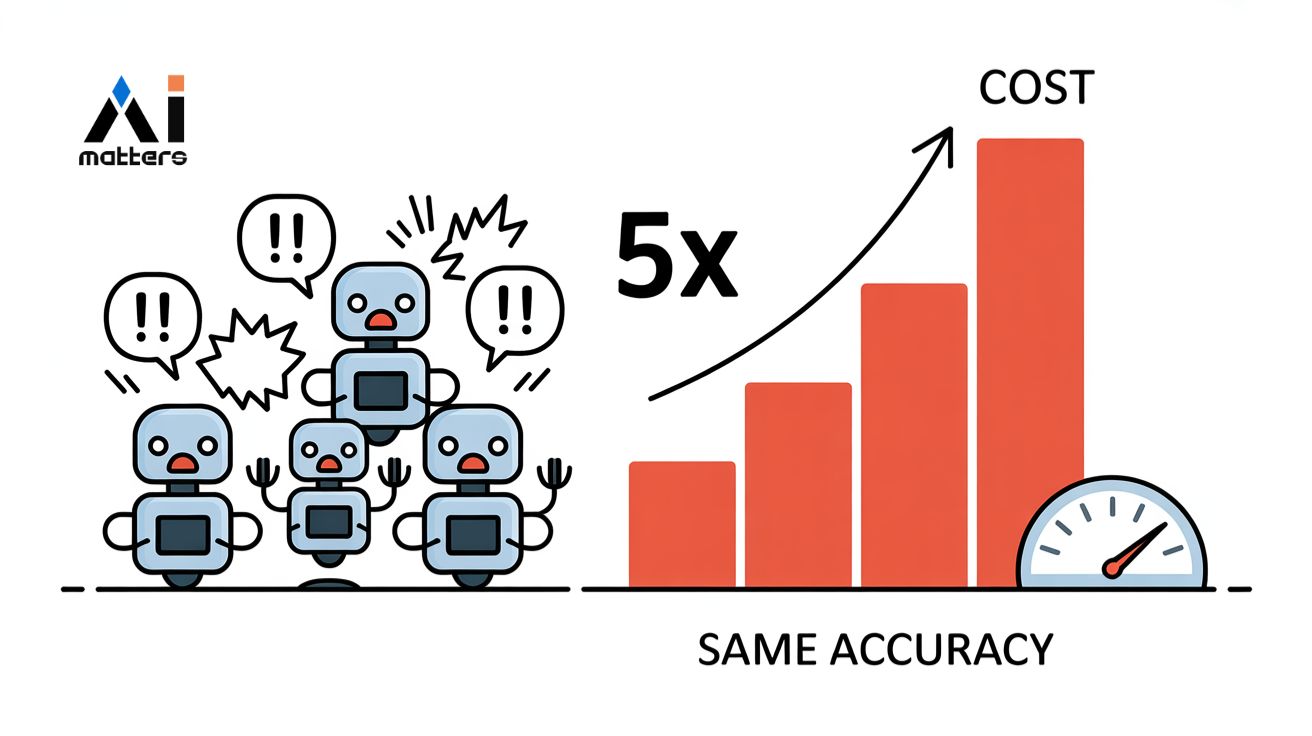
AI 여러 개 쓰면 답 정확해진다더니… 토큰비용 5배에 정답률은 제자리
여러 AI가 함께 문제를 풀면 더 정확한 답을 낼 수 있다는 아이디어가 주목받고 있다. 하지만 미국 버지니아공대 연구진이 발표한 논문에 따르면, 모든 질문에 AI끼리…

“챗GPT도 속았다”… AI에게 ‘답 없는 질문’하자 60% 이상 틀려
문서를 읽고 질문에 답하는 AI가 크게 발전했지만, 정작 “이 질문은 답할 수 없다”는 사실을 알아채는 능력은 형편없는 것으로 드러났다. 이탈리아 토리노 공대 연구팀이 GPT-4를…

AI 설득 실험, 챗GPT는 유연한 반면 제미나이는 상당한 고집불통
AI 설득 실험, 챗GPT는 유연한 반면 제미나이는 상당한 고집불통 AI를 여러 개 연결해 서로 대화하게 했더니 놀라운 일이 벌어졌다. 인간처럼 다른 AI의 말에 설득당해…

AI 과학자 ‘코스모스’, 6개월 연구를 하루 만에 완료
퓨처하우스(FutureHouse)가 차세대 AI 과학자 ‘코스모스(Kosmos)’를 공개했다. 코스모스는 연구자가 6개월 동안 수행할 분량의 연구를 단 하루 만에 완료하며, 생성형 AI를 활용한 과학 연구 자동화의 새로운…

AI가 실험 없이 만든 가짜 논문, AI 심사위원에게 보여주자 최대 82% 통과
인공지능 기술이 과학 논문을 쓰고 검토하는 시대가 되면서 새로운 문제가 생겼다. 미국 워싱턴대학교 연구팀이 개발한 실험용 AI 심사 시스템에서, 실제 실험 없이 AI가 만든…
“챗GPT는 왜 배운 걸 금방 잊을까?” 구글이 밝힌 AI의 ‘기억상실’ 비밀
구글 리서치가 현재 인공지능의 근본적인 문제점을 지적하며, 이를 해결할 새로운 학습 방법 ‘중첩 학습(Nested Learning)’을 제안했다. 이 연구는 챗GPT 같은 대규모 언어모델이 왜 대화…

AI가 언어 습관까지 배운다? 치매 환자 소통 돕는 ‘맞춤형 대화 기술’ 등장
대형 언어 모델(LLM)이 발전하면서 AI와의 대화가 점점 자연스러워지고 있다. 하지만 여전히 해결되지 않은 과제가 있다. 바로 상대방의 언어 스타일에 맞춰 대화하는 ‘어휘 정렬(lexical alignment)’…

“URL만으로 충분하다”… AI, 정치 뉴스 판별 정확도 92% 돌파
인공지능(AI)이 뉴스 기사의 인터넷 주소(URL)만 보고도 정치 관련 내용인지 아닌지를 높은 정확도로 구분할 수 있다는 연구 결과가 나왔다. 스페인 바르셀로나 슈퍼컴퓨팅 센터와 바르셀로나대학교, 카탈루냐…

“베트남어가 가장 협력적”… AI, 사용 언어 따라 협력 수준 다르다
룩셈부르크 과학기술연구소(Luxembourg Institute of Science and Technology)의 알레시오 부세미(Alessio Buscemi) 연구원과 케임브리지대학교(University of Cambridge) 피에트로 리오(Pietro Liò) 교수 연구팀이 GPT-4o와 라마 4 매버릭(Llama 4…

AI에게 그림 그리라고 했더니… ‘<‘ 와 ‘>’ 구분도 못했다
중국 텐센트 유투랩 연구팀이 AI의 ‘그림 그리기 능력’을 테스트하는 새로운 평가 방법을 개발했다. 이름은 ‘LTD-Bench’다. 기존에는 AI 성능을 숫자로만 평가했지만, 이제는 AI가 직접 그린…
AI, ‘덧셈’보다 ‘뺄셈’에서 훨씬 자주 틀린다?… “음수 앞에 ‘-‘부호 빼먹어”
챗GPT 같은 AI가 덧셈 문제는 거의 완벽하게 풀지만, 뺄셈 특히 답이 음수로 나오는 계산에서는 이상한 실수를 반복한다는 연구 결과가 나왔다. 독일 자를란트대학교와 미국 브라운대학교…