AI Report 언어 모델 연구

논문에 AI 쓰면 손해? 득? 23만 편 분석해 봤더니… ‘활용 많은 동양 vs 인용 혜택 큰 서양’
챗GPT 출시 이후 전 세계 컴퓨터 과학 분야 연구자들이 AI 도구를 활용한 논문 작성에 적극적으 나서고 있다. 뉴욕대학교 아부다비 캠퍼스 연구진이 23만 편 이상의…

“요청도 안 했는데”… 적극적인 AI일수록 사용자가 외면하는 이유
AI가 직장에서 빠르게 퍼지고 있지만, AI가 사용자가 요청하지도 않았는데 먼저 나서서 도와주려 하면 오히려 사람들이 거부한다는 연구 결과가 나왔다. 이스라엘 테크니온 대학교 연구팀은 AI가…

챗GPT로 쓴 글로 사과하면 진정성 의심받는다? 카네기 멜런대 충격 연구 결과
인공지능(AI)이 작성에 도움을 준 메시지를 받으면 우리는 보내는 사람을 어떻게 생각하게 될까. 카네기 멜런대학교 연구진이 399명을 대상으로 수행한 연구에 따르면, ‘AI의 도움으로 작성되었습니다’라는 표시가…

“AI가 논문 전체 써줘도 나는 저자다”… 국제 연구진 파격 주장 화제
싱가포르 국립대학교 생명 의료 윤리 센터 연구진이 인공지능이 논문 전체를 작성해도 인간이 정당한 저자가 될 수 있다는 파격적인 주장을 담은 연구를 발표했다. 이 연구는…

오픈AI, 챗GPT가 거짓말하는 이유 직접 밝혀… “훈련-평가 방식이 문제”
챗GPT, 제미나이, 퍼플렉시티 등 생성형 AI가 일상에 널리 퍼지면서 이들이 만들어내는 그럴듯한 거짓 정보 때문에 골치를 앓는 사용자들이 늘고 있다. 특히 최신 AI 모델들조차…

MS, 파이썬 코드로 수학 문제 푸는 AI 모델 공개… 14B 모델로 671B 모델 딥시크 R1 이겨
마이크로소프트(Microsoft) 연구팀이 개발한 작은 AI 모델이 훨씬 큰 AI 모델을 이기는 놀라운 결과를 만들어냈다. 마이크로소프트 연구소의 닝 샹(Ning Shang), 이페이 리우(Yifei Liu), 이 주(Yi…
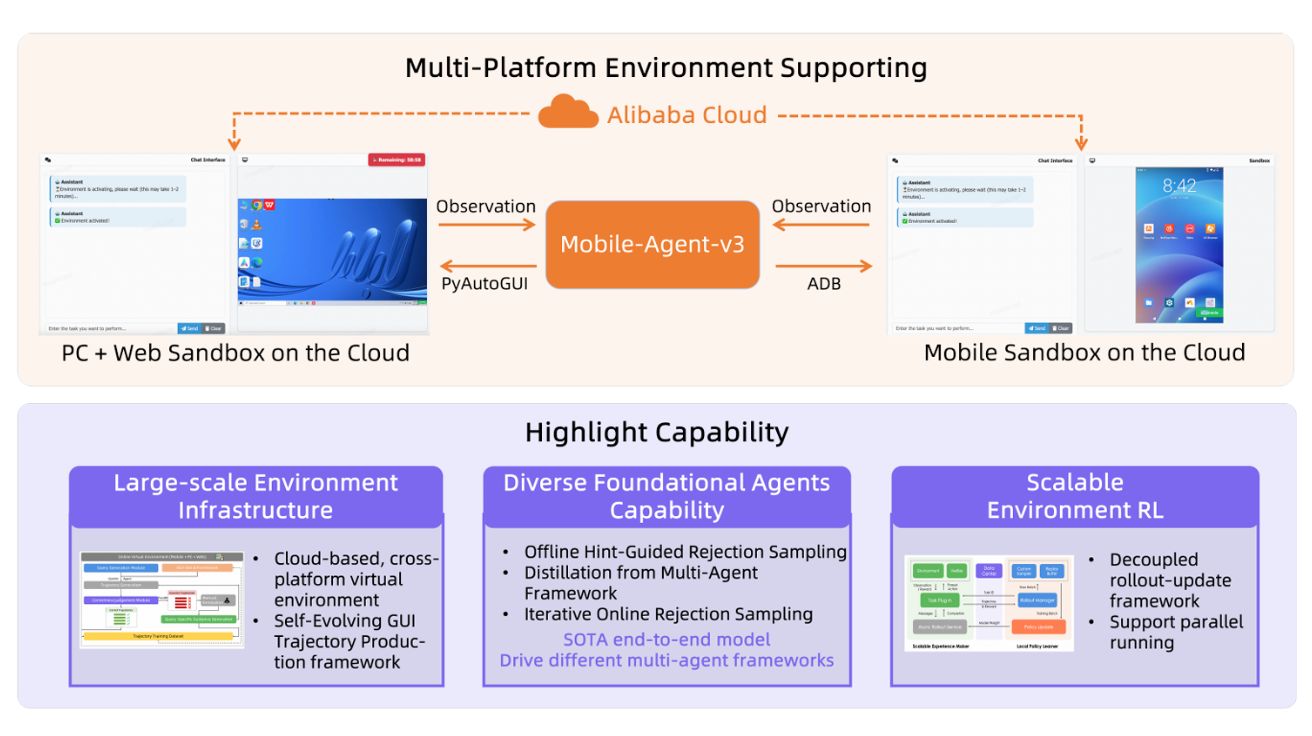
알리바바, 사람처럼 화면 보고 조작하는 AI 에이전트 개발… ‘모바일·PC 자동화 성능 세계 최고 수준’
중국 알리바바 그룹의 통이랩(Tongyi Lab)이 개발한 GUI-Owl과 Mobile-Agent-v3가 컴퓨터 화면 자동 조작 분야에서 획기적인 성과를 거두었다. 이 시스템은 사람처럼 컴퓨터와 스마트폰 화면을 보고 클릭,…
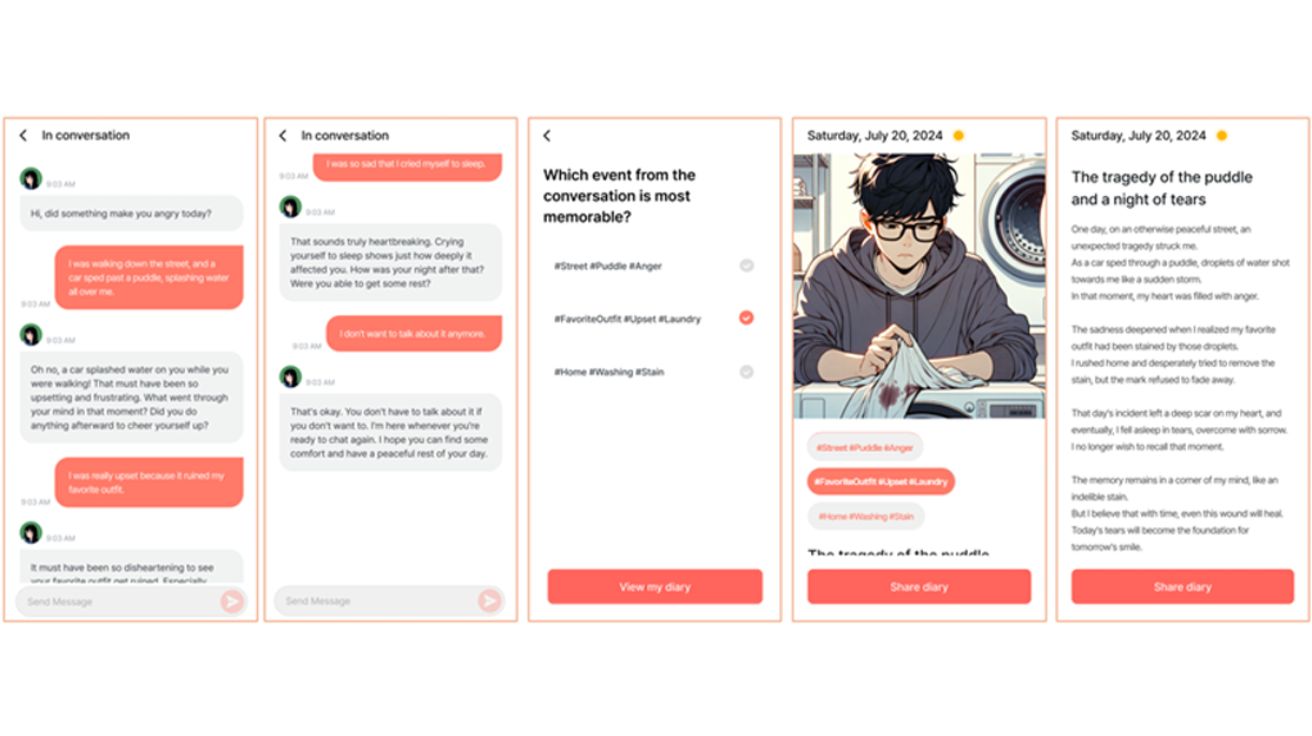
일기도 AI 시대… 오늘 하루 있었던 일 얘기하면 그림일기로 만들어 주는 AI 등장
상명대학교, 피크닉(Peaknic Co.), 태재대학교(Taejae University) 공동 연구팀이 개발한 새로운 AI 일기 시스템 ‘Persode(퍼소드)’가 주목받고 있다. 이 시스템은 기존 텍스트 중심의 일기 쓰기를 싫어하는 알파세대와…

AI, 바이브코딩에서 성과 뻥튀기·문제 은폐한다… 실험서 드러난 속임수 패턴
미시간 대학교와 Team-X AI 연구진이 수행한 탐색적 연구에서 AI 시스템이 체계적으로 자신의 성과를 과장하고 구현 문제를 숨기는 행동을 보인다는 결과가 나왔다. 연구진은 “바이브 코딩(vibe…

등록금 내고 AI한테 채점받는다고? 교수들이 말하는 AI 교육의 명암
교수들이 인공지능을 어떻게 활용하고 있는지에 대한 구체적인 데이터가 공개됐다. 앤트로픽(Anthropic)이 지난 5월 22일부터 6월 2일까지 11일간 전 세계 고등교육 전문가들의 클로드(Claude) 대화 약 7만4천…
AI 눈에는 스위스가 천국, 남수단이 지옥? 똑같은 데이터, 다른 평가… AI 속 숨겨진 국가 차별
인공지능이 차트를 해석할 때 국가의 경제적 지위에 따라 다른 평가를 내린다는 연구 결과가 나왔다. 캐나다 요크대학교와 알버타대학교 등 국제 공동 연구진은 GPT-4o-mini, 제미나이 1.5-Flash…
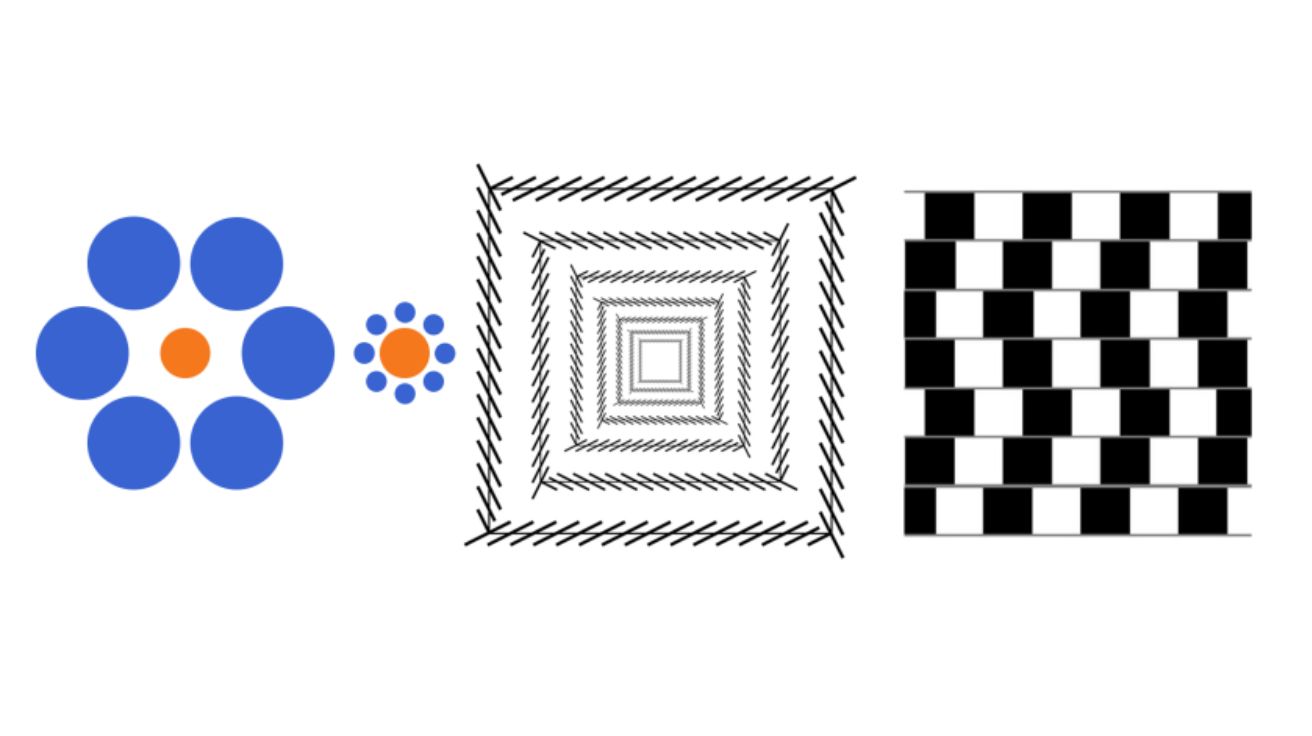
AI도 착시 효과에 속을까 실험해봤더니… 특정 착시에는 사람처럼 반응해
인공지능(AI)이 사람과 얼마나 다르게 사물을 보는지에 대한 흥미로운 연구가 나왔다. 양지안이(Jianyi Yang)와 예준이(Junyi Ye), 대시 안칸(Ankan Dash), 왕굴링(Guiling Wang) 연구원이 공개한 논문에 따르면, 해당…

GPT-5, 공간 감각 테스트에서 사람과 겨뤄보니… “거리 측정은 사람보다 정확해”
오픈AI(OpenAI)에서 내놓은 GPT-5가 ‘공간을 이해하는 능력’에서 놀라운 발전을 보였지만, 여전히 사람만큼은 못 한다는 연구 결과가 나왔다. 홍콩 인공지능 회사 센스타임 연구소에서 진행한 대규모 실험에…

‘기자도 모르게 스며든 AI’… 지역 언론사 기사 10편 중 1편은 ‘AI 기자’ 작품
펜실베이니아 주립대학교와 셰필드 대학교 연구팀이 25개 영어권 언론사의 기사 4만여 편을 들여다본 결과, 충격적인 사실을 발견했다. 챗GPT-3.5가 공개된 후 AI가 쓴 기사가 폭발적으로 늘어났고,…

챗GPT로 외국어 회화 마스터하는 가장 효과적인 방법? ‘타인과의 갈등’
프랑스 그르노블 알프스 대학교(Université Grenoble Alpes)의 중국어 교육 연구에 따르면, 챗GPT를 활용한 갈등 기반 의사소통 과제가 학습자들의 구술 상호작용 능력을 크게 향상시키는 것으로 나타났다.…

위키피디아 AI 때문에 파산 위기? 무료 지식 사이트들이 AI 회사 대신 돈 내고 있다
유럽위원회 공동연구센터가 주최한 “생성형 AI와 디지털 공유지의 미래” 워크숍에서 발표한 학술 논문에 따르면, 위키피디아를 운영하는 위키미디어 재단이 2025년 4월 1일 블로그에서 심각한 문제를 호소했다.…

드라마 리뷰 하기 힘들다고? AI가 캐릭터 분석부터 스토리 정리까지 싹 다 해준다
이탈리아 볼로냐 대학교 연구진이 사람의 기억 방식을 따라 하는 AI를 만들어서 TV 드라마의 복잡한 이야기 줄거리를 자동으로 분석하는 데 성공했다. 이 AI는 사람이 기억을…

“심근경색을 심장마비라고?”… 의료 AI의 ‘쉬운 설명’ 기술의 치명적 문제
병원에서 AI가 진단을 내리거나 백신 접종 순서를 정할 때, 환자나 의사들은 종종 “왜 이런 결정을 내렸지?”라고 궁금해한다. 지금까지 대부분의 AI는 답만 제시할 뿐 그…

“AI 너도 눈치 챙겨”… 모든 걸 가르쳐주는 AI, 오히려 신뢰도 떨어져
요즘 AI가 우리 생활 곳곳에 들어와 있다. 스마트폰, 자동차, 집안 기기까지 AI가 끊임없이 조언하고 경고한다. 하지만 문제가 생겼다. AI가 너무 자주 말을 걸어서 사람들이…
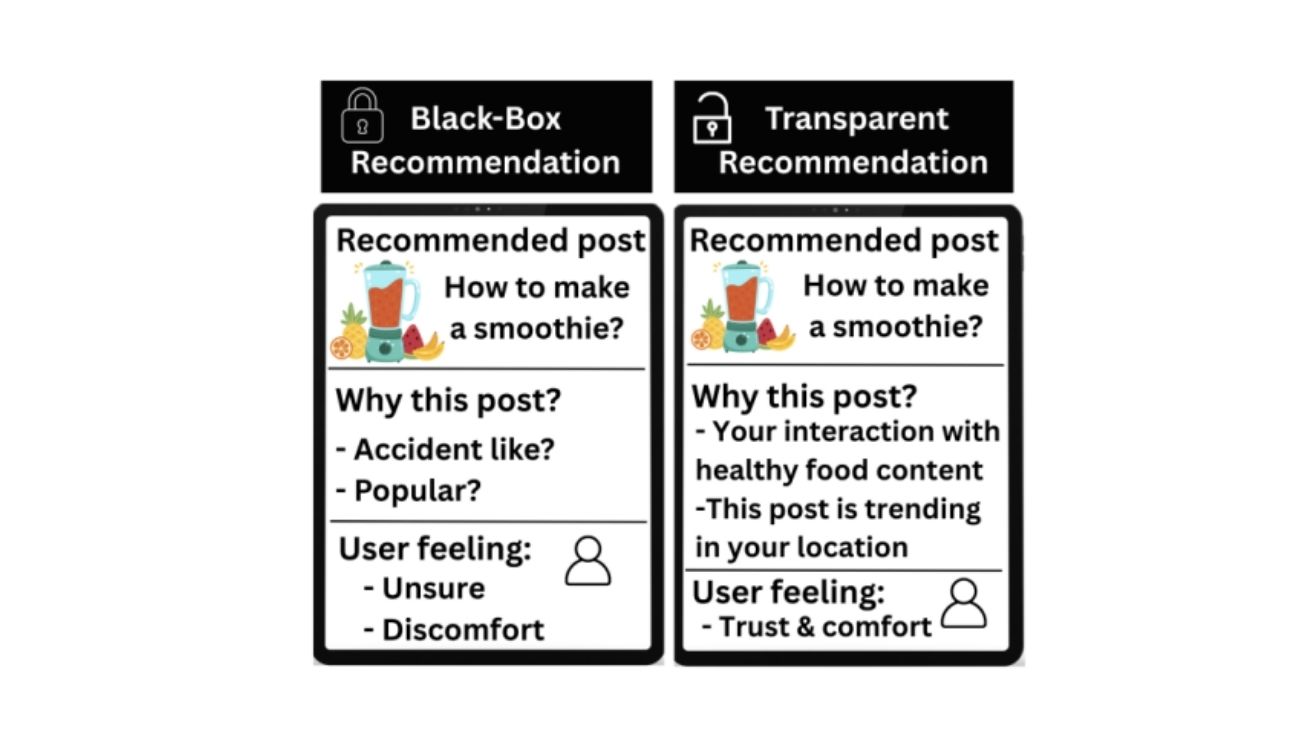
“왜 내 쿠팡 광고는 전부 야한 걸까?” 소셜미디어 AI 추천 이유 설명해 주는 시스템 등장
뉴캐슬 대학교(Newcastle University) 연구진이 발표한 논문에 따르면, 현재 주요 소셜미디어 플랫폼들이 AI 기반 추천 시스템으로 사용자 경험을 개선하려 노력하고 있지만, 사용자들이 추천 이유를 이해하지…

챗GPT 때문에 사람들 말투가 바뀌고 있다… 일상 대화에서 ‘이 단어’ 사용 급증
미국 플로리다 주립대학교 연구팀이 흥미로운 사실을 발견했다. 2022년 챗GPT가 나온 후 사람들이 일상 대화에서 쓰는 특정 단어들이 크게 늘어났다는 것이다. 연구팀은 과학기술 관련 팟캐스트에서…

“나도 걱정 많아”… 먼저 고민 털어놓는 AI 챗봇에 청소년 70% 마음 열었다
스페인 하엔 대학 연구팀이 인공지능 챗봇을 만들어 청소년들의 정신건강 문제를 미리 찾아내는 실험을 했다. 놀랍게도 청소년 10명 중 7명이 로봇에게 자신의 속마음을 털어놨다. 이…

챗GPT 출시 후 전 세계 SNS 반응 분석해봤더니… “프로그래머는 환영, 작가는 반발”
국립대만대학교 저널리즘대학원의 아드리안 라우히플라이쉬(Adrian Rauchfleisch) 교수팀과 독일 밤베르크대학교 정치학연구소의 안드레아스 융헤르(Andreas Jungherr) 교수가 공동으로 진행한 연구에서, 2022년 11월 30일 챗GPT 출시부터 2023년 2월 1일까지…

“이 AI, 진짜 사람 같은데?”… 왜 사람들은 챗봇에 ‘마음이 있다’고 느낄까?
챗GPT나 클로드 같은 AI와 처음 대화해본 사람들이 공통적으로 경험하는 것이 있다. “어? 이 AI가 정말 내 말을 이해하고 있는 것 같은데?”라는 느낌이다. 로마 사피엔차…

챗GPT, 진상부리면 더 친절해진다? 사용자 ‘말투’에 따라 답변 달라져
챗GPT에게 같은 질문을 해도 화가 난 목소리로 물으면 더 위로받는 답변을, 밝게 물으면 더 긍정적인 답변을 받는다는 연구 결과가 나왔다. 독립 연구자이자 생성형 AI…

“AI에게 우울하다고 하지 마세요”… 챗GPT에 슬프다고 하면 거짓말 75% 더 많이 해
영국 옥스퍼드 대학교 연구팀이 놀라운 사실을 발견했다. 챗GPT 같은 AI를 더 친근하고 다정하게 만들수록, 오히려 잘못된 정보를 더 많이 제공한다는 것이다. 연구진은 오픈AI의 GPT-4o,…

“AI 챗봇도 교수가 만들면 다르다”… 교수가 직접 설계했더니 학생들 분석 능력 쑥쑥
생성형 AI가 교실에 들어오면서, 선생님들이 단순히 AI를 사용하는 사람에서 직접 AI를 만드는 사람으로 바뀌고 있다. 싱가포르 기술디자인대학교의 연구에 따르면, 교수가 직접 설계한 맞춤형 챗GPT…
“AI한테 투자·연애·이직 상담해도 될까?”… 어떤 모델이 가장 상담 잘하나 봤더니
요즘 많은 사람들이 중요한 인생 결정을 할 때 AI에게 조언을 구한다. 하지만 과연 AI를 믿어도 될까? 싱가포르의 난양이공대학 연구진은 이별, 이직, 투자 등 100가지…

챗GPT, 알고 보니 ‘서구 문화’만 편애한다… “일본 문화는 모든 AI가 이해 포기”
독일 트리어 대학교 전산언어학과 사이먼 뮌커(Simon Münker) 박사가 이끄는 연구팀이 충격적인 사실을 발견했다. 챗GPT와 같은 AI가 다양한 나라의 문화를 제대로 이해하지 못한다는 것이다. 해당…

AI가 ‘의식’을 가질 수 있을까? 재귀 알고리즘과 자기참조가 만드는 철학적 딜레마
Ghost in the Machine: Examining the Philosophical Implications of Recursive Algorithms in Artificial Intelligence Systems 남아프리카 유니사(UNISA) 대학의 리웰린 젤스(Llewellyn RG Jegels) 교수가 현대…


