LLM보안

챗GPT, 제미나이 같은 AI 챗봇으로 컴퓨터 해킹할 수 있을까? 앤트로픽 실험 결과 충격
미국 카네기 멜론 대학교와 AI 회사 앤트로픽(Anthropic)이 함께 만든 특별한 연구가 화제다. 연구팀은 대규모 언어모델이 실제로 컴퓨터 해킹을 할 수 있는지 알아보기 위해 ‘MHBench’라는…
군사용 AI의 새로운 위험: 프롬프트 인젝션 공격의 실체와 대응책
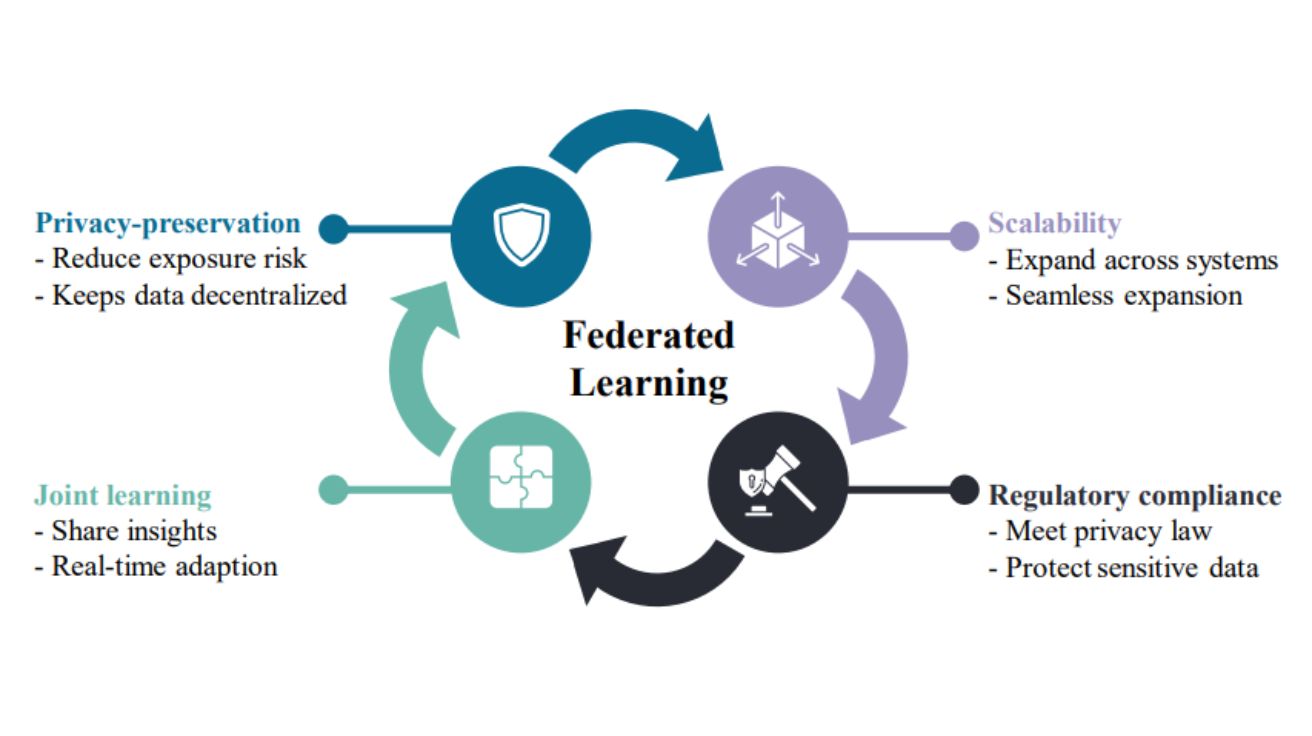
Exploring Potential Prompt Injection Attacks in Federated Military LLMs and Their Mitigation 카이스트 연구진이 발표한 논문에 따르면, 연합학습(Federated Learning) 기반의 군사용 대규모 언어모델(LLM)이 새로운…