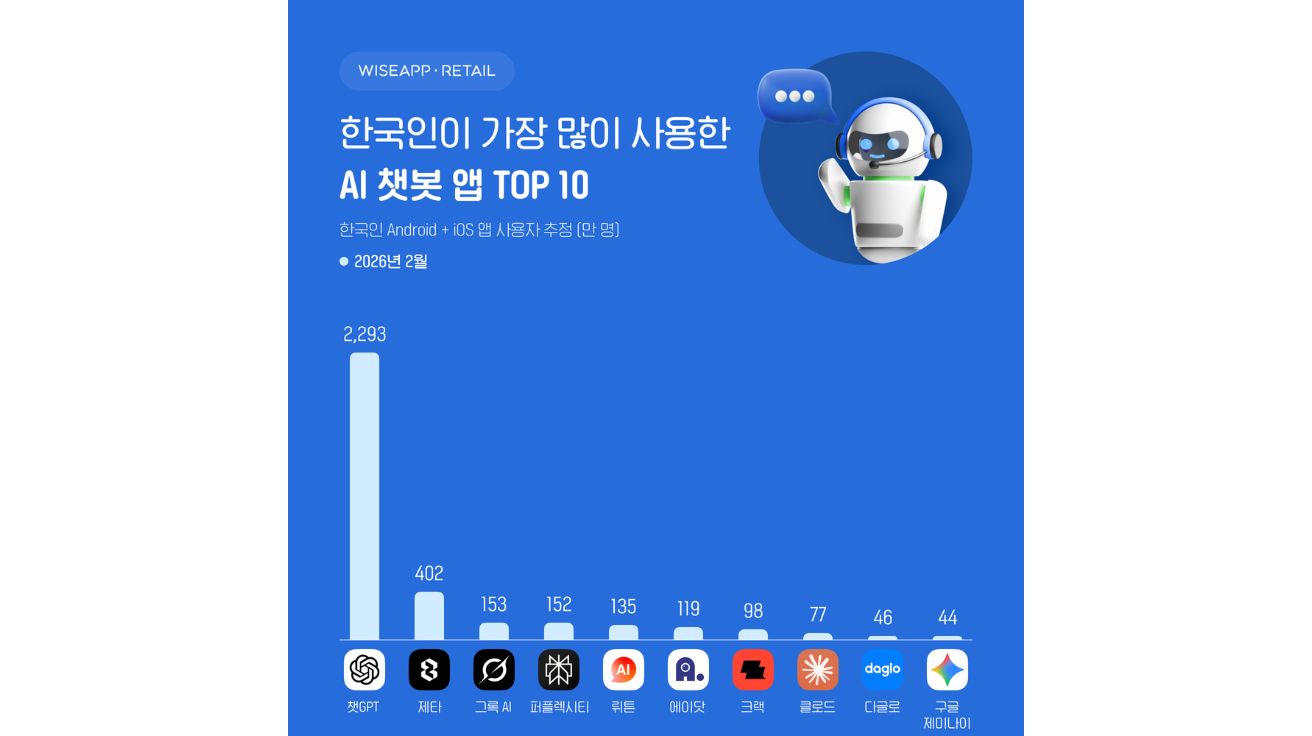
LLM 벤치마크
오픈AI, 의료용 챗GPT 만드나? 60개국 의사들이 참여한 ‘헬스벤치’ 공개
HealthBench: Evaluating Large Language Models Towards Improved Human Health 전 세계 60개국 262명 의사 참여, 5,000개 실제 의료 대화로 AI 성능 평가 오픈AI가 의료…

EU AI법 대응 첫 기술평가 프레임워크 ‘COMPL-AI’ 공개…12개 AI 모델 준수 여부 검증
ETH 취리히와 INSAIT 소피아 대학 연구진이 EU AI법을 기술적으로 해석하고 이를 평가할 수 있는 최초의 종합적인 프레임워크 ‘COMPL-AI’를 개발했다. 이 프레임워크는 생성형 AI의 성능과…

“AI의 ‘환각’을 잡아라” 미 연구진, 새로운 벤치마크 개발
인공지능(AI) 기술이 급속도로 발전하면서 대규모 언어 모델(LLM)의 정확성과 신뢰성이 중요한 이슈로 떠올랐다. 최근 코넬대학교, 워싱턴대학교, 앨런 인공지능 연구소 등의 연구진이 LLM의 사실성을 평가하기 위한…