LLM 보안

복잡한 해킹보다 ‘안녕하세요’가 더 위험? AI 공격 성공률 1위는 의외의 방법
LLM 유해성 공격 전략에 대한 실증적 분석 오픈AI의 챗GPT와 앤트로픽의 클로드 등 대규모 언어 모델(Large Language Models, LLMs)의 활용이 급격히 확대되면서, 이들 모델의 안전성에…

항공우주업계가 2025년 AI 상용화에 올인하는 이유
Artificial Intelligence in Aerospace and Defense 항공기 17,000대 생산 지체에 직면한 업계, AI로 생산혁신 모색 항공우주 및 방위(A&D) 산업이 심각한 생산능력 한계에 직면하면서 인공지능(AI)…

AI도 거짓말할 때 ‘티’가 난다… 유해 답변 생성 전 96% 사전 차단
SafetyNet: Detecting Harmful Outputs in LLMs by Modeling and Monitoring Deceptive Behaviors AI의 ‘나쁜 생각’ 미리 알아채는 기술, 96% 정확도 달성 옥스포드 대학교(University of…
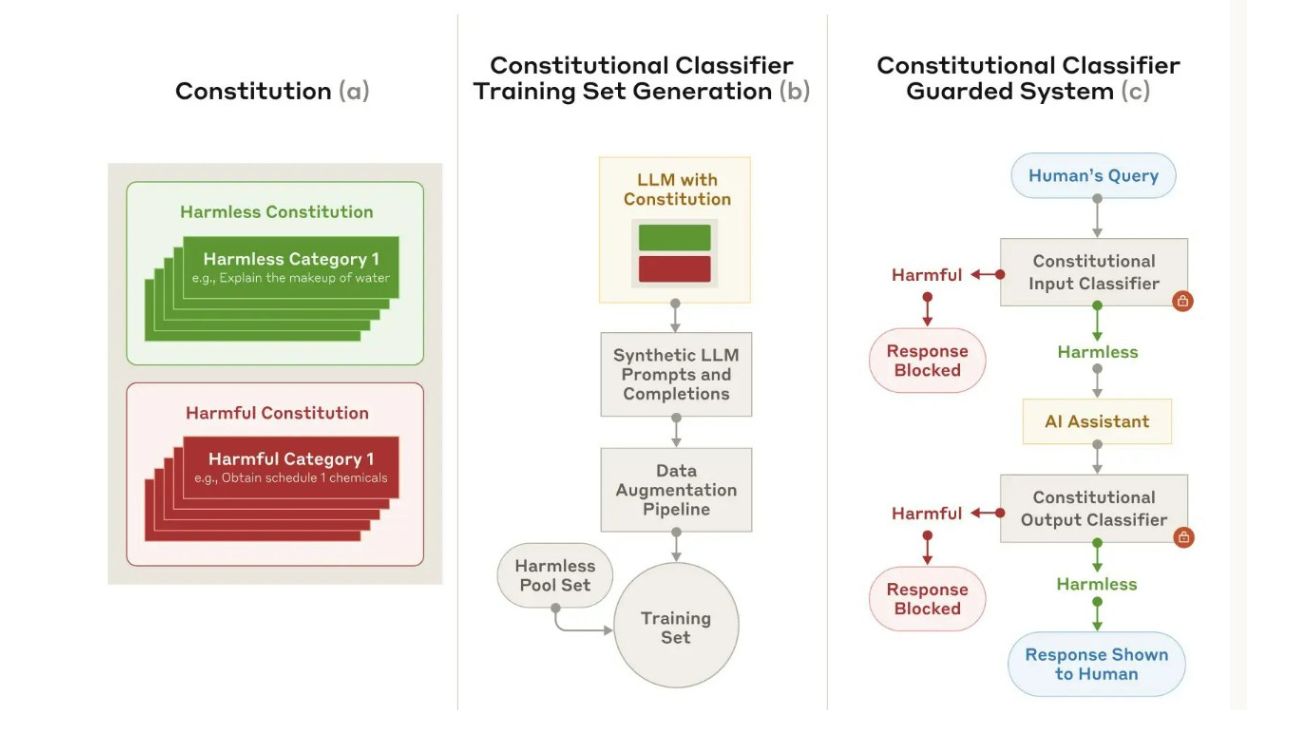
AI 안전성 높이는 ‘헌법 분류기’ 개발…앤트로픽 연구진, 3000시간 해킹 시도 막아내
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming 인공지능 연구기업 앤트로픽(Anthropic)이 대규모 언어모델(LLM)의 안전성을 획기적으로 강화하는 기술을 개발했다. 앤트로픽의…

마이크로소프트가 밝힌 AI 안전성의 현주소…인간의 판단이 더욱 중요해진다
Lessons from red teaming 100 generative AI products AI 레드팀이 발견한 8가지 핵심 교훈 마이크로소프트 AI 레드팀(AIRT)이 100개 이상의 생성형 AI 제품을 테스트한 결과를…
AI 안전성 우회하는 ‘AutoDAN-Turbo’, LLM 공격 성공률 최대 93.4% 달성
대규모 언어 모델(Large Language Models, LLM)의 급속한 발전과 함께 이를 악용하려는 시도 또한 증가하고 있다. 최근 위스콘신 매디슨 대학을 중심으로 한 연구진이 개발한 ‘AutoDAN-Turbo’라는…


