RLVR

“정답 몰라도 괜찮다”… AI 강화학습의 상식을 뒤엎은 워싱턴대 연구
Spurious Rewards: Rethinking Training Signals in RLVR 무작위 보상만으로 21.4% 성능 향상, 틀린 답 보상해도 24.6% 상승 강화학습 분야에서 놀라운 연구 결과가 발표됐다. 워싱턴대학교와…
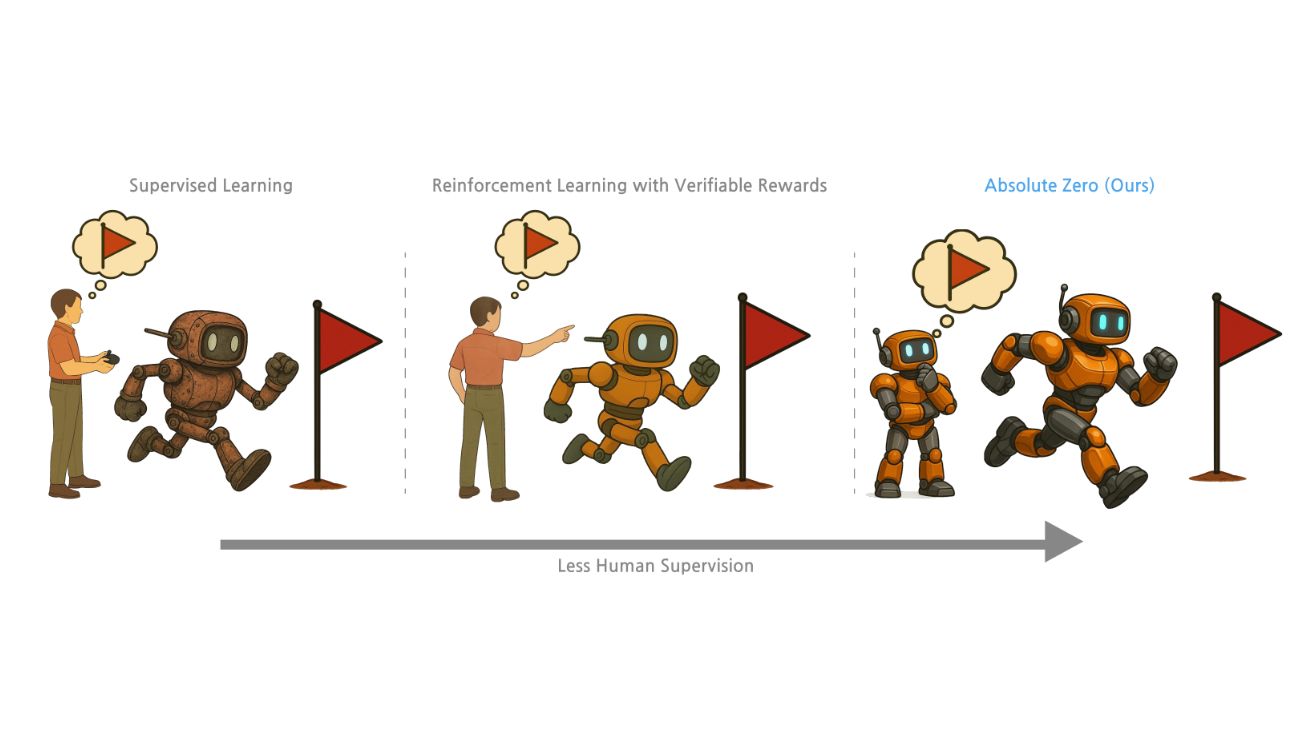
AI의 자기계발 시대? 사람이 제공한 데이터 없이 코딩과 수학 마스터한 추론 모델의 등장
Absolute Zero: Reinforced Self-play Reasoning with Zero Data 스스로 문제 내고 푸는 AI: 인간 데이터 의존성 탈피한 새로운 추론 모델 대규모 언어 모델(LLM)의 추론…


