
Lower Latency and Higher Throughput with Multi-Node DeepSeek Deployment
8개 A100 GPU로 지연시간 20% 단축, 처리량 8배 증가한 퍼플렉시티의 멀티노드 전략
퍼플렉시티(Perplexity)가 멀티노드 환경에서 대규모 언어 모델인 딥시크(DeepSeek)를 배포하여 지연시간을 줄이고 처리량을 높이는 데 성공했다. 퍼플렉시티 엔지니어링 팀은 딥시크 모델을 8개의 A100 GPU에 분산 배포하는 방식을 채택했으며, 이를 통해 지연시간을 약 20% 줄이고 처리량은 8배 증가시켰다. 이러한 접근법은 대규모 AI 모델을 효율적으로 운영하고자 하는 기업들에게 중요한 참고 사례가 될 것으로 보인다.
퍼플렉시티가 자사 블로그에 공개한 연구 보고서에 따르면, 퍼플렉시티는 딥시크 모델의 규모가 커짐에 따라 단일 머신에서의 처리가 어려워지는 문제를 해결하기 위해 텐서 병렬 처리(tensor parallelism)와 파이프라인 병렬 처리(pipeline parallelism)를 결합한 접근법을 사용했다. 이러한 분산 배포 전략은 메모리 부담을 여러 장치에 분산시키고 동시에 모델의 성능을 높이는 결과를 가져왔다.
텐서 병렬 처리로 초당 135만 토큰 처리, 대규모 AI 모델의 메모리 한계 극복
퍼플렉시티는 딥시크 모델 배포를 위해 두 가지 주요 병렬 처리 기법을 활용했다. 먼저 텐서 병렬 처리는 모델의 각 층을 여러 GPU에 분산시켜 메모리 사용량을 줄이는 방식이다. 이는 특히 대규모 모델의 가중치 매개변수가 단일 장치의 메모리 용량을 초과할 때 유용하다. 한편 파이프라인 병렬 처리는 모델의 다른 층들을 여러 장치에 분산시켜 각 장치가 모델의 특정 부분만 담당하도록 한다.
퍼플렉시티 팀은 딥시크 모델 배포에 vLLM 프레임워크와 함께 텐서 병렬 처리를 채택했으며, 이를 통해 단일 노드 배포에 비해 지연시간이 약 20% 감소했다. 특히 주목할 만한 점은 배치 크기가 증가함에 따라 처리량이 크게 향상되어, 배치 크기가 1024일 때 초당 약 135만 개의 토큰을 처리할 수 있게 되었다는 것이다.
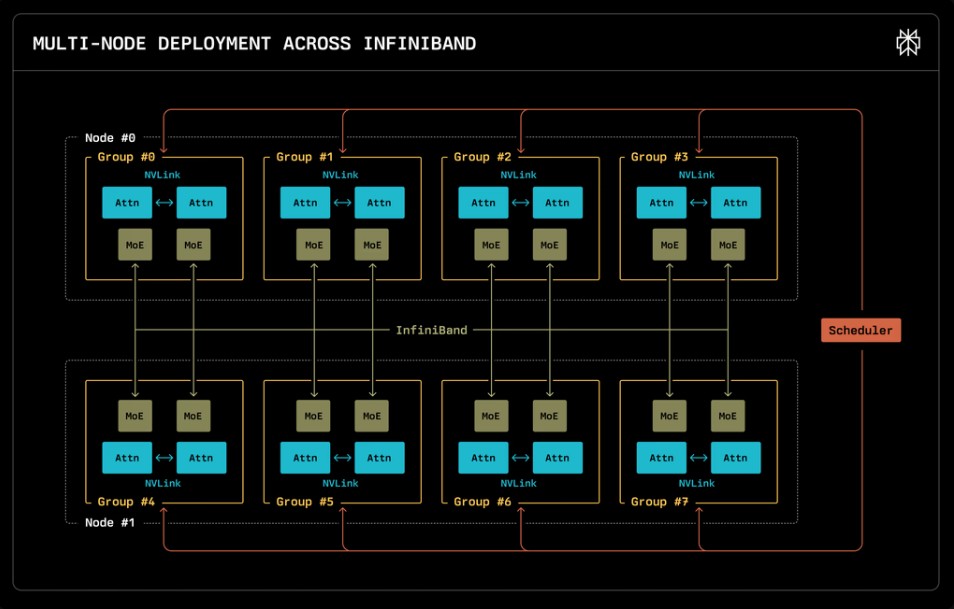
vLLM 프레임워크와 레이 클러스터로 구축한 8웨이 텐서 병렬 최적 배포 환경
퍼플렉시티는 딥시크 모델의 멀티노드 배포를 위해 vLLM 프레임워크를 활용했다. vLLM은 주요 AI 모델 서빙 프레임워크 중 하나로, 페이지드 어텐션(paged attention)과 연속 배치 처리(continuous batching)를 지원하여 모델 추론 효율성을 높인다. 퍼플렉시티는 이 프레임워크에 멀티노드 지원 기능을 개발하여 기여했으며, 이를 통해 딥시크와 같은 대규모 모델을 여러 노드에 효율적으로 배포할 수 있게 되었다.
퍼플렉시티 팀은 멀티노드 환경에서 모델을 운영하기 위해 레이 클러스터(Ray Cluster)를 구축했으며, 각 워커 노드에는 8개의 A100 GPU가 장착되었다. 이러한 구성을 통해 다양한 샤딩 전략을 실험할 수 있었고, 결과적으로 텐서 병렬 처리를 적용한 8웨이 텐서 병렬(8-way tensor parallel) 구성에서 최적의 성능을 확인했다.
입력 토큰 1024개 기준 지연시간 2.61초→2.07초, 실시간 AI 서비스 체감 속도 향상
퍼플렉시티의 멀티노드 배포 전략은 딥시크 모델의 성능을 크게 향상시켰다. 입력 토큰 수가 1024개일 때 평균 지연시간이 단일 노드 배포의 경우 2.61초에서 멀티노드 배포에서는 2.07초로 약 20% 감소했다. 또한 최대 처리량은 배치 크기 1024일 때 초당 약 135만 토큰으로, 단일 노드 배포에 비해 8배 향상되었다.
이러한 성능 개선은 대화형 AI 애플리케이션에서 특히 중요하다. 퍼플렉시티는 실험을 통해 멀티노드 배포가 단일 노드 배포보다 더 높은 처리량을 유지하면서도 지연시간을 줄일 수 있음을 입증했다. 이는 사용자 경험 향상과 서비스 효율성 개선에 직접적으로 기여한다.
FAQ
Q: 멀티노드 배포가 일반 사용자들에게 어떤 이점을 제공하나요?
A: 멀티노드 배포는 AI 응답 속도를 약 20% 빠르게 하고 동시에 처리할 수 있는 사용자 수를 8배까지 늘릴 수 있어, 사용자들은 더 빠른 응답과 안정적인 서비스를 경험할 수 있습니다.
Q: 텐서 병렬 처리와 파이프라인 병렬 처리의 차이점은 무엇인가요?
A: 텐서 병렬 처리는 모델의 각 층을 여러 GPU에 분산시켜 메모리 사용량을 줄이는 방식이고, 파이프라인 병렬 처리는 모델의 서로 다른 층들을 각각 다른 장치에 분산시켜 병렬로 처리하는 방식입니다.
Q: 퍼플렉시티가 사용한 딥시크 모델은 어떤 AI 모델인가요?
A: 딥시크(DeepSeek)는 대규모 언어 모델로, 텍스트 생성과 이해 능력을 갖춘 고급 AI 모델입니다. 퍼플렉시티는 이 모델을 멀티노드 환경에 배포하여 성능을 최적화했습니다.
해당 기사에서 인용한 보고서 원문은 링크에서 확인할 수 있다.
이미지 출처: 퍼플렉시티
기사는 클로드와 챗GPT를 활용해 작성되었습니다.



![[CES 2026] 가격표 붙은 ‘휴머노이드 로봇’ 시대… 집안을 보여줄 준비가 됐습니까?](https://aimatters.co.kr/wp-content/uploads/2026/01/AI-매터스-기사-썸네일-CES2026-robots.jpg)

