
DiagnosisArena: Benchmarking Diagnostic Reasoning for Large Language Models
1,113개 실제 의료 사례로 검증한 AI의 한계
최첨단 대규모 언어 모델(LLM)조차 복잡한 의료 진단 추론에서는 예상보다 훨씬 낮은 성능을 보인다는 연구 결과가 발표됐다. 상하이 자오통 대학교의 SPIRAL Lab과 Generative AI Research Lab(GAIR) 연구진이 개발한 DiagnosisArena 벤치마크에서 오픈AI(OpenAI)의 최신 모델 o3도 51.12%의 정확도에 그쳤다.
연구진이 발표한 논문에 따르면, DiagnosisArena는 기존의 의료용 AI 벤치마크와는 차별화된 접근을 취한다. 기존 벤치마크들이 주로 의료 면허 시험 문제나 객관식 형태로 구성된 반면, 이 벤치마크는 실제 임상 사례를 바탕으로 한 개방형 진단 문제로 구성됐다. 연구진은 란셋(Lancet), 뉴잉글랜드 의학 저널(NEJM), 미국의학협회지(JAMA) 등 10개 최상위 의학 저널에서 발표된 임상 사례 보고서 4,175건을 수집해 엄격한 검증 과정을 거쳐 1,113개의 고품질 진단 문제를 구축했다.
각 사례는 환자 정보, 신체 검사 결과, 진단 검사 결과 세 부분으로 구성되며, 28개 의료 전문 분야를 아우른다. 특히 기존 의료 지식만으로는 해결할 수 없는 복잡한 추론이 필요한 사례들로만 선별했다는 점이 특징이다. 연구진은 AI 전문가들과 자격을 갖춘 의사들이 참여한 다단계 검증 과정을 통해 벤치마크의 품질을 보장했다.
2015~2025년 데이터로 검증… “AI가 문제를 미리 본 건 아니다”
AI 모델의 성능 평가에서 항상 제기되는 의혹이 있다. 훈련 데이터에 시험 문제가 포함되어 모델이 미리 답을 알고 있었던 것은 아닐까 하는 의심이다. 연구진은 이러한 데이터 누출(Data Leakage) 가능성을 철저히 검증했다. 2022년부터 2024년까지 발표된 690개의 의학 저널 논문을 분석한 결과, 모든 모델에서 연도별 성능 차이가 거의 없었다. 특히 DiagnosisArena의 지난 10년간 데이터를 분석했을 때도 주요 모델들의 정확도가 시간에 따라 큰 변화를 보이지 않았다. 이는 모델들이 특정 사례를 미리 학습했을 가능성이 매우 낮다는 것을 의미한다.
일부 모델에서 2024년 데이터의 성능이 약간 낮아진 것이 관찰됐지만, 이는 오히려 해당 연도 이전 데이터가 훈련에 포함됐을 가능성을 시사할 뿐 전체적인 평가 결과에는 영향을 주지 않았다. 이러한 검증 과정을 통해 DiagnosisArena의 평가 결과가 공정하고 신뢰할 수 있음이 확인됐다.
o3 51%, o1 31%, 딥시크 R1 17%… 최신 AI도 의료 앞에서 무력
실험 결과는 현재 AI 기술의 의료 분야 적용에 대한 중요한 시사점을 제공한다. 가장 성능이 뷰어난 오픈AI의 o3 모델이 51.12%의 정확도를 기록했고, o1은 31.09%, 딥시크(DeepSeek)의 R1은 17.79%에 그쳤다. 클로드(Claude) 3.5 소넷과 Qwen2.5-Max 같은 강력한 모델들도 20% 미만의 성능을 보였다. 흥미롭게도 추론 능력을 강화한 모델들이 일반 모델보다 명확히 우수한 성능을 보였다. 상대적으로 작은 매개변수를 가진 QwQ-32B도 25.69%의 정확도를 달성했으며, 딥시크 R1은 기본 모델인 딥시크 V3 대비 13.66%의 성능 향상을 보였다. 이는 의료 진단에서 추론 능력의 중요성을 강조하는 결과다.
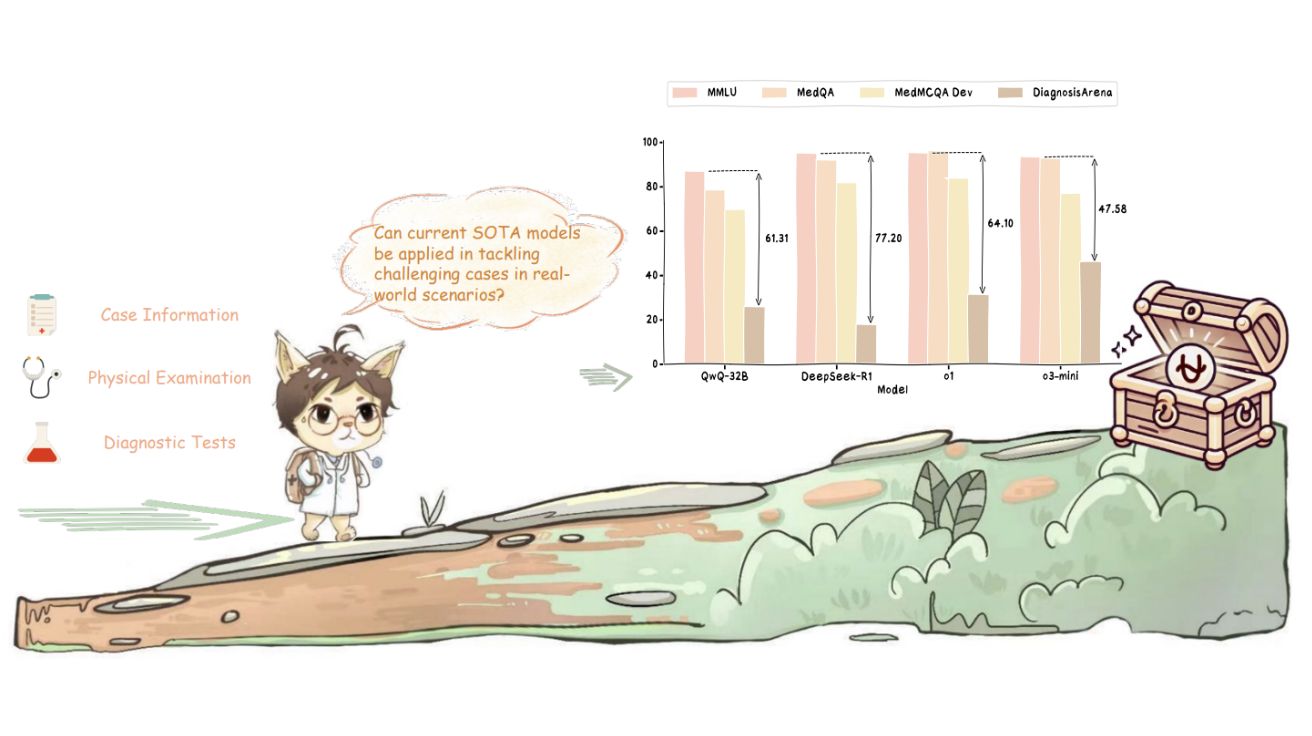
객관식 61% vs 주관식 31%… 진짜 실력은 절반도 안 돼
연구진이 같은 문제를 객관식으로 변환한 DiagnosisArena-MCQ 실험에서는 모든 모델의 성능이 크게 향상됐다. o1의 경우 61.90%까지 정확도가 올랐고, 개방형에서 10% 미만이던 Baichuan-M1도 58.31%를 기록했다. 이러한 성능 차이는 객관식 문제가 본질적으로 문제 공간을 제한해 실제 진단 추론 능력을 정확히 평가하지 못한다는 것을 보여준다.
연구진은 실제 임상 상황에서는 의사가 무한한 가능성 중에서 정확한 진단을 찾아내야 하지만, 객관식에서는 주어진 선택지 중에서 가장 그럴듯한 답을 고르는 것으로 충분하기 때문이라고 설명했다. 이는 현재 많은 의료 AI 벤치마크가 모델의 실제 능력을 과대평가할 수 있음을 시사한다.
AMVT 진단 실패 사례로 본 AI의 치명적 맹점
연구진이 제시한 실제 사례 분석에서는 AI 모델들의 한계가 더욱 명확히 드러났다. 보조 승모판 조직(AMVT) 진단 사례에서 o3-mini만이 정답을 제시했고, 나머지 모델들은 모두 틀렸다. 딥시크 R1의 추론 과정을 분석한 결과, 모델이 AMVT 가능성을 아예 고려하지 않고 일반적인 종양이나 혈전 등에만 집중했다는 것을 발견했다.
연구진은 이러한 현상이 현재 AI 모델들이 여전히 지식 재생산에 의존하며, 의료 진단에 필요한 미묘한 단서들을 종합적으로 분석하는 능력이 부족하기 때문이라고 분석했다. 의료 진단은 환자의 모든 증상과 검사 결과의 세부적인 차이점에 주의를 기울여 점진적으로 정보를 조합해 진실을 재구성하는 과정이 필요하다.
FAQ
Q: DiagnosisArena가 기존 의료 AI 벤치마크와 다른 점은 무엇인가요?
A: 기존 벤치마크가 의료 면허 시험 문제나 객관식 형태인 반면, DiagnosisArena는 최상위 의학 저널의 실제 임상 사례를 바탕으로 한 개방형 진단 문제입니다. 단순한 지식 암기가 아닌 복잡한 추론 능력을 평가할 수 있도록 설계됐습니다.
Q: 최고 성능 AI 모델도 51%에 그친 이유는 무엇인가요?
A: 의료 진단은 환자의 증상, 검사 결과, 의료 기록 등 다양한 정보를 종합적으로 분석해야 하는 복잡한 추론 과정입니다. 현재 AI 모델들은 일반적인 질병에 대한 지식 재생산에는 뛰어나지만, 실제 임상에서 요구되는 세밀한 단서 분석과 종합적 추론 능력은 여전히 부족합니다.
Q: 이 연구 결과가 의료 AI 발전에 어떤 의미를 갖나요?
A: 현재 AI 기술이 실제 의료 현장에 적용되기에는 아직 한계가 있음을 보여줍니다. 앞으로 AI의 의료 진단 능력을 향상시키기 위해서는 단순한 지식 학습을 넘어 복잡한 추론 능력을 개발하는 것이 필요하다는 방향성을 제시합니다.
해당 기사에 인용된 논문 원문은 링크에서 확인 가능하다.
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성했습니다.
![[Q&AI] 21대 대선 당선자 확정 시간 예측 어디가 정확할까? ‘그록 vs. 퍼플렉시티’](https://aimatters.co.kr/wp-content/uploads/2025/06/AI-Matters-기사-썸네일-QAI.jpg)

![[Q&AI] 이재명 정부 ‘AI 정책수석’ 후보 4명 누구?](https://aimatters.co.kr/wp-content/uploads/2025/06/AI-Matters-기사-썸네일-QAI-1.jpg)