
LLMs + Persona-Plug = Personalized LLMs
중국 인민대학교와 바이두(Baidu)가 공동 발표한 연구 논문에 따르면, 대형언어모델의 개인화를 획기적으로 개선하는 ‘페르소나 플러그(Persona-Plug)’ 기술이 개발됐다.
페르소나 플러그, ‘일률적 응답’의 한계를 넘어서다
대형언어모델(LLMs)은 자연어 이해와 생성, 추론 능력에서 놀라운 성과를 보이며 일상적인 작업 지원에 필수적인 도구가 되었다. 그러나 현재의 대형언어모델은 동일한 입력에 대해 모든 사용자에게 비슷한 응답을 제공하는 ‘one-size-fits-all’ 방식을 따르고 있다. 샘플링 기반 디코딩 전략으로 어느 정도 다양성을 확보할 수 있지만, 이는 개인별 선호도를 반영하지 못해 인간-기계 상호작용의 효과를 떨어뜨린다. 특히 사용자의 주관적 프로필에 맞춘 응답이 필요한 개인 맞춤형 연설문 작성과 같은 상황에서 이러한 한계가 두드러진다.
기존 개인화 접근법의 문제점
지금까지 시도된 대형언어모델의 개인화 방식은 크게 두 가지였다. 첫째는 각 사용자별로 특화된 모델을 파인튜닝하는 것이다. 이는 효과적이지만 학습과 추론에 막대한 컴퓨팅 자원이 필요해 실제 적용이 어렵다. 둘째는 사용자의 과거 이력을 검색해 참고자료로 활용하는 방식이다. 일부 연구에서는 현재 입력과 관련된 이력만을 선별적으로 활용했으나, 이는 사용자의 전반적인 스타일과 패턴을 파악하는 데 한계가 있었다. BGE-base(BAAI/bge-base-en-v1.5) 모델을 기반으로 한 인코더는 전체 파라미터의 약 3.1%(220M)만을 차지해 효율적인 구현이 가능했다.
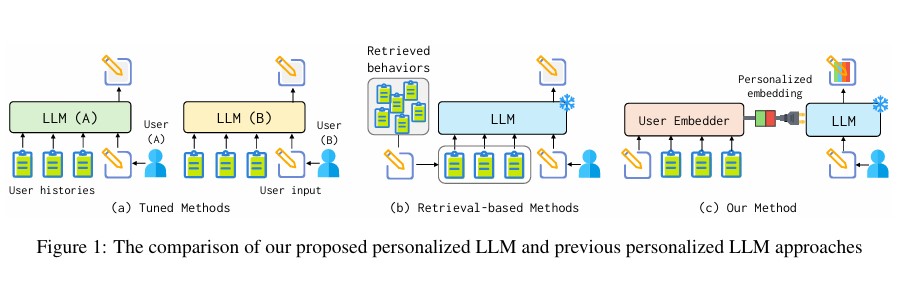
효율적인 개인화를 실현하는 페르소나 플러그의 작동 원리
페르소나 플러그는 사용자 행동 인코더, 입력 인식 개인화 집계기, LLM 입력 임베딩이라는 핵심 구성요소를 통해 작동한다. BGE-base-en-v1.5 모델을 기반으로 각 사용자의 과거 행동을 벡터로 변환하고, 현재 입력과의 관련성을 고려해 과거 행동 벡터들을 종합한다. 이렇게 생성된 개인화 임베딩을 입력값에 추가하는 방식으로, 전체 파라미터의 약 3.1%(220M)만을 차지해 효율적이며 검색 기반 방식과도 통합이 가능하다.
구현 측면에서는 FlanT5-XXL (11B)을 기본 LLM으로 사용하며, 최대 입력 길이는 LLM의 경우 256 토큰, 인코더는 512 토큰으로 설정했다. 또한 생성 품질 향상을 위해 빔 서치 크기를 4로 설정해 다양한 출력 후보를 고려했다. 모델 학습은 LaMP-3을 제외한 모든 과제에서 2에포크로 진행되었으며, 더 큰 데이터셋을 가진 LaMP-3의 경우 1에포크로 충분한 성능을 보였다.
벤치마크 테스트로 입증된 우수한 성능
LaMP 벤치마크는 다양한 개인화 과제를 포함하고 있다. 인용문 식별(LaMP-1)은 6,542개의 훈련 데이터와 1,500개의 검증 데이터를 사용했으며, 평균 입력 길이는 51.43 토큰이었다. 영화 태깅(LaMP-2)은 5,073개의 훈련 데이터로 92.39 토큰의 평균 입력 길이를 보였다. 가장 큰 데이터셋인 제품 평가(LaMP-3)는 20,000개의 훈련 데이터를 포함했다.
성능 평가에서 페르소나 플러그는 기존의 모든 접근 방식을 능가했다. 기본 FlanT5-XXL 모델(Ad-hoc)과 비교했을 때 모든 과제에서 큰 폭의 성능 향상을 보였으며, BM25나 Contriever와 같은 기존의 검색 기반 방식(Naive RBP)보다도 우수한 성능을 달성했다. 특히 최적화된 검색 기반 방식(Optimized RBP)과 비교해서도 더 나은 결과를 보여주었다.
모델 구성에 따른 성능 차이도 주목할 만하다. FlanT5-XXL과 BGE-base 조합이 가장 좋은 성능을 보였으며, Llama 2 7B와 Contriever를 사용한 경우에도 준수한 성능을 달성했다. 이는 페르소나 플러그가 다양한 모델 구성에서도 안정적으로 작동함을 보여준다.
실용성과 확장성을 갖춘 차세대 기술
페르소나 플러그의 실용적 가치는 크게 세 가지 측면에서 평가할 수 있다. 첫째, 기존 방식들과 달리 단일 모델로 모든 사용자의 개인화를 지원할 수 있어 서비스 운영이 효율적이다. 둘째, 사용자별로 별도의 모델을 파인튜닝할 필요가 없어 컴퓨팅 자원을 절약할 수 있다. 셋째, 프라이버시 보호 측면에서 우수한 특성을 보인다.
다만 현재 버전의 페르소나 플러그는 몇 가지 기술적 한계도 가지고 있다. 행동 수준의 분석에 그치고 있어 용어나 구문 수준의 상세한 사용자 특성을 포착하지 못하는 점, 검색 기반 방식과의 통합이 아직 최적화되지 않은 점 등이 향후 개선이 필요한 부분으로 지적되었다.
프라이버시 보호와 함께하는 AI의 미래
연구진은 페르소나 플러그가 검색 기반 방식과의 통합을 통해 더 나은 성능을 낼 수 있을 것으로 전망했다. 특히 프라이버시 측면에서도 장점이 있는데, 서비스 제공자는 튜닝된 사용자 임베더 모델만 제공하고 사용자는 자체적으로 개인 임베딩을 생성해 활용할 수 있어 민감한 개인 데이터의 노출을 최소화할 수 있다.
해당 논문의 원문은 링크에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기




![[Q&AI] 15억 로또 ‘올림픽파크포레온’ 청약 시작… 고려 사항은?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-4.jpg)