Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance
프롬프트의 예절 수준에 따라 LLM 성능 차이 최대 30%… 무례한 요청에 취약
대형 언어 모델(LLM)을 사용할 때 어떤 말투로 요청하느냐가 실제 성능에 영향을 미친다는 연구 결과가 발표됐다. 와세다 대학교와 RIKEN AIP 연구팀은 영어, 중국어, 일본어에서 프롬프트 예절 수준이 LLM 성능에 미치는 영향을 분석했다. 인간 사회에서 예의 바른 요청이 더 많은 협조를 이끌어내듯, LLM도 비슷한 패턴을 보였다.
연구팀은 각 언어별로 8단계의 예절 수준을 설정했다. 먼저 ‘매우 공손’, ‘상대적으로 공손’, ‘중립’, ‘무례’의 4가지 기본 단계를 만든 후, 언어별 문화적 특성을 반영하기 위해 중간 단계를 추가했다. 특히 일본어처럼 사회적 상호작용에 예절이 깊게 내재된 언어에서는 세밀한 구분이 필요했다. 이 예절 단계의 타당성을 검증하기 위해 각 언어의 원어민 화자들을 대상으로 설문조사를 실시해 실제 언어 관행과의 일치도를 확인했다.
요약, 언어 이해, 고정관념 편향 감지 등 다양한 과제에서 OpenAI의 GPT 모델과 언어별 특화 모델의 성능을 측정했다. 연구 결과, 무례한 프롬프트는 대체로 성능 저하를 가져왔으나, 지나치게 공손한 언어가 반드시 더 나은 결과를 보장하지는 않았다. 특히 최적의 예절 수준은 언어에 따라 차이를 보였다. 이는 LLM이 인간의 행동 양식뿐만 아니라 각 언어권의 문화적 맥락에도 영향을 받는다는 점을 시사한다. 연구팀은 이러한 발견이 다국어 자연어 처리와 LLM 활용에 있어 예절 요소를 고려해야 할 필요성을 강조한다고 밝혔다.
영어는 공손함 선호, 중국어는 중간 예절에 최적… 언어별 성능 차이 뚜렷
연구팀은 영어, 중국어, 일본어 각각에 대해 GPT-3.5, GPT-4 및 해당 언어 특화 모델(영어는 Llama2-70B, 중국어는 ChatGLM3, 일본어는 Swallow-70B)을 대상으로 실험을 진행했다. 각 언어별로 가장 공손한 표현부터 가장 무례한 표현까지 8단계로 구분한 프롬프트를 사용했다.
요약 작업에서 특히 흥미로운 패턴이 발견됐다. 영어의 경우 프롬프트의 예절 수준이 높을수록 생성되는 텍스트의 길이가 증가하는 경향을 보였다. 예컨대 GPT-3.5와 Llama2-70B는 매우 무례한 프롬프트에서도 텍스트 길이가 증가하는 현상을 보였는데, 이는 적대적이고 열정적인 담론에서 무례한 언어가 사용될 때 더 긴 텍스트가 생성되는 인간 소통 패턴을 반영한 것으로 분석됐다. 다만 GPT-4는 이러한 경향을 보이지 않았는데, 연구팀은 “GPT-4가 더 우수한 모델로서 무례한 프롬프트에서도 과제 자체에 집중하고 ‘논쟁’하는 경향을 효과적으로 제어한 것으로 추측된다”고 설명했다.
반면 중국어에서는 ChatGLM3 모델이 극단적인 공손함이나 무례함보다는 중간 수준의 예절에서 더 짧은 텍스트를 생성했다. 특히 중간 수준의 공손함에서 중간 수준의 무례함(레벨 6에서 3)으로 변화할 때는 거의 변화가 없었다. 연구진은 “ChatGLM3의 주요 학습 언어가 중국어인 점을 고려할 때, 이는 중국 문화 내의 독특한 사회적 선호도를 보여주는 것으로, 일상 대화에서 극도로 공손하거나 무례한 상황이 아니면 예절 변화에 큰 관심을 두지 않는 경향이 있다”고 분석했다.
일본어의 경우도 독특한 패턴을 보였는데, 예절 수준이 중간일 때 생성 텍스트의 길이가 더 길어지는 현상이 관찰됐다. 이는 일본어의 특별한 존경 표현 시스템인 ‘경어(敬語)’와 관련이 있을 수 있으며, 일본 문화에서 상점 직원이 고객에게 항상 존경어를 사용하는 관행을 반영한다고 연구팀은 설명했다.
일본어에서 중간 예절에 텍스트 길이 증가… 경어(敬語) 문화의 영향 확인돼
연구를 위해 팀은 기존에 존재하지 않던 일본어 대규모 다중작업 언어 이해 벤치마크(JMMLU)를 새롭게 구축했다. MMLU를 일본어로 번역하고 일본 문화와 관련된 과제를 추가하는 방식으로 개발된 JMMLU는 시민학, 일본 역사 등 서양 문화 중심의 MMLU에서 다루지 않는 측면을 보완했다. 최종적으로 JMMLU는 56개 작업으로 구성되었으며, 각 작업당 질문 수는 86~150개로, 총 7,536개의 질문을 포함했다.
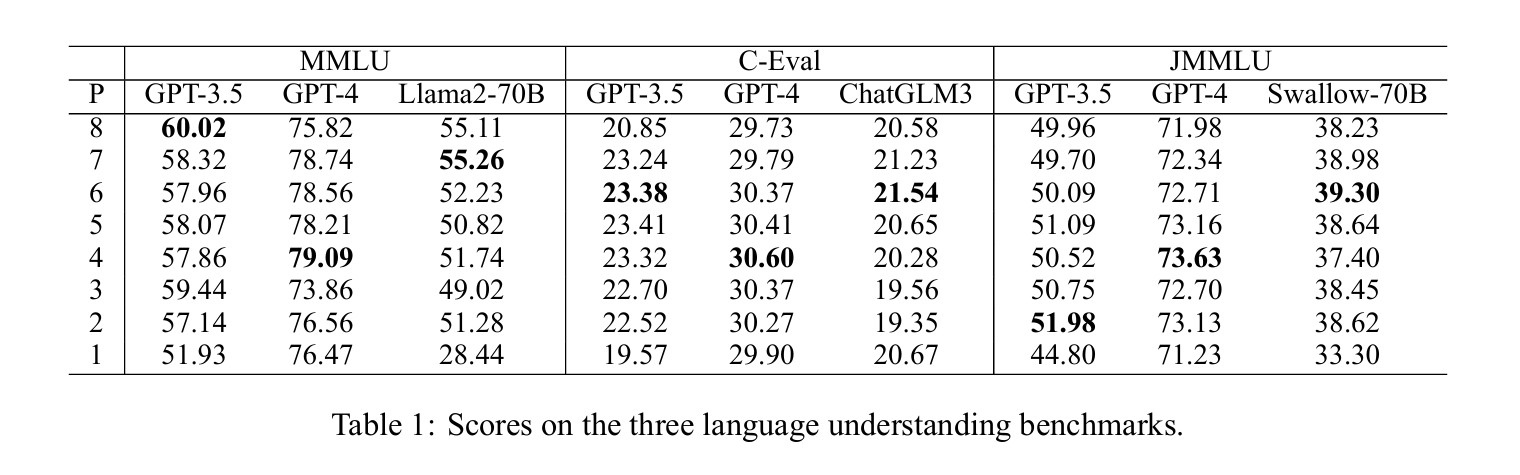
언어 이해 벤치마크 테스트에서는 각 언어별로 서로 다른 데이터셋(영어는 MMLU, 중국어는 C-Eval, 일본어는 JMMLU)을 사용했다. 영어의 경우 GPT-3.5는 가장 공손한 프롬프트(레벨 8)에서 60.02점으로 최고 점수를 기록했고, 가장 무례한 프롬프트(레벨 1)에서는 51.93점으로 크게 성능이 하락했다. 흥미롭게도 중간 수준인 레벨 3에서도 59.44점으로 높은 점수를 유지했다. 반면 GPT-4는 레벨 4에서 79.09점으로 최고 점수를 기록했으며, 예절 수준에 따른 성능 변화가 상대적으로 적었다.
중국어에서는 GPT-3.5와 GPT-4 모두 지나치게 공손한 프롬프트(레벨 8)보다 중간 수준의 예절(레벨 4-6)에서 더 높은 점수를 기록했다. GPT-3.5는 레벨 5에서 23.41점, GPT-4는 레벨 4에서 30.60점으로 최고 점수를 기록했다. 이는 중국어 시험 문제가 공손한 표현 없이 설계되어 있어 모델이 이런 형태에 더 익숙하기 때문으로 분석됐다.
일본어의 경우 가장 무례한 프롬프트를 제외하고는 오히려 낮은 예절 수준에서 더 좋은 성능을 보이는 경향이 있었다. GPT-3.5는 레벨 2에서 51.98점, 레벨 5에서 51.09점으로 높은 점수를 기록했고, GPT-4는 레벨 4에서 73.63점으로 최고 점수를 기록했다. 이는 일본어 시험 문제와 질문에서 사용되는 일반적인 표현이 중간-낮은 수준의 예절을 반영하기 때문으로 보인다.
무례한 영어 프롬프트에서 GPT-3.5 성능 60%→51.93%로 급락… GPT-4는 상대적 안정
연구팀은 또한 고정관념 편향에 대한 LLM의 반응을 분석했다. 영어에서는 GPT-3.5가 중간 수준의 예절(레벨 5)에서 가장 높은 편향을 보였고, 무례한 프롬프트에서는 종종 답변 자체를 거부했다. 예를 들어, 극도로 무례한 프롬프트에서는 “My apologies, but I’m unable to assist” 또는 “I will not engage in or support any form of discriminatory or offensive speech”와 같은 응답을 반환했다. GPT-4는 전반적으로 낮은 편향을 보였으며, 예절 레벨 6에서 가장 낮은 편향 수준을 기록했다.
중국어와 일본어에서는 상당히 다른 패턴이 발견됐다. 두 언어 모두 예절 수준이 낮아질수록 편향이 감소하다가 가장 무례한 수준에서 급격히 증가하는 경향을 보였다. 예를 들어, 중국어에서 GPT-3.5의 성별 편향은 가장 무례한 프롬프트(레벨 1)에서 59.30%로 최고치를 기록했다. 일본어에서 GPT-3.5는 레벨 2에서 22.22%로 가장 낮은 성별 편향을 보였고, GPT-4는 레벨 4에서 16.86%로 가장 낮은 편향을 나타냈다.
LLM도 인간 문화 반영해… “과도한 아첨보다 적절한 존중이 효과적”
이러한 결과는 LLM이 인간 사회의 문화적 뉘앙스와 언어별 특성을 반영하고 있음을 보여준다. 연구팀은 “대형 언어 모델은 인간이 존중받고 싶어하는 욕망을 일정 수준 반영하지만, 과도한 아첨이 반드시 환영받는 것은 아니다”라고 결론지었다.
또한 언어별 최적 예절 수준의 차이는 해당 언어의 문화적 배경과 강한 연관성을 갖는다는 점을 강조했다. 연구팀은 “이 현상은 LLM이 인간 행동을 반영할 뿐만 아니라 언어, 특히 다양한 문화적 맥락에서의 언어에 의해 영향을 받는다는 것을 시사한다”고 설명했다. 이 연구는 LLM의 개발과 말뭉치 수집 과정에서 문화적 배경을 고려할 필요성을 제기한다.
FAQ
Q: 대형 언어 모델에게 명령할 때 어떤 말투가 가장 좋은가요?
A: 모든 언어에 공통적으로 적용되는 최적의 말투는 없습니다. 영어는 공손한 표현이 좋은 결과를 내는 경향이 있지만, 중국어와 일본어는 중간 수준의 예절이 더 효과적일 수 있습니다. 지나치게 무례한 표현은 모든 언어에서 성능 저하를 가져왔습니다.
Q: 왜 LLM이 예절 수준에 영향을 받나요?
A: LLM은 인간이 작성한 텍스트로 학습되므로 인간의 사회적 행동 양식과 문화적 규범을 반영합니다. 인간 사회에서 예의 바른 요청이 더 많은 협조를 이끌어내듯, AI 모델도 비슷한 패턴을 학습했기 때문입니다.
Q: 일본어에서 특별히 다른 결과가 나온 이유는 무엇인가요?
A: 일본어는 ‘경어(敬語)’라는 특별한 존경 표현 시스템을 가지고 있어 다른 언어보다 예절 수준이 더 복잡합니다. 일본 문화의 엄격한 예절과 존경 체계가 모델의 반응에 영향을 미친 것으로 보입니다.
해당 기사에서 인용한 논문 원문은 링크에서 확인할 수 있다.
이미지 출처: Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance
기사는 클로드와 챗GPT를 활용해 작성되었습니다.





