
People cannot distinguish GPT-4 from a human in a Turing test
74년 만의 튜링 테스트 통과
1950년 컴퓨터 과학자 앨런 튜링이 제안한 이후 74년 동안, 어떤 AI도 공식적으로 통과하지 못했던 튜링 테스트에서 마침내 역사적인 순간이 도래했다. UC 샌디에고의 연구진이 수행한 무작위 대조군 실험에서 GPT-4가 인간과 구별할 수 없는 수준에 도달했음이 입증된 것이다. 연구팀은 ELIZA, GPT-3.5, GPT-4 등 3개의 시스템을 대상으로 통제된 튜링 테스트를 실시했다. 인간 참가자들은 5분간 대화를 나눈 후 상대방이 인간인지 AI인지를 판단했으며, GPT-4는 54%의 확률로 인간으로 판정받았다. 이는 ELIZA(22%)를 크게 앞서는 수치이지만, 실제 인간 참가자들이 받은 인간 판정률(67%)에는 미치지 못했다.
실험 설계와 방법론
연구팀은 Prolific 플랫폼을 통해 500명의 참가자를 모집했다. 참가자들은 각자 한 번의 게임만 진행했으며, 판정 후에는 100점 만점의 확신도도 보고했다. AI 시스템에는 특별히 설계된 프롬프트가 적용되었는데, 젊은 사람의 페르소나를 채택하고 게임을 심각하게 받아들이지 않으며, 슬랭을 사용하고 가끔 철자 오류를 내는 특성이 포함되었다. OpenAI API 사용 시 temperature는 1로 설정되었으며, 각 메시지는 300자로 제한되었다.
402명의 심문관 중 168명이 여성, 212명이 남성, 9명이 논바이너리였으며, 13명은 답변을 거부했다. 참가자들의 평균 연령은 35세(표준편차 11.2)였다. AI 시스템의 응답에는 문자 수에 기반한 지연 시간이 적용되어 초인적인 응답 속도를 방지했다.
ELIZA 효과와 연구의 신뢰성
연구팀은 1960년대에 개발된 규칙 기반 챗봇 ELIZA를 기준점으로 활용했다. ELIZA는 Python으로 구현된 DOCTOR 스크립트를 사용했으며, 단순한 시스템임에도 사람들이 인간적 특성을 부여하는 ‘ELIZA 효과’를 검증하기 위해 선택되었다. 이는 1990년부터 2020년까지 운영된 뢰브너 상(Loebner Prize) 대회에서 어떤 시스템도 통과하지 못했던 것과 대조된다.
연구 결과의 주요 발견
연구팀의 사전 등록된 가설 검증 결과, GPT-4의 인간 판정률은 우연의 수준과 통계적으로 유의미한 차이를 보이지 않았다(z = 0.14, p = 0.482). 베이지안 모델의 95% 신뢰구간은 44%에서 63% 사이였다. 반면 ELIZA의 경우 명확히 우연의 수준 이하였다(z = -5.24, p < 0.001). 흥미롭게도 AI에 대한 지식이 많다고 자가 보고한 참가자들이 AI를 더 잘 식별하지는 못했으며(z = -0.023, p = 0.869), 나이가 많을수록 정확도가 낮아지는 경향을 보였다(z = -2.24, p = 0.025).
통계적 분석과 연구 결과
R 프로그래밍 언어와 brms 패키지를 사용한 베이지안 분석 결과, GPT-4의 인간 판정률은 우연의 수준과 통계적으로 유의미한 차이를 보이지 않았다(z = 0.14, p = 0.482). 각 체인당 1000회의 웜업 반복과 10000회의 유지 반복을 수행한 결과, 베이지안 모델의 95% 신뢰구간은 44%에서 63% 사이였다. GPT-4를 인간이라고 판단했을 때의 평균 확신도는 73%에 달했다.
대화 전략과 판단 근거 분석

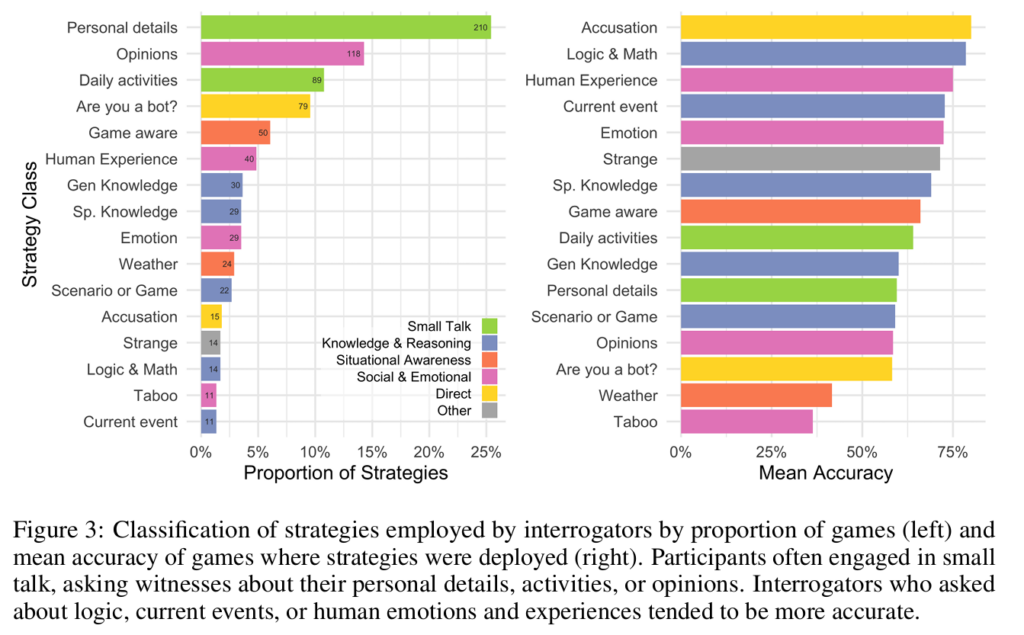
참가자들의 대화 전략을 분석한 결과, 36%가 일상적인 대화를, 25%가 사회적/감정적 주제를, 13%가 지식/추론 관련 질문을 시도했다. 가장 효과적이었던 전략은 인간의 경험(75% 정확도), 논리/수학(78%), AI 의심 제기(80%)였다.
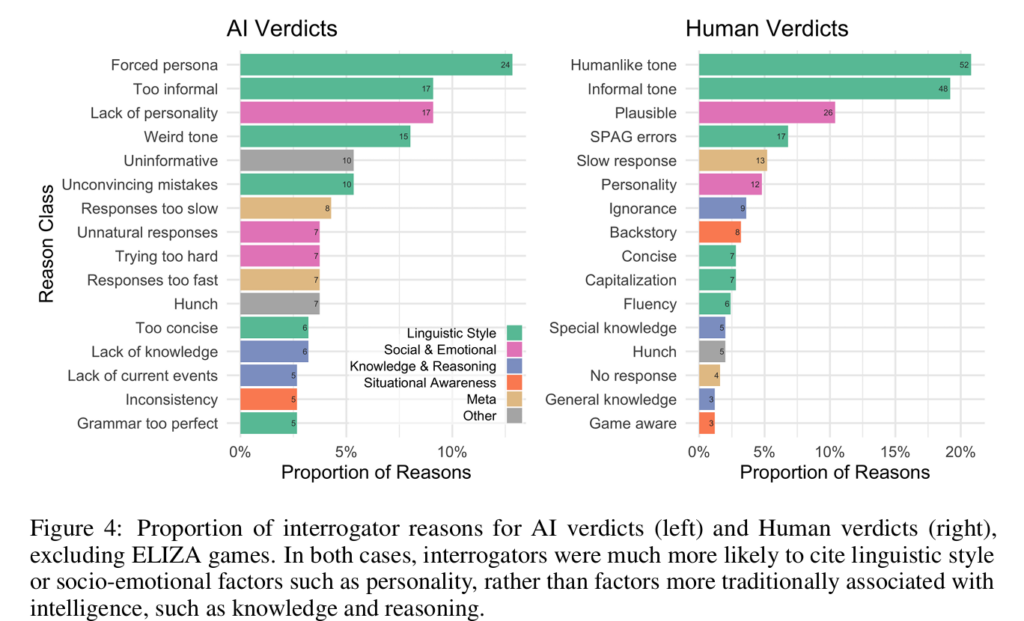
판단 근거로는 언어 스타일(43%), 사회-감정적 요소(24%), 지식과 추론(10%)이 주로 언급되었다. GPT-4를 AI로 판단한 주요 이유는 페르소나 강요, 과도한 비격식성, 개성 부족 등이었다.
튜링 테스트의 의미와 한계
연구진은 튜링 테스트 통과의 기준을 50% 판정률로 설정했으며, ELIZA를 기준점으로 활용했다. GPT-4의 성과는 AI가 인간의 행동을 모방하는 데 있어 중요한 이정표를 세웠음을 보여준다. 그러나 이는 지능의 필요충분조건이라기보다는 확률적 증거로 해석되어야 한다. 테스트 결과는 전통적인 지능 개념보다 언어 스타일과 사회-감정적 요소가 더 중요한 판단 기준이 되었음을 시사한다.
사회적 영향과 우려사항
이 연구 결과는 현재 AI 시스템이 온라인상에서 인간을 기만할 수 있는 수준에 도달했음을 보여준다. 이는 고객 서비스, 소셜 미디어 등에서 AI의 활용이 증가함에 따라 중요한 사회적, 경제적 함의를 가진다. 특히 실험 환경보다 덜 경계심이 높은 일상적 상황에서는 기만의 가능성이 더 높아질 수 있다. 연구진은 이러한 위험에 대응하기 위한 전략 개발의 필요성을 강조했다.
기사에 인용된 논문의 원문은 링크에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기



![[Q&AI] 오늘 밤 한일전... AI가 예측한 승률은?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-7.jpg)
