멀티모달AI

구글, 젬마 3와 제미나이 2.5로 게임개발 AI 혁신…
생성형 AI가 게임 산업의 판도를 바꾸고 있다. AI를 통해 게임 개발자들은 이전에는 상상할 수 없었던 역동적으로 진화하는 게임과…

구글, 코드 작성 특화 AI 모델 ‘제미나이 2.5…
구글이 6일(현지 시간) 제미나이 2.5 Pro 프리뷰(I/O 에디션)를 조기 출시했다. 이번 버전은 특히 코딩과 대화형 웹 앱 개발…

구글, 제미나이에 AI 이미지 편집 기능 추가… 이제…
지난달 30일(한국 시간) 구글코리아 블로그에 발표된 내용에 따르면, 구글(Google)이 제미나이(Gemini) 앱에 이미지 업로드와 AI 편집 기능을 새롭게 추가했다.…

함샤우트 글로벌, PR & 마케팅 전문가 위한 ‘생성형…
AI 마케팅 혁신으로 디지털 딥택트를 선도하는 종합 커뮤니케이션 기업 ㈜ 함샤우트 글로벌이 생성형 AI 시장의 급격한 변화 흐름을…

바이두 창업자 “텍스트 기반 AI 시장 축소 중”……
파이낸셜타임스(FT)의 보도에 따르면, 중국 검색 기업 바이두(Baidu)의 창업자가 자국 생성형 AI 기업 딥시크(DeepSeek)가 개발하는 텍스트 기반 모델에 대한…

오픈AI, AI 추론 모델 ‘o3’·’o4-mini’ 발표… 이미지 기반…
오픈AI(OpenAI)가 16일(현지 시간) 기존보다 더 똑똑하고 강력한 성능을 갖춘 최신 AI 모델인 ‘o3’와 ‘o4-mini’를 출시했다. 이번에 공개된 모델들은…

구글, AI 모델 ‘제미나이’와 ‘비오’ 통합 계획… 물리…
딥마인드의 데미스 하사비스 CEO는 10일(현지 시간) 팟캐스트 ‘Possible’에 출연해 구글이 자사의 다중 모달 인공지능(AI) 모델 제미나이(Gemini)에 영상 생성…
![[Next 2025] 구글, 109조 규모 인프라 투자 발표… “TPU '아이언우드'는 올해 말 출시”](https://aimatters.co.kr/wp-content/uploads/2025/04/AI-Matters-기사-썸네일-Next-2025.jpg)
[Cloud Next 25] 구글, 109조 규모 인프라 투자…
구글이 9일(현지 시간) 라스베이거스에서 열린 ‘클라우드 넥스트 25’ 행사에서 약 750억 달러(한화 약 109조원) 규모의 인프라 투자 계획과…
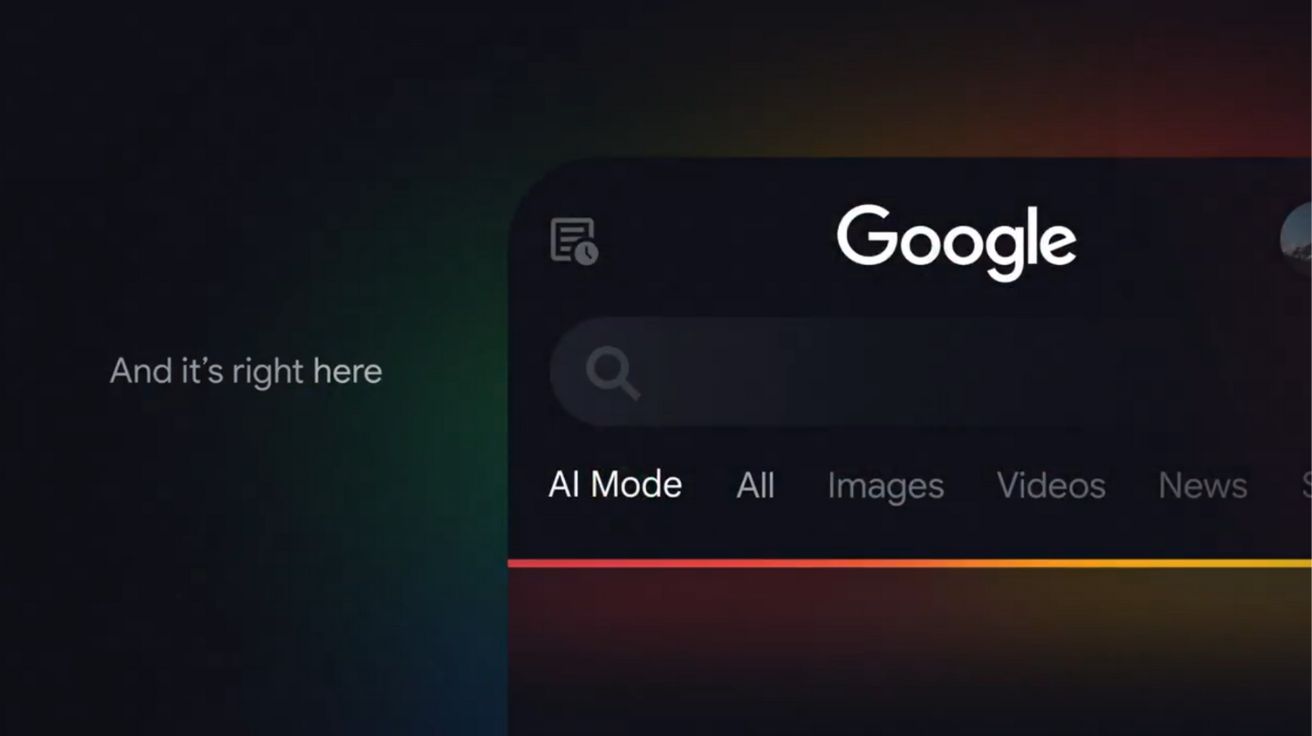
구글, AI 모드에 구글 렌즈 통합… 이미지 검색…
구글(Google)이 8일(현지 시간) 자사 X를 통해, 자사의 검색 서비스 내 AI 모드에 구글 렌즈(Google Lens)를 통합하여 사용자들이 이미지에…

메타, ‘라마 4’ 시리즈 공개… GPT-4.5와 클로드 3.7…
메타(Meta)가 새로운 라마 4(Llama 4) 시리즈를 발표했다. 5일(현지 시간) 메타 공식 블로그에 올라온 내용에 따르면, 이번에 공개된 ‘라마…


