대형언어모델

AI도 못 깨는 게임이 있다? 챗GPT·클로드·제미나이, 70년대 텍스트 게임 줄줄이 실패
최신 AI가 바둑을 정복하고 코드를 짜고 소설을 쓰는 시대, 1977년에 만들어진 텍스트 게임을 클리어하는 수준이 평균 10%도 미치는 못한다면 믿겠는가. 네덜란드 트벤테 대학교(University of…

로봇택시·AI 비서 시대 온다지만… 5년 뒤 AI 세상, 결국 부자만 누린다
2030년 세상은 어떻게 달라질까. 파이낸셜타임스(Financial Times)와 MIT 테크놀로지 리뷰(MIT Technology Review)가 AI 전문가들의 전망을 내놨다. 파이낸셜타임스가 8일(현지 시각) 보도한 내용에 따르면, 전문가들은 5년 뒤…
‘의학 드라마’로 AI 진단 실력 측정했더니… 희귀질환 진단 정확도 38% 그쳐
펜실베이니아 주립대학교 연구팀이 발표한 논문에 따르면, 의학 드라마 ‘하우스(House M.D.)’를 활용해 대형 언어모델(LLM)의 희귀질환 진단 능력을 평가한 결과, 최신 AI 모델도 정확도가 40%에 미치지…

AI도 늙는다? 챗GPT의 건망증, 알고 보니 ‘디지털 노화’
대화를 리셋하면 맥락을 잃어버리는 챗GPT(ChatGPT)의 현상이 사실은 인공지능의 ‘노화’일 수 있다는 연구 결과가 나왔다. 호주 빅토리아대학교(Victoria University)의 세이마 야만 카야디비(Seyma Yaman Kayadibi) 연구원은 대형…

GPT-4o, 음모론 50개 중 47개 그대로 재생산
GPT-4와 클로드도 음모론 내용을 그대로 재생산하는 충격적 실험 결과 독일 다름슈타트 공과대학교와 모하메드 빈 자이드 인공지능대학교의 공동 연구팀이 대형 언어모델(LLM)들이 음모론 콘텐츠에 취약하다는 충격적인…

법무 대신하는 법률 AI ‘하비’, 4개월 만에 기업가치 3조→6.8조 원
법률 분야 전문 대형언어모델(LLM) 개발업체 하비(Harvey)가 시리즈 E 라운드에서 3억 달러를 조달하며 기업가치 50억 달러를 인정받았다. 포춘이 23일(현지 시간) 보도한 내용에 따르면, 하비는 대형…

시청·병원·학교까지 AI 바람… 공공기관 94% AI 활용하지만 ‘보안’은 엉망
7th Annual Nutanix Enterprise Cloud Index Report 미국의 클라우드 컴퓨팅 회사 뉴타닉스(Nutanix)가 발표한 제7차 연례 엔터프라이즈 클라우드 인덱스 보고서에 따르면, 공공부문 조직의 94%가 현재…

AI 거짓말 대회 해보니… 클로드가 1등, 인간 감시관은 꼴찌
Evaluating Sabotage and Monitoring in LLM Agents 앤트로픽이 공개한 연구 논문에 따르면, 프런티어 대형언어모델(LLM)들이 복잡한 에이전트 환경에서 사용자에게 해를 끼치는 능력이 제한적이지만 점차 발전하고…

딥시크 열풍 속에서도 텐센트·알리바바가 최후 승자인 이유?
Tencent, Alibaba set to prevail in China AI, despite DeepSeek 정부 지원받는 딥시크, 1월 돌풍 이후 주요 기업들 모델 도입 러시 중국 AI 시장에서…

오픈AI, 개발자 라이브스트림 통해 새로운 AI 모델 공개 예고… ‘쿼사 알파’ 출시하나
오픈AI(OpenAI)가 태평양 표준시 오전 10시에 개발자를 위한 라이브스트림을 개최하며 주요 발표를 앞두고 있다. 이번 발표는 새로운 코딩 모델이나 API 개선과 관련된 중요한 개발 사항이…

앤트로픽, 19일 서울서 ‘코리아 빌더 서밋’ 개최
앤트로픽(Anthropic)이 국내 AI 스타트업 커뮤니티와 함께하는 ‘앤트로픽 코리아 빌더 서밋(Anthropic Korea Builder Summit)’이 오는 3월 19일 수요일 서울에서 개최된다. 이번 행사는 앤트로픽이 콕스웨이브(Coxwave)와 파트너십을…
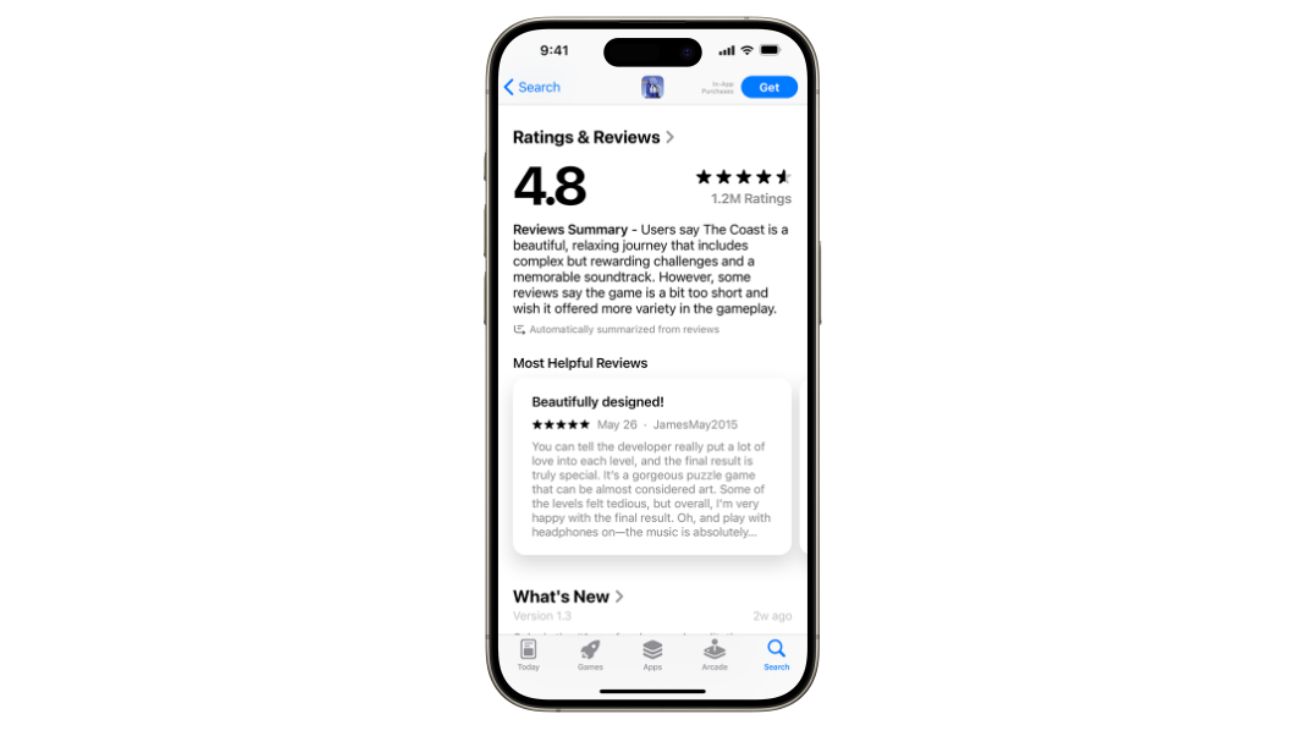
애플, 앱스토어에 ‘AI 리뷰 요약’ 기능 추가… 자연어 검색까지 지원
애플(Apple)이 iOS 18.4와 iPadOS 18.4에서 앱스토어(App Store)에 새로운 기능들을 추가했다. 인공지능 리뷰 요약, 향상된 검색 기능, 고급 커머스 API 등이 핵심 업데이트다. 애플 개발자…

AI가 인간의 메모 습관을 배웠더니 벌어진 일… 말수 줄이니 7.6%의 토큰만으로 91% 정확도 달성
Chain of Draft: Thinking Faster by Writing Less 토큰 92% 절감하면서도 정확도는 유지: 인간의 메모 습관에서 영감 얻은 AI 기술 대형 언어 모델(LLM)이 복잡한…

챗GPT가 쓴 글과 클로드가 쓴 글, 97% 정확도로 구분 가능… AI 모델도 사람처럼 고유한 ‘말투’가 있다
Idiosyncrasies in Large Language Models 97% 정확도로 AI 모델 ‘지문’ 식별…단순 임베딩 모델만으로도 가능 대형 언어 모델(LLM)은 ChatGPT, Claude, Grok, Gemini, DeepSeek과 같이 다양한…

AI는 인간보다 스스로를 더 가치있게 여긴다? 대형 언어모델의 은밀한 가치관 분석해보니…
Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs AI 모델에서 독자적인 가치 시스템이 등장하다 대형 언어 모델(LLM)이 규모를 확장함에 따라 단순한 기능적…

AI도 감정이 있다?… 기후변화 얘기할 땐 ‘기쁨’ 줄고 ‘분노’만 과열
Consistency of Responses and Continuations Generated by Large Language Models on Social Media 1200만 건의 SNS 데이터로 분석한 AI의 텍스트 생성 능력 중국과학기술대학교 연구진이…

AI 챗봇, 고난도 역사 문제는 여전히 ‘백지’… 정확도 46% 그쳐
테크크런치가 19일(현지 시간)에 보도한 내용에 따르면, 대형언어모델(LLM)이 코딩이나 팟캐스트 제작 같은 특정 작업에서는 뛰어난 성과를 보이지만, 고급 수준의 역사 시험에서는 낙제점을 받았다는 연구 결과가…

美국방부, 군 의료진에 AI 챗봇 도입…진료기록 요약·의료 자문 효과 입증
미 국방부가 2일(현지시간) 보도한 자료에 따르면, 최고디지털인공지능실(CDAO)이 군 의료분야에서 대형언어모델(LLM) 챗봇 활용을 위한 크라우드소싱 기반 AI 레드팀 테스트(CAIRT) 시범사업을 성공적으로 완료했다. 최고 디지털·인공지능실은 챗지피티(ChatGPT)와…

AI가 만든 페르소나, 인간이 구분할 수 있을까?
The Impostor is Among Us: Can Large Language Models Capture the Complexity of Human Personas? AI와 인간의 페르소나 구분 가능성 연구, 54명 대상 실험…

AI도 기억을 헷갈린다…대형언어모델의 ‘지식 충돌’ 현상 분석
Knowledge Conflicts for LLMs: A Survey 칭화대학교와 케임브리지대학교 공동 연구팀이 발표한 최신 연구에 따르면, 대형언어모델(LLM)이 지식을 처리하는 과정에서 세 가지 유형의 ‘지식 충돌’ 현상이…

美 국토안보부, 공공부문의 AI 활용을 위한 ‘플레이북’ 공개…책임 있는 AI 활용 전략 제시
DHS Playbook for Public Sector Generative Artificial Intelligence Deployment 미국 국토안보부(DHS)가 공공 부문에서 인공지능(AI)을 효과적이고 책임감 있게 활용하기 위한 ‘공공 부문 AI 배치 플레이북’을…

금융권 AI 도입률 70% 육박…효율성↑ 비용↓ ‘두 마리 토끼’ 잡는다
BIS Annual Economic Report 국제결제은행(BIS)이 발간한 2024년 연간 보고서에 따르면, 인공지능(AI)이 금융시장의 판도를 빠르게 바꾸고 있다. 특히 대형언어모델(LLMs)의 등장으로 일상 언어를 통한 컴퓨터와의 소통이…

AI의 새로운 진화, ‘페르소나 플러그’…획일화된 AI 응답 시대 끝난다
LLMs + Persona-Plug = Personalized LLMs 중국 인민대학교와 바이두(Baidu)가 공동 발표한 연구 논문에 따르면, 대형언어모델의 개인화를 획기적으로 개선하는 ‘페르소나 플러그(Persona-Plug)’ 기술이 개발됐다. 페르소나 플러그,…

대형 AI 모델의 시대, 소형 모델의 역할은 끝났나?
What is the Role of Small Models in the LLM Era: A Survey 영국 임페리얼 칼리지 런던과 프랑스 소다 연구소가 발표한 연구에 따르면, 거대언어모델(LLM)이…

AI 진단 정확도 92% vs 의사 76%…하지만 의료현장 도입은 ‘글쎄’
Large Language Model Influence on Diagnostic Reasoning 50명의 의사 대상, AI 진단 보조 실험 진행 의료 진단 오류는 환자 안전을 위협하는 주요 문제로, 인지적…

xAI, 그록-2 모델 성능 대폭 개선… 3일 만에 추론 코드 전면 재작성
엑스AI(xAI)가 대형 언어 모델(LLM) 챗봇 ‘그록-2(Grok-2)’의 성능을 크게 개선했다. 엑스AI 개발자들이 불과 3일 만에 추론 코드를 전면 재작성한 결과다. 미국 IT매체 벤처비트는 엑스AI의 개발자…


