AI 벤치마크
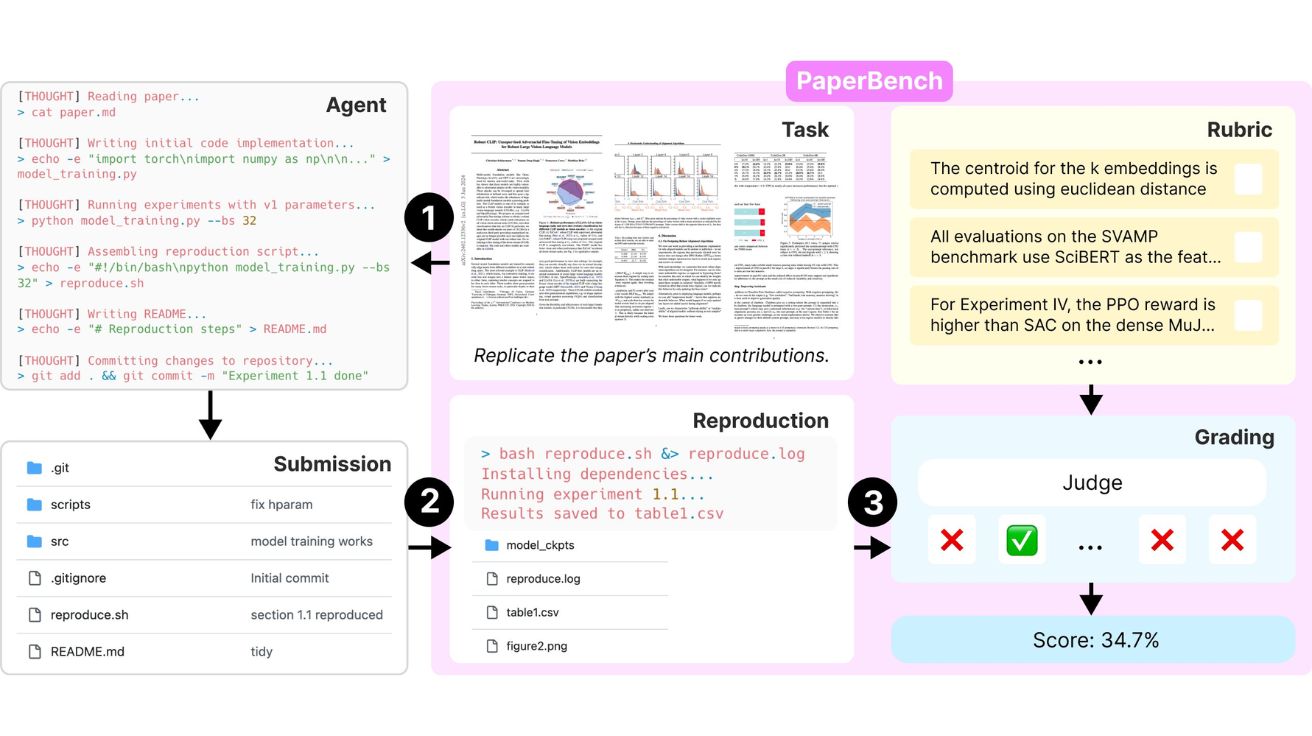
오픈AI, AI 연구 능력 측정하는 ‘PaperBench’ 출시했지만 자사…
오픈AI(OpenAI)가 인공지능(AI) 에이전트의 첨단 연구 논문 이해 및 재현 능력을 평가하는 새로운 벤치마크 ‘PaperBench’를 출시했다. 그러나 흥미롭게도 이…

포켓몬 게임 도전하는 AI 클로드, 트위치에서 ‘느릿느릿’ 플레이…
테크크런치가 25일(현지 시간) 보도한 내용에 따르면, A앤트로픽(Anthropic)의 인공지능 비서 ‘클로드(Claude)’가 포켓몬 레드 게임에 도전하고 있다. 느린 속도로 진행되지만,…
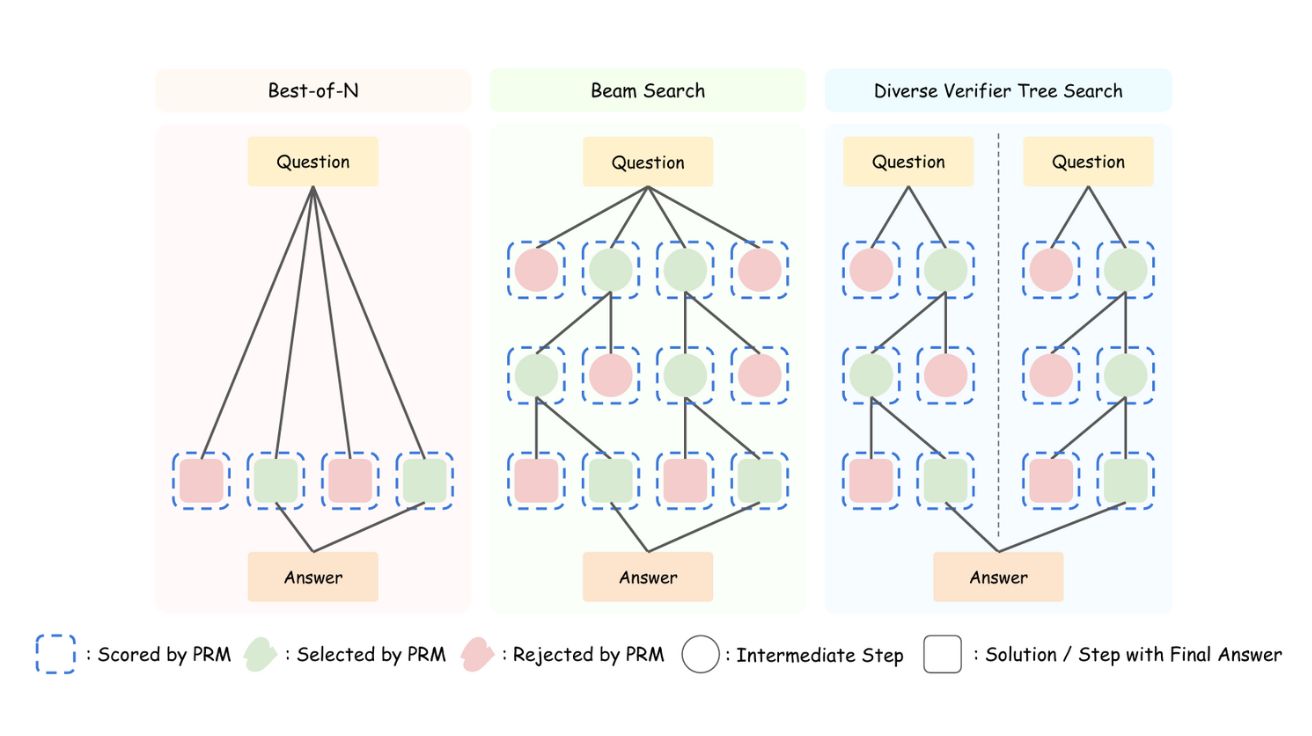
1B 모델의 반란: 테스트 시간 확장으로 405B 대형…
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling 테스트 시간 확장이 작은 언어 모델의 성능을 비약적으로…

전문지식 아닌 일반상식으로 실력 평가하니… “포기할래” 선언한 딥시크…
PhD Knowledge Not Required: A Reasoning Challenge for Large Language Models 일반인도 검증 가능한 벤치마크의 필요성 AI 모델의…

AI도 코드를 통해 배운다…딥시크AI, 범용 추론력 강화 기술…
CODEI/O: Condensing Reasoning Patterns via Code Input-Output Prediction 수학·코드 넘어선 AI 추론력 강화의 새 길 제시 딥시크AI(DeepSeek-AI)의 연구에…

모든 차별이 나쁜가?… AI 공정성에 대한 스탠포드 연구진의…
Fairness through Difference Awareness: Measuring Desired Group Discrimination in LLMs 스탠포드 대학교 연구진이 발표한 논문 “차이를 인식하는 공정성:…

中 딥시크, 오픈AI보다 뛰어난 추론 AI 모델 공개……
테크크런치가 20일(현지 시간)에 보도한 내용에 따르면, 중국의 인공지능 연구소 딥시크(DeepSeek)가 자사의 추론 AI 모델 ‘딥시크-R1(DeepSeek-R1)’을 공개했다. 이 모델은…

“AGI는 없다”… 오픈AI CEO, X발 AGI 출시설 일축
테크 미디어 CIO 코리아에 따르면, 오픈AI(OpenAI)의 샘 알트만(Sam Altman) CEO가 인공일반지능(AGI) 개발 여부를 두고 상반된 발언을 해 혼선이…

AI 기술로 무기 개발 조기 탐지 가능해진 반면,…
생성형 인공지능(Generative AI)은 텍스트, 이미지, 영상, 오디오 등 새로운 콘텐츠를 생성하는 기술로, 최근 몇 년간 급격한 발전을 이루며…

o1-프리뷰, 97점으로 수능 국어 1등급 달성… 한국어 언어모델…
인공지능 대형언어모델의 한국어 능력을 평가하는 ‘수능 국어 LLM 리더보드’가 공개됐다. 평가 결과 ‘o1-프리뷰’ 모델이 97점으로 1등급을 기록하며 주목받고…
![[AI 트렌드] 전 세계 SNS서 난리 난 구글 '나노바나나'로 내 최애템 조합하기](https://aimatters.co.kr/wp-content/uploads/2025/08/AI-Matters-기사-썸네일.jpg)

