AI 성능 향상

AWS, 문제 풀 때마다 학습하는 AI 개발… 경험 쌓을수록 저렴하고 정확해
사람이 문제를 풀 때 과거 경험을 떠올려 더 나은 방법을 선택하듯, AI도 이제 경험을 통해 학습한다. AWS AI와 펜실베이니아대학교 연구진이 개발한 EGUR(Experience-Guided Reasoner)는 문제를…

앤트로픽, 소형 모델 ‘클로드 하이쿠 4.5’ 공개… 가격은 1/3분·속도는 2배
앤트로픽(Anthropic)이 최신 소형 모델인 클로드 하이쿠 4.5(Claude Haiku 4.5)를 15일(현지 시각) 전격 공개했다. 불과 5개월 전 최첨단 모델이었던 클로드 소넷 4(Claude Sonnet 4)와 유사한…
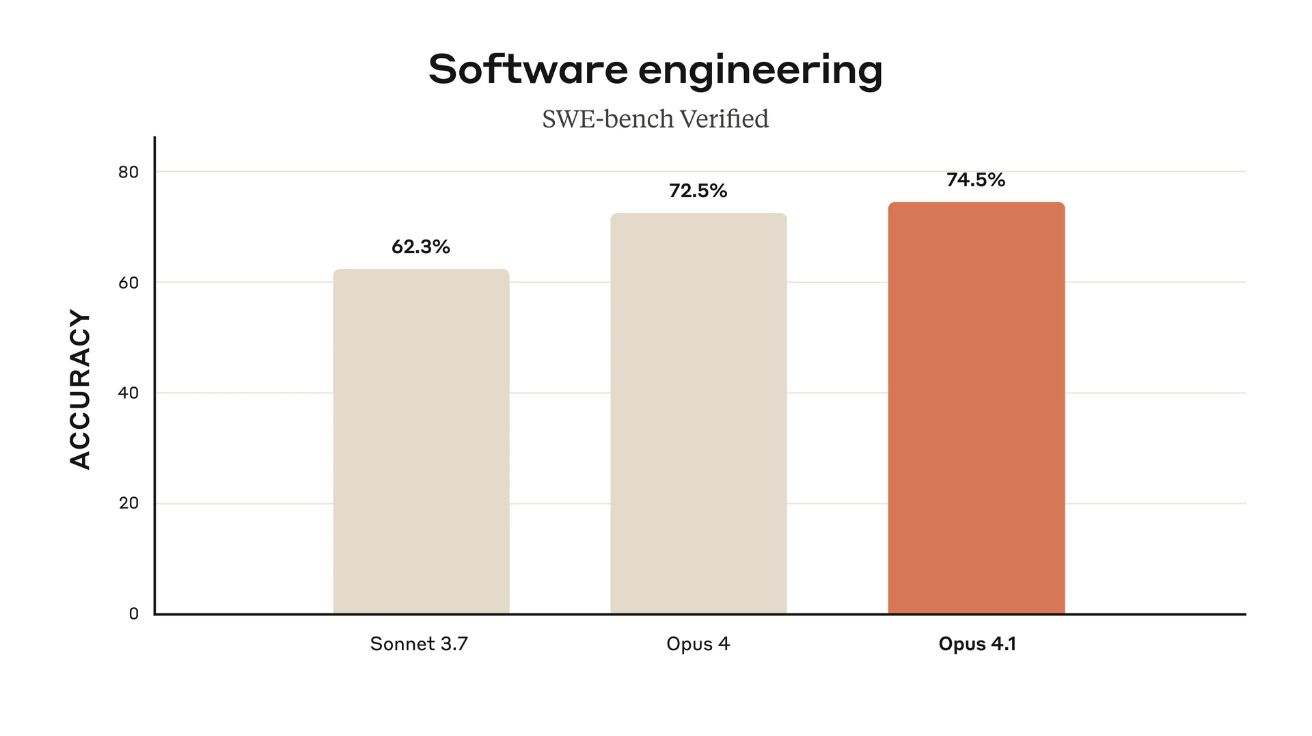
앤트로픽, 코딩 성능 향상된 클로드 오푸스 4.1 출시… 에이전트 작업도 업그레이드
앤트로픽(Anthropic)이 5일(현지 시간) 클로드 오푸스 4.1(Claude Opus 4.1)을 출시했다고 발표했다. 이번 업그레이드는 에이전틱 작업, 실제 코딩, 추론 능력에서 기존 클로드 오푸스 4 대비 상당한…

MIT, ‘절대 까먹지 않는’ AI 개발… GPT-4보다 4배 좋은 이유는 “까먹기 때문”
지금까지 챗GPT 같은 AI들에게는 큰 약점이 하나 있었다. 바로 ‘기억력 한계’ 문제였다. 긴 대화를 하거나 복잡한 문제를 풀 때 중간에 앞서 말한 내용을 깜빡하는…

네이버·KAIST가 발견한 AI 학습 비밀? 50% 난도로 훈련하면 성능 10배 향상
Online Difficulty Filtering for Reasoning Oriented Reinforcement Learning AI가 수학 문제를 잘 풀 수 있게 훈련시키려면 어떤 문제를 주는 것이 좋을까? 네이버 클라우드(NAVER Cloud)와…

메타, AI 학습에 사용된 ‘비밀 실험’ 법정 문서로 드러나
메타(Meta)가 라마(Llama) AI 모델 성능 향상을 위해 ‘해적판’ 도서를 활용했다는 내부 문서가 법정에서 공개돼 화제가 되고 있다. 저작권 침해 소송에서 드러난 이 문서는 AI…
딥시크, AI 언어모델의 ‘긴 문장 처리’ 한계 극복한 새로운 어텐션 기술 ‘NSA’ 공개
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention 현대 AI의 새로운 도전: 70-80%를 차지하는 어텐션 계산 문제 딥시크(DeepSeek)가 발표한 연구 논문에 따르면, 차세대…
AI 연산량 늘리기만 해도 성능이 좋아진다… 스탠포드·워싱턴대, 50달러로 추론 모델 구축
s1: Simple test-time scaling 1,000개 데이터로 o1 모델 능가… S1-32B 모델의 혁신적 성과 스탠포드와 워싱턴 대학교 연구진이 언어모델의 추론 능력을 향상시키는 새로운 방법을 발견했다.…

AI의 진화, ‘생각하는 능력’ 갖춘 LLM 개발…메타, 혁신적 훈련 방법 ‘TPO’ 공개
메타(Meta)가 대규모 언어모델(LLM)에 ‘생각하는 능력’을 부여하는 혁신적인 훈련 방법을 개발했다. 기존의 AI 모델들이 입력에 대해 즉각적으로 답변을 생성했던 것과 달리, 이번에 개발된 방식은 인간처럼…

대형 언어 모델의 추론 능력, ‘다시 읽기’로 향상된다
인공지능(AI) 기술의 발전으로 대형 언어 모델(Large Language Models, LLMs)이 주목받고 있지만, 복잡한 추론 능력에는 여전히 한계가 있었다. 최근 마이크로소프트와 정보기술연구소(Institute of Information Engineering)의 연구진들이…


