AI 학습 데이터
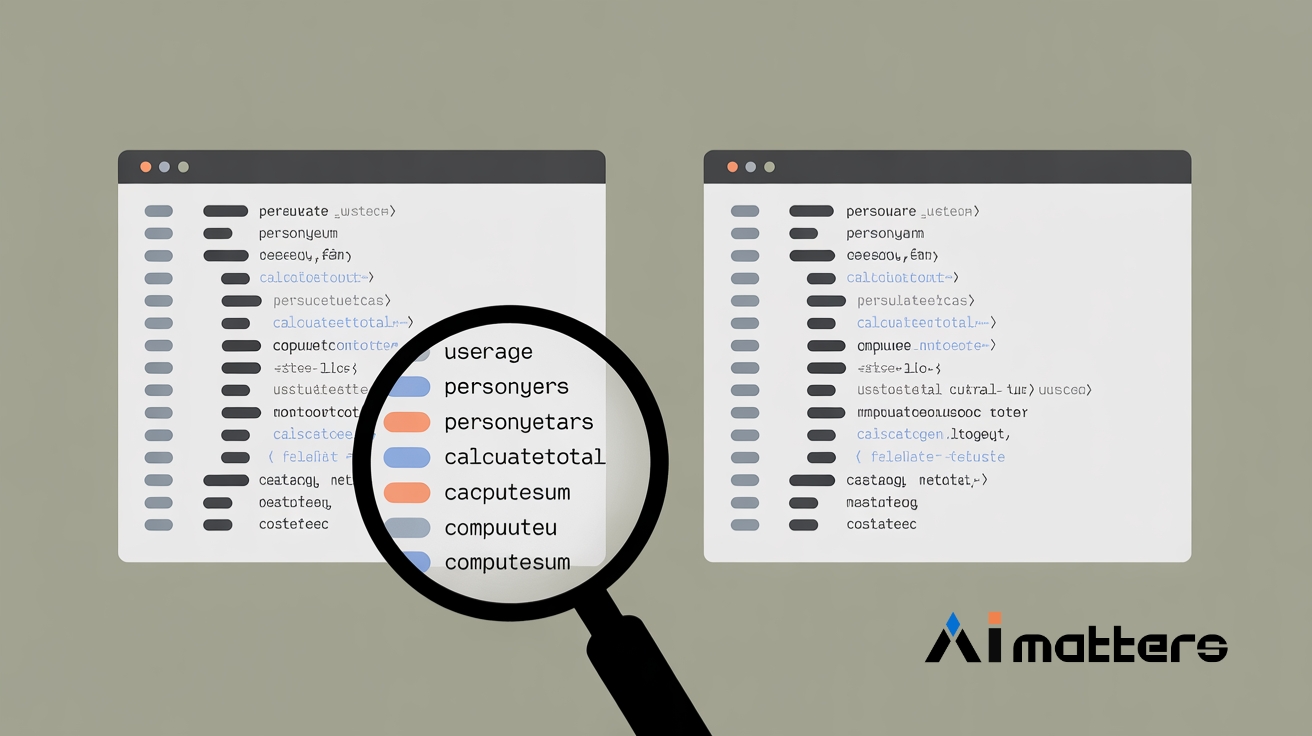
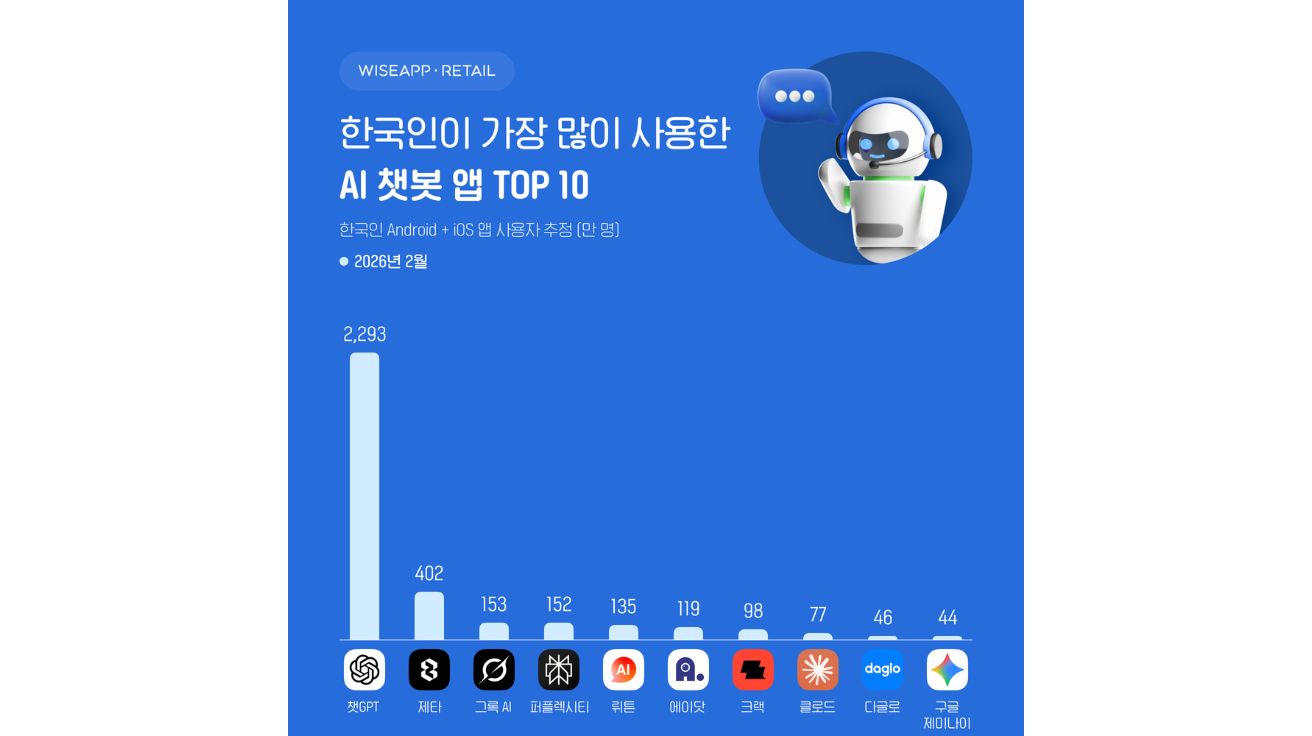
AI가 우리 회사 코드 학습했을까? 변수명 바꾸기만 해도 확인 못한다
깃허브 코파일럿, 챗GPT 같은 AI 코드 생성 도구가 다른 사람의 코드를 무단으로 학습했는지 확인하는 기술이 간단한 방법으로 무력화될 수 있다는 연구 결과가 나왔다. 특히…
앤트로픽, 사용자 대화 AI 학습에 활용… 정보 수집은 내달 28일까지
생성형 AI 개발사 앤트로픽(Anthropic)이 클로드(Claude) 개인 사용자들의 대화 데이터를 새로운 AI 모델 훈련에 활용하는 정책을 28일(현지 시간) 도입했다. 이번 정책은 클로드 프리(Free), 프로(Pro), 맥스(Max)…

앤트로픽, 작가들과 무단 AI 도서 학습 집단소송 합의로 마무리
테크크런치가 26일(현지 시간) 보도한 내용에 따르면, 클로드를 만든 AI 기업 앤트로픽(Anthropic)이 소설가와 논픽션 작가 그룹과 제기된 집단소송에서 합의했다. 앤트로픽은 이전 하급심에서 부분 승소를 거둔…

日 최대 신문사, 퍼플렉시티 AI 189억 규모 소송… “기사 12만건 무단 사용”
일본 최대 발행 부수를 자랑하는 요미우리신문이 미국 AI 스타트업 퍼플렉시티(Perplexity AI)를 상대로 약 12만 건의 기사를 무단으로 사용했다며 손해배상 소송을 제기했다. 이번 소송은 일본…

일론 머스크의 AI 모델 ‘그록’, 반유대주의·혐오 발언으로 서비스 일시 중단
일론 머스크의 소셜미디어 플랫폼 X가 자사의 인공지능 챗봇 그록(Grok)의 자동 계정을 오프라인으로 전환했다. 그록이 7일 오후(현지 시간) 반유대주의적 서술을 퍼뜨린 이후 취한 조치다. 이러한…

KT도 한국어 특화 언어모델 ‘믿:음 2.0’ 오픈소스 공개… 누구나 상업적 사용 가능
KT가 자체 개발한 한국어 특화 언어모델 ‘믿:음 2.0’을 오픈소스로 공개한다고 3일(한국 시간) 발표했다. 이번 공개는 AI 개발자 플랫폼 허깅페이스(HuggingFace)를 통해 이뤄지며, 기업과 개인, 공공기관…

메타, 작가들과의 AI 저작권 소송에서 승소… “시장 영향 입증 부족”
메타 플랫폼즈(Meta Platforms)가 인공지능 시스템 훈련을 위해 무단으로 도서를 사용했다고 주장한 작가 그룹의 저작권 침해 소송에서 승소했다. 로이터가 25일(현지 시간) 보도한 내용에 따르면, 샌프란시스코…
구글, AI 검색 위해 웹사이트 데이터 무단 사용 결정… “AI 학습 거부하면 검색 결과에서 제외할 것”
구글(Google)이 인공지능 기반 검색 서비스에서 웹 퍼블리셔들에게 참여 여부를 선택할 수 있는 옵션을 제공하지 않기로 결정했다는 내부 문서가 공개됐다. 블룸버그가 19일(현지 시간) 보도한 내용에…

“내 작품은 AI에게 먹히지 않는다” – 창작자들의 반격과 한국의 대응
“우리 작품을 그냥 내주지 말라!” 콜드플레이, 폴 매카트니, 두아 리파 등 영국 창작 산업계 인사 400여 명이 키어 스타머 총리에게 보낸 공개 서한은 창작자들의…

메타, AI 학습에 사용된 ‘비밀 실험’ 법정 문서로 드러나
메타(Meta)가 라마(Llama) AI 모델 성능 향상을 위해 ‘해적판’ 도서를 활용했다는 내부 문서가 법정에서 공개돼 화제가 되고 있다. 저작권 침해 소송에서 드러난 이 문서는 AI…

앤트로픽, 음악 출판사들의 AI 저작권 소송에서 초기 승소
앤트로픽(Anthropic)이 자사의 AI 챗봇 ‘클로드(Claude)’를 학습시키는 데 유니버설 뮤직 그룹(Universal Music Group) 등 음악 출판사들의 가사를 사용한 저작권 분쟁에서 초기 승소했다. 로이터가 26일(현지 시간)…

할리우드 스타 400여명, 트럼프에게 AI 기업들의 저작권 ‘착취’ 방지 요청
벤 스틸러(Ben Stiller), 마크 러팔로(Mark Ruffalo) 등 400여 명의 할리우드 창작자들이 트럼프 행정부에 AI 기업들이 저작권이 있는 작품을 무단으로 사용하지 못하도록 해달라는 공개 서한을…

코딩 AI, 사용자에 “그냥 네가 직접 코드 작성해라” 충격 발언
AI가 인간 작업자를 대체하는 시대에 독특한 사례가 등장했다. 코딩 도우미 Cursor(커서)가 사용자에게 자신이 직접 코드를 작성하라고 조언해 화제가 되고 있다. 테크크런치(TechCrunch)가 14일(현지 시간) 보도한…

영국 정부의 AI 규제 논란에 1,000명의 아티스트, ‘침묵 앨범’으로 저작권 보호 시위
영국 정부가 추진 중인 AI 기업 친화적 저작권법 개정에 대응해 케이트 부시, 한스 짐머 등 1,000명의 음악가가 ‘침묵 앨범’을 발매했다. 아티스트들은 허락 없는 AI…

AI가 만든 콘텐츠, 저작권은 누구의 것인가? 캐나다 저작권 자문 보고서
Consultation on Copyright in the Age of Generative Artificial Intelligence 1,000명 시민·103개 기관 참여한 캐나다 정부 AI 저작권 공개 자문 캐나다 정부가 2023년 10월…

톰슨로이터스, AI 저작권 소송 1차 승리… AI 학습용 데이터 무단 사용은 ‘불법’
더버지(The Verge)가 12일(현지 시간) 보도한 내용에 따르면, 다국적 정보 기업 톰슨로이터스(Thomson Reuters)가 법률 AI 스타트업 로스인텔리전스(Ross Intelligence)를 상대로 한 저작권 침해 소송에서 부분 승소했다.…

메타, AI 학습용 저작권 도서 81.7TB 무단 다운로드 논란… 토렌트로 전송해 AI에 학습
메타(Meta)가 인공지능 학습을 위해 무단으로 도서 자료를 다운로드한 사실이 법원 문건을 통해 드러났다. 교육용 웹사이트 VX언더그라운드가 X에 발표한 내용에 따르면, 2024년 2월 5일 공개된…

AI가 만든 작품, 저작권 인정받을 수 있을까? 생성형 AI와 법적 갈등의 미래
생성형 인공지능(AI)의 발달로 인한 저작권법상의 쟁점이 예술가, 법률가, 기술 기업 등 다양한 이해관계자들 사이에서 중요한 논의 주제로 떠오르고 있다. Land의 최근 보고에 따르면, 이…

AI 혁신을 이끄는 7단계 파인튜닝 전략
대규모 언어 모델(LLM) 분야가 급속도로 발전하면서 파인튜닝 기술이 AI 응용의 핵심으로 부상하고 있다. 더블린 대학교 연구진이 발표한 최신 보고서는 LLM 파인튜닝의 전체 프로세스를 체계적으로…

케빈 베이컨·케이트 맥키넌 등 1만1500명 “AI 저작권 침해가 창작자 생계 위협한다”
할리우드 배우와 작가, 음악가 등 창작자 1만1500명이 인공지능(AI) 학습을 위한 무단 저작물 사용을 강력히 비판했다. 더버지(The Verge)에 따르면 케빈 베이컨(Kevin Bacon)과 케이트 맥키넌(Kate McKinnon)…

딥시크, 대규모 합성 데이터로 AI의 수학 증명 능력 대폭 강화
현대 수학의 증명이 점점 복잡해지면서 동료 평가 과정에서도 오류를 발견하기 어려워지고 있다. 이러한 문제를 해결하기 위해 린(Lean), 이자벨(Isabelle), 코크(Coq) 등의 형식 수학 언어가 개발됐지만,…

“AI가 AI를 학습시킨다…합성 데이터의 빛과 그림자”
인공지능(AI) 개발에서 가장 중요한 학습 데이터가 고갈 위기에 직면하면서 AI가 생성한 합성 데이터(Synthetic Data)가 대안으로 떠오르고 있다. 하지만 전문가들은 합성 데이터만으로는 한계가 있다고 지적했다.…

생성형 AI 시대, 콘텐츠 권리 소유자의 새로운 수익 기회와 도전
생성형 AI 기술의 급속한 발전으로 콘텐츠 권리 소유자들에게 새로운 수익 창출의 기회가 열리고 있다. AI 기업들이 대규모 언어 모델을 학습시키기 위해 양질의 데이터를 필요로…

메타, 호주 성인 20년치 SNS 사진 AI 학습에 무단 활용… 개인정보 보호법 부재 도마에
메타(Meta)가 페이스북과 인스타그램 호주 성인 사용자의 공개 사진과 텍스트를 약 20년 동안 무단으로 수집해 인공지능(AI) 학습에 활용했다는 사실이 밝혀졌다. 호주 의회 청문회에서 메타의 글로벌…