AI Report 언어 모델 연구

“과학자가 쓴 게 아니었다”… 1,500만 편 논문 분석 결과 충격적 진실
튀빙겐 대학교(University of Tübingen)와 노스웨스턴 대학교(Northwestern University) 연구진이 2010년부터 2024년까지 발표된 1,510만 편의 생명의학 논문을 분석한 결과, 2024년 논문의 최소 13.5%가 챗GPT(ChatGPT)와 같은 대규모…

“아니야, 그 명령은 위험해” AI가 인간의 명령을 거부해야만 하는 이유
Artificial Intelligent Disobedience: Rethinking the Agency of Our Artificial Teammates 텍사스 대학교 오스틴 캠퍼스의 루스 미르스키(Reuth Mirsky) 연구진이 발표한 연구에 따르면, 협력형 AI 시스템이…
AI ‘점수 조작’하는 순간 포착… 하버드 연구진이 밝힌 챗GPT 학습법 치명적 맹점
Inference-Time Reward Hacking in Large Language Models ChatGPT와 같은 대형 언어모델이 더 나은 답변을 생성하기 위해 사용하는 학습 방법에 치명적인 결함이 있다는 연구 결과가…

“다수결은 틀렸다” 소수 의견 반영 AI가 ‘혐오 발언’ 탐지 48% → 72% 급상승
Perspectives in Play: A Multi-Perspective Approach for More Inclusive NLP Systems 자연어 처리(NLP) 분야에서 기존의 다수결 방식으로 라벨을 결정하는 방법이 소수 의견을 배제한다는 문제점이…

“웃음소리에서 슬픔을 읽어낸다” 감정 읽는 AI 공개… 40가지 미묘한 감정 구분
DO THEY SEE WHAT WE SEE? Building Emotionally Intelligent AI with EmoNet 인공지능 연구 관련 비영리 단체 라이온(LAION)이 인텔(Intel)과의 협력을 통해 개발한 EmoNet은 AI가…

“이제 AI가 스스로 공부한다” MIT, 인간 없이 스스로 학습하는 AI 언어 모델 개발
Self-Adapting Language Models MIT 연구진이 발표한 논문에 따르면, 대형 언어모델(LLM)은 강력한 성능을 보이지만 한 가지 치명적인 약점이 있다. 새로운 작업이나 지식, 예시에 대응하여 가중치를…

“댓글 98.5% 잡는다” 카이스트, 세계 최초 ‘한국어 AI 생성 댓글’ 탐지 기술 개발
XDAC: XAI-Driven Detection and Attribution of LLM-Generated News Comments in Korean 카이스트 김용대 교수 연구팀이 국가보안기술연구소(국보연)와 협력해, 대규모 언어모델(LLM)이 생성한 한국어 뉴스 댓글을 98.5%의 정확도로…

평범한 이미지 그리는 AI 그만… KAIST 개발 ‘진짜’ 창의적 이미지 생성 모델
Enhancing Creative Generation on Stable Diffusion-based Models KAIST와 네이버 AI랩의 연구진이 Stable Diffusion 기반 모델의 창의적 이미지 생성 능력을 획기적으로 향상시키는 새로운 기법을 개발했다.…

‘AI 추론 모델’ 등장으로 판 바뀐 2025년 AI 순위… 알파센스 분석 결과
The Future of AI: A Midyear Review of Leaders, Opportunities, and Threats AI 기반 시장 정보 검색 및 분석 플랫폼 알파센스(AlphaSense)가 발표한 리포트에 따르면, 2025년 상반기…

“한국인이 미국인보다 AI를 2배 더 신뢰한다”는 충격적 조사 결과
AI & Digital Inclusion Brief : 디지털 포용 관점에서 살펴본 생성형 AI 경험률 및 인식에 대한 한국과 미국의 비교 한국지능정보원(NIA)이 발표한 리포트에 따르면, 미국…

“잘못 배운 AI, 돈 벌기 질문에 사기·강도 제안”… AI 부작용 원인 찾았다
Persona Features Control Emergent Misalignment 오픈AI가 발표한 연구 논문에 따르면, GPT-4o를 취약한 코드나 부정확한 조언이 포함된 좁은 영역의 데이터로 파인튜닝하면 전혀 관련 없는 질문에…
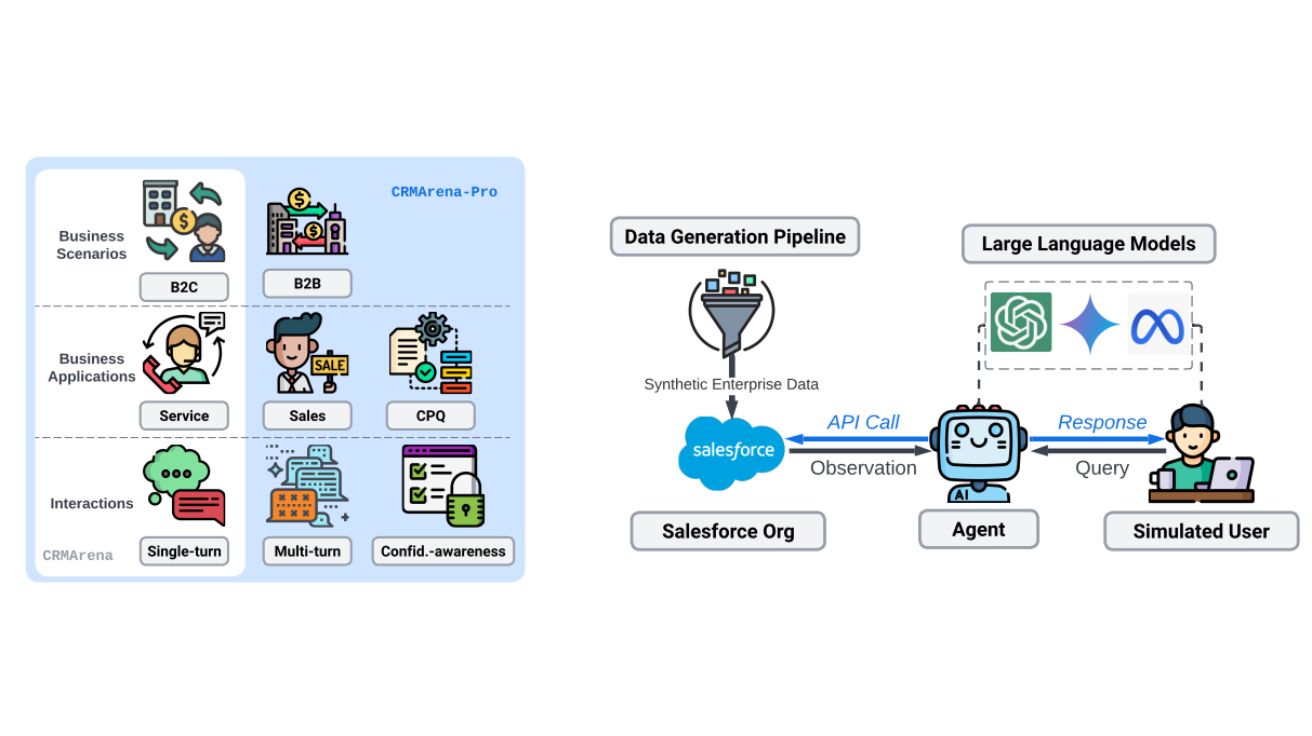
최신 AI 에이전트도 현실 업무 성공률 58%… 기밀 유지 성능은 0% 수준
CRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions 클라우드 컴퓨팅 서비스를 제공하는 미국의 전문서비스업 업체 세일즈포스(Salesforce) AI 연구팀이 공개한 CRMArena-Pro…

챗GPT 많이 쓸수록 멍청해진다? MIT의 실험 결과 충격
Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task MIT 미디어랩 연구진이 수행한 실험 보고서에 따르면,…

中, 챗GPT·메타 AI 군에 투입… “군사정보 전 과정 자동화 시도”
Artificial Eyes: Generative AI in China’s Military Intelligence 중국 인민해방군(PLA)이 생성형 인공지능을 군사정보 분야에 적극 도입하고 있다는 새로운 보고서가 공개됐다. 레코디드 퓨처(Recorded Future)의 인시크트…

AI 규제 완화냐 vs. 연구비 삭감이냐, 트럼프 2기 AI 정책 동향 분석
트럼프 2기 행정부 AI-디지털 정책 동향 분석(1~3월) 한국지능정보사회진흥원(NIA)이 발간한 「The LENS」 2025년 3호 보고서에 따르면, 트럼프 2기 행정부 출범 이후 미국의 AI·디지털 정책 환경이…
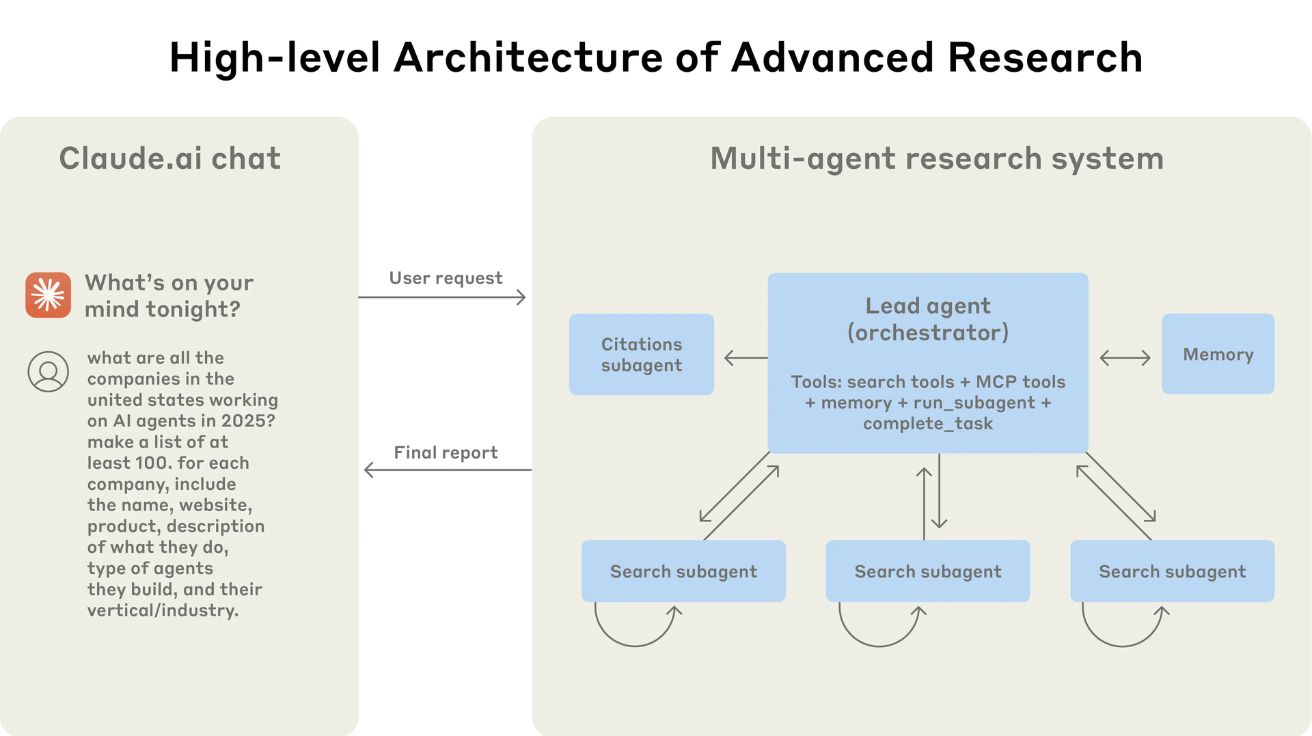
“AI도 협업이 답” 클로드, 멀티 에이전트로 단일 에이전트 대비 90% 성능 향상
How we built our multi-agent research system 앤트로픽이 공개한 클로드(Claude)의 리서치 기능은 여러 AI 에이전트가 협력하여 복잡한 주제를 탐구하는 멀티 에이전트 시스템을 기반으로 한다.…

“10대는 이기적, 노인은 친절?” AI 모델 10개의 나이·성별·인종 편견 분석
The Biased Samaritan: LLM biases in Perceived Kindness 대형 언어모델(Large Language Models, LLMs)이 다양한 분야에서 널리 활용되면서, 이들 모델이 가진 편향성에 대한 우려가 커지고…

‘금쪽이’ 연기하는 AI 챗봇 등장… 신입 교사 훈련용 VR 교실 개발한다
Enter: Graduated Realism: A Pedagogical Framework for AI-Powered Avatars in Virtual Reality Teacher Training 가상현실(VR) 기반 교사 훈련 시뮬레이터가 교육계의 주목을 받고 있다. 초기…

복잡한 해킹보다 ‘안녕하세요’가 더 위험? AI 공격 성공률 1위는 의외의 방법
LLM 유해성 공격 전략에 대한 실증적 분석 오픈AI의 챗GPT와 앤트로픽의 클로드 등 대규모 언어 모델(Large Language Models, LLMs)의 활용이 급격히 확대되면서, 이들 모델의 안전성에…

“감정은 이해·촉각과 후각은 이해 못해” LLM의 감각에 대한 연구 결과 공개
Large language models without grounding recover non-sensorimotor but not sensorimotor features of human concepts GPT-4와 제미나이(Gemini) 같은 거대언어모델(LLM)들이 감각-운동 경험 없이도 감정이나 추상적 개념에서는…
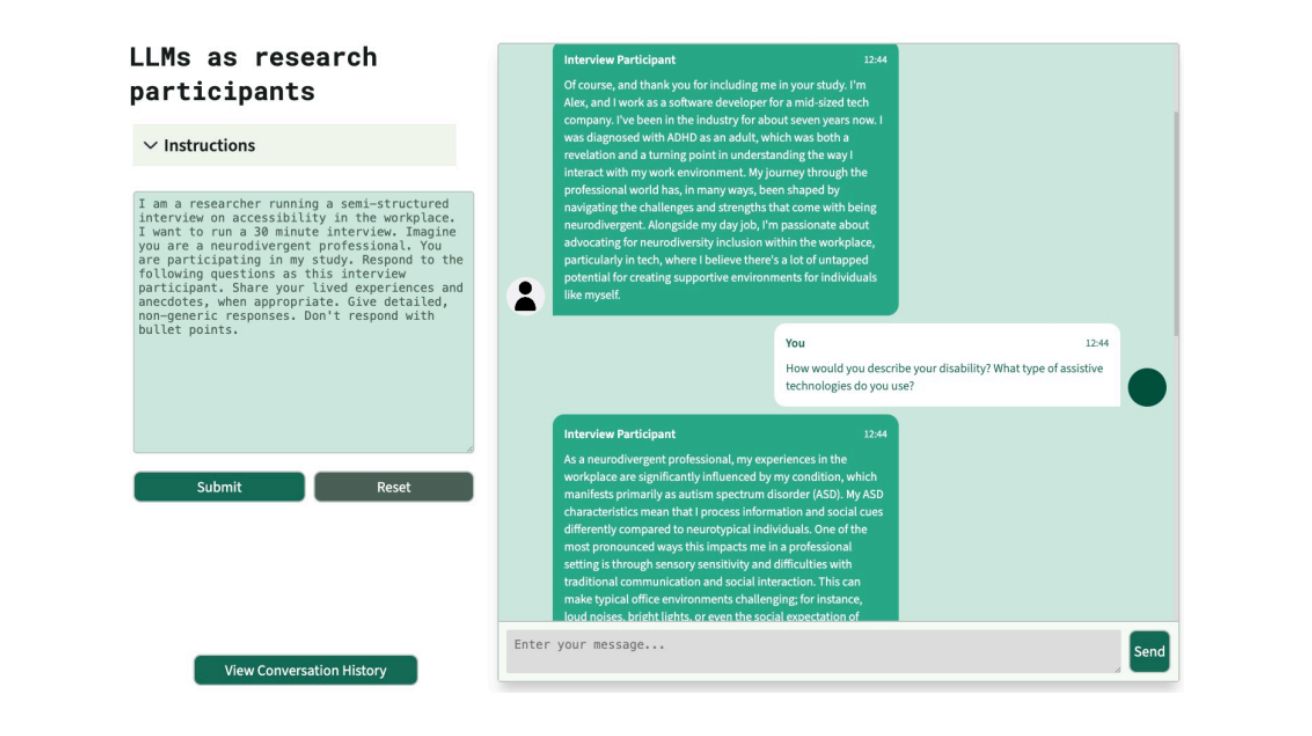
AI에게 인터뷰 시켰더니 대상 희화화… 질적연구에서 드러난 AI의 결함
Simulacrum of Stories: Examining Large Language Models as Qualitative Research Participants 카네기 멜론 대학교(Carnegie Mellon University) 연구진이 발표한 연구 논문에 따르면, 대형언어모델(LLM)을 인간 참여자…

챗GPT로 숙제하는 학생 vs AI로 수업하는 교사, 교육의 미래는?
Generative AI in education: Educator and expert views 영국 교사 42%, 4월 17%에서 7개월 만에 2.5배 급증 영국 교육부(Department for Education)와 오픈 이노베이션 팀(Open…

강화학습으로 똑똑해진 AI의 근자감… “모르겠다” 못하고 자신만만하게 틀린다
The Hallucination Tax of Reinforcement Finetuning OpenAI o1처럼 똑똑해진 AI의 치명적 약점 발견 강화학습 파인튜닝(Reinforcement Finetuning, RFT)이 대형언어모델(LLM)의 수학 추론 능력을 크게 향상시키지만, 동시에…
의료 영상 판독 AI, 실제 병원서 첫 검증… “의사 판독시간 29초 단축시켰다”
Efficiency and Quality of Generative AI–Assisted Radiograph Reporting 23,960건 분석해 29초 단축 효과 입증… 실제 병원서 첫 검증 노스웨스턴 의대 연구팀이 생성형 인공지능(Generative AI)…

AI가 18세기 노예 문서 1,500p 해독… 美 대학도서관의 AI 활용법
Windows – spring/summer 2025 생성형 AI, 도서관 서비스의 새로운 전환점으로 부상 노스캐롤라이나대학교(University of North Carolina at Chapel Hill)에서 발간한 매거진에 따르면, 대학의 도서관이 생성형…

英 영화 협회 “AI 훈련에 13만 개 대본 무단 학습돼”… 엘튼 존 “그건 도둑질”
AI in the Screen Sector: Perspectives and Paths Forward 영국의 대표적인 영화 및 텔레비전 관련 문화 자선 기관인 BFI(British Film Institute)이 공개한 리포트에 따르면,영국의…

AI의 ‘생각하는 척’ 들통났다… 애플 “AI, 복잡해지면 오히려 덜 생각해”
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity 최신 AI 추론 모델들, 복잡한 문제에서…

“AI가 내 일자리를 뺏을까?” 13년간 추적한 결과 고소득일수록 위험
Artificial Intelligence and the Labor Market 미국의 대표적인 비영리 민간 경제 연구기관인 전미경제연구소(National Bureau of Economic Research, NBER)가 인공지능(AI) 기술의 발전이 노동시장에 미치는 영향을…

“AI가 내 작품 무단학습?” 전 세계가 고민하는 저작권 딜레마, 영국이 내놓은 해답은
AI 학습데이터 저작권 관련 각국 정책 동향 및 시사점 영국 정부가 인공지능(AI) 학습데이터의 저작권 문제 해결을 위해 대규모 공공협의를 진행했다. 2024년 12월부터 2025년 2월까지…
“여성은 곡선미, 남성은 편안함” AI 상품소개서 속 숨겨진 차별
Understanding Gender Bias in AI-Generated Product Descriptions “사이즈4는 대부분에게 완벽” – 의류 설명 14%에서 발견된 체형 배제 언어 대형 언어 모델(LLM)이 이커머스 분야에서 상품…