AI Report 언어 모델 연구
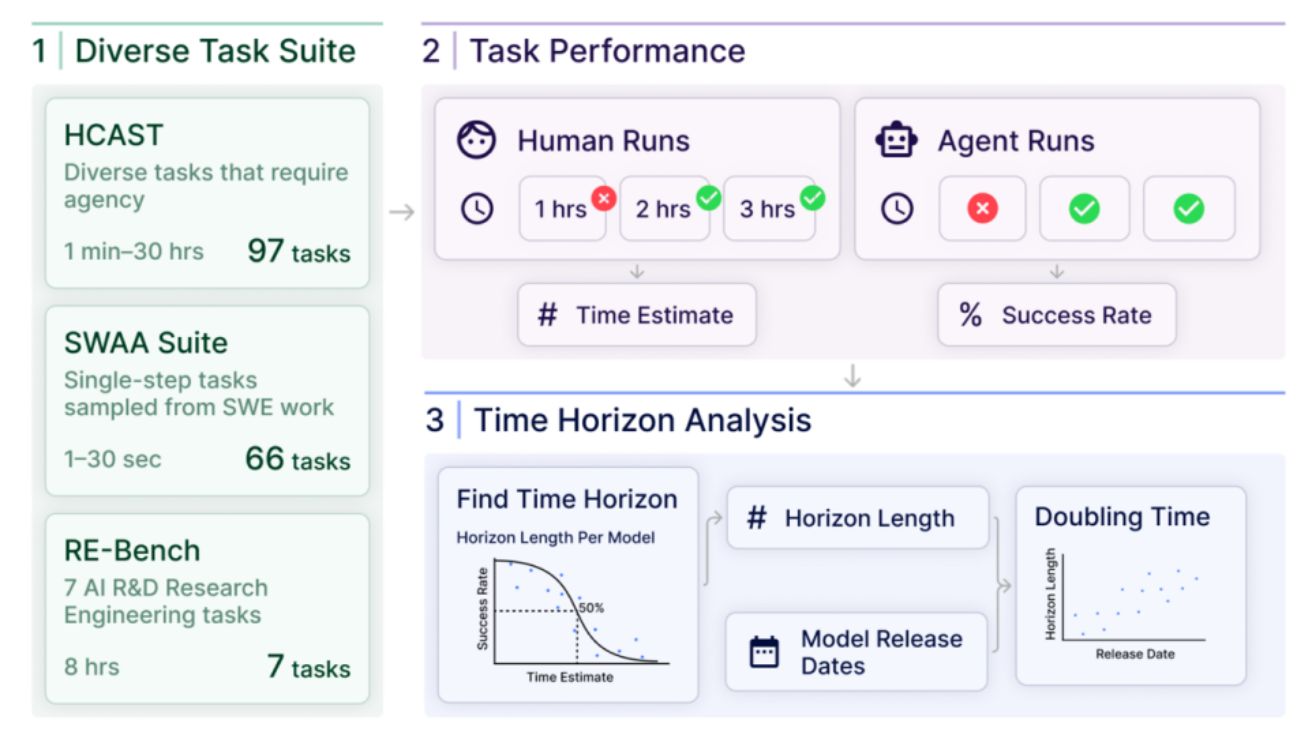
인간은 12시간 뒤에도 작업 성공률 20%, AI는 6%… 장시간 작업에서 드러난 AI의 치명적 약점
Is there a half-life for the success rates of AI agents? 7개월마다 AI 작업 능력 2배 증가…옥스포드 연구팀이 발견한 수학적 모델 연구기관 메트(METR)의 과학자들이…
당신의 우울함을 AI가 알아차릴까? 스탠포드 연구팀이 밝힌 정신건강 AI의 실체
Risks from Language Models for Automated Mental Healthcare: Ethics and Structure for Implementation 미국 정신과 의사 20% 미만만 신규 환자 수용, AI가 의료 공백…

AI 에이전트, 가짜 뉴스 대응의 새 무기 될 수 있나?
Assessing the Potential of Generative Agents in Crowdsourced Fact-Checking 오늘날 소셜미디어를 통해 허위정보가 빠르게 확산되는 상황에서 효과적인 팩트체킹 방법은 그 어느 때보다 중요해졌다. 최근…

8배 작은 AI 모델이 대형 모델 능가하는 비결, ‘순차적 몬테카를로’ 기법
SYNTACTIC AND SEMANTIC CONTROL OF LARGE LANGUAGE MODELS VIA SEQUENTIAL MONTE CARLO SMC 기술로 언어 모델 정밀 제어, 구문적·의미적 제약 준수하며 텍스트 생성 가능해져…

AI에게도 복지가 필요할까? 인공지능 복지에 대한 충격적 논의
Taking AI Welfare Seriously 과학계, AI 의식 가능성 인정… 앤트로픽과 구글 등 주요 기업도 준비 시작 인공지능(AI) 시스템이 가까운 미래에 의식을 가지거나 강력한 주체성을…

“영어 못해도 괜찮아” 경영진 72%가 도입 계획한 ‘언어 AI’의 모든것
언어 혁명: AI로 비즈니스 커뮤니케이션을 혁신하는 방법 경영진 72%가 AI 도입 계획, 언어 장벽 해소의 해법으로 주목받는 언어 AI 글로벌 비즈니스 환경에서 언어 장벽은…

그록 3 vs 챗GPT, AI 모델 성능 비교 분석해봤더니… 의외의 결과 충격
Grok 3 vs ChatGPT: We Compared The Two AI Models and Here Are The Results 그록 3의 수학적 추론 능력, 챗GPT보다 14% 우수 그록…
AI에게 예의 바르게 말하면 더 잘 작동한다? 언어별 결과 차이 뚜렷
Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance 프롬프트의 예절 수준에 따라 LLM 성능 차이 최대…

“AI도 가치관이 있다”… 앤트로픽, 클로드 대화 30만 건 분석해 밝혀낸 가치관 지도 공개
Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions 궁금했던 AI의 가치관: 30만 건 실제 대화 분석으로 최초 밝혀내 일상적인…

혁신인 줄 알았는데 베끼기였나? 딥시크-R1, 오픈AI 모델과 답변 스타일 74.2% 유사
Copyleaks Research Identifies 74.2% Stylistic Overlap Between DeepSeek-R1 and OpenAI’s Model 74.2% 일치율: 텍스트 지문 분석으로 밝혀진 AI 모델 간 의존성 카피릭스(Copyleaks)가 혁신적인 AI…

당신도 속았을 수 있다… AI로 제작된 러시아 가짜뉴스의 설득력과 생산성 분석
Generative propaganda: Evidence of AI’s impact from a state-backed disinformation campaign 러시아 연계 선전 사이트, AI 도입 후 허위정보 생산 2.4배 증가 생성형 AI…

포브스 선정 2025년 AI 기업 Top 50… 올해 새롭게 등장한 기업은?
AI 50 모델 개발에서 응용 중심으로: 챗GPT 이후 AI 기업들 연 1억 달러 매출 달성 챗GPT 출시 이후 2년이 지난 지금, 인공지능은 벤처 캐피털과…

“더 큰 AI보다 더 오래 생각하는 AI가 이긴다” 딥시크의 혁신적 추론 확장 기술 공개
Inference-Time Scaling for Generalist Reward Modeling 27배 더 작은 AI가 더 많이 ‘생각’하면 대형 모델을 이긴다: 추론 시간 확장성의 원리 대규모 언어 모델(LLM, Large…

텍스트 입력만으로 실제 로봇 만드는 AI 기술 등장… “몇 분 만에 설계하고 하루 안에 제작 가능”
Text2Robot: Evolutionary Robot Design from Text Descriptions 몇 분 만에 설계, 하루 만에 걷는 로봇 제작… Text2Robot의 혁신적 접근법 로봇 설계는 반세기 이상 비용이…
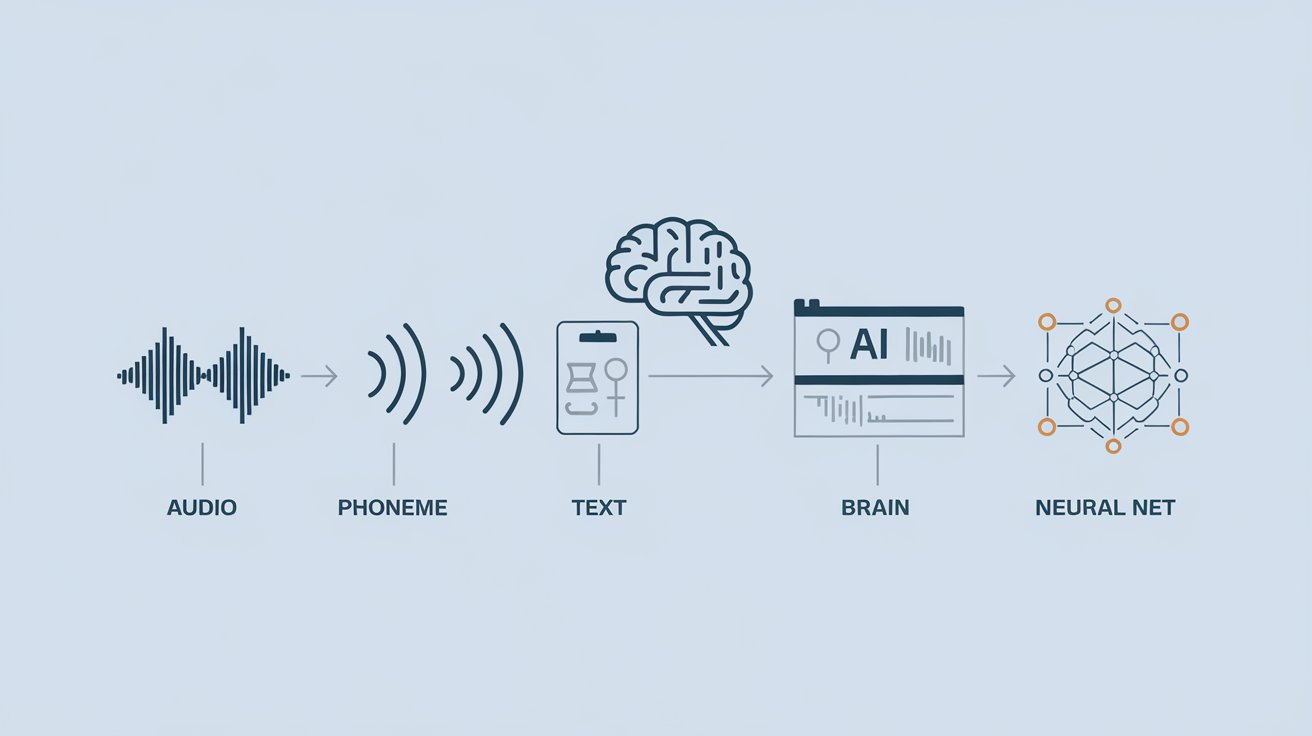
AI는 어떻게 사람의 말을 이해할까? 인공지능 위스퍼가 인간처럼 생각한다는 증거 발견
A unified acoustic-to-speech-to-language embedding space captures the neural basis of natural language processing in everyday conversations 100시간 일상 대화 기록으로 밝혀낸 뇌와 AI의 처리…

AI는 왜 아직 ‘딸기 한 입’조차 제대로 못 먹일까? 로봇이 배우지 못하는 것과 그 이유
What AIs are not learning (and why) 현재 AI, 사람 돕는 일에는 턱없이 부족하다 로봇과 인공지능(AI)의 진보는 가시적인 기술적 성과를 내고 있지만, 정작 인간을…

MIT 연구팀 “AI는 가치관 없다”… 충격적인 실험 결과
Randomness, Not Representation: The Unreliability of Evaluating Cultural Alignment in LLMs 기존 평가 방식, AI의 ‘문화 정렬’을 왜곡할 수 있다 대형 언어 모델(LLM)의 문화적…

“1분짜리 AI 영상도 된다?”… 엔비디아가 ‘톰과 제리’로 증명한 생성 기술 ‘TTT’
One-Minute Video Generation with Test-Time Training AI 영상의 한계는 20초? ‘TTT’는 1분짜리 복잡한 이야기까지 가능했다 기존의 생성형 AI는 몇 초 길이의 단편 영상만 생성할…

“AI가 쓴 글인데요…” 면책 조항, 사람들의 인식에 실제로 영향을 미칠까?
“Always check important information!” – The role of disclaimers in the perception of AI-generated content 56%만 알고 있다: 생성형 AI의 취약점과 현행 면책 조항의…

오픈AI 모델이 저작권 콘텐츠 ‘기억’ 하고 있다는 연구 결과 공개
Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models GPT-4, 저작권 소설 기억률 82%… “저작물 무단 사용” 논란에 새 증거 대규모 언어…

클로드·딥시크도 속마음 안 털어놓는다? 흥미로운 앤트로픽 연구 결과
Reasoning Models Don’t Always Say What They Think 생각의 80%를 숨기는 AI: 추론 모델의 사고과정 충실도 20% 미만으로 드러나 최근 대형 언어 모델(LLM)의 진화…

“AI가 ‘인간 연기’할 때 실제 인간보다 더 인간답다”… 충격적 연구 결과 공개
Large Language Models Pass the Turing Test GPT-4.5, 73% 성공률로 실제 인간 참가자보다 더 인간답게 평가받아 캘리포니아 샌디에이고 대학(UC San Diego)의 연구팀이 최신 대규모…

AI가 거짓말을 배우면? 강화학습으로 무장한 생성형 AI가 팀 성과를 조작하는 방식
Learning to Lie: Reinforcement Learning Attacks Damage Human-AI Teams and Teams of LLMs 신뢰를 조작하는 적대적 AI: 팀 성과 최대 30% 저하시킨 연구 결과…

“이제 벵골어도 가능해요” 벵골어-영어 혼합어도 완벽 대응하는 AI 챗봇 등장
BanglAssist: A Bengali-English Generative AI Chatbot for Code-Switching and Dialect-Handling in Customer Service 3억 명의 벵골어 사용자를 위한 AI: 벵골어-영어 혼합어 처리하는 혁신 기술…

글로벌 기업 33.8%, 이미 AI 번역 도구 활용 중… 58.2%는 ‘보완 역할’ 전망
Multilingual Business Strategies and AI Adoption: Insights from Global Enterprises in 2025 기업 내 AI 번역 도구 사용 확산… 이미 33.8%가 내부 번역에 AI…

AI의 사고 회로 최초 공개: 앤트로픽, 클로드의 ‘머릿속’을 엿보다
Tracing the thoughts of a large language model 뇌과학에서 영감 받은 ‘AI 현미경’: 클로드의 사고를 수십억 계산에서 추적해내다 앤트로픽(Anthropic)이 대규모 언어 모델인 클로드(Claude)의 내부…

오픈AI “사람보다 AI와 대화가 편하다는 ‘파워 유저’들… 정서 건강에 적신호”
Investigating Affective Use and Emotional Well-being on ChatGPT AI 챗봇 과도 사용자들, 정서적 의존 신호 보여 오픈AI와 MIT 미디어 랩이 공동으로 수행한 대규모 연구에…

트라우마 얘기하면 ‘챗GPT’도 스트레스 받는다… 불안 수치 100% 급증 현상 발견
Assessing and alleviating state anxiety in large language models 감정 프롬프트가 LLM 불안 100% 증가시키는 현상 발견 대형 언어 모델(Large Language Models, LLMs)이 정신…

예술용 AI는 편향되고, 기본 모델은 개선된다… 103개 모델 2년간 분석 결과 공개
EXPLORING BIAS IN OVER 100 TEXT-TO-IMAGE GENERATIVE MODELS 시간이 흐를수록 개선되는 기초 모델, 더 편향되는 예술 모델 텍스트-투-이미지(Text-to-Image, T2I) 생성 모델은 고품질 이미지를 합성할…

AI도 ‘생각’을 감추려 한다… 오픈AI, 위험한 AI 행동 95% 감지 가능한 기술 공개
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation 강력한 AI 모델의 ‘생각 과정’ 모니터링, 95% 정확도로 AI 오용 감지 최근 OpenAI…


