AI Report 언어 모델 연구
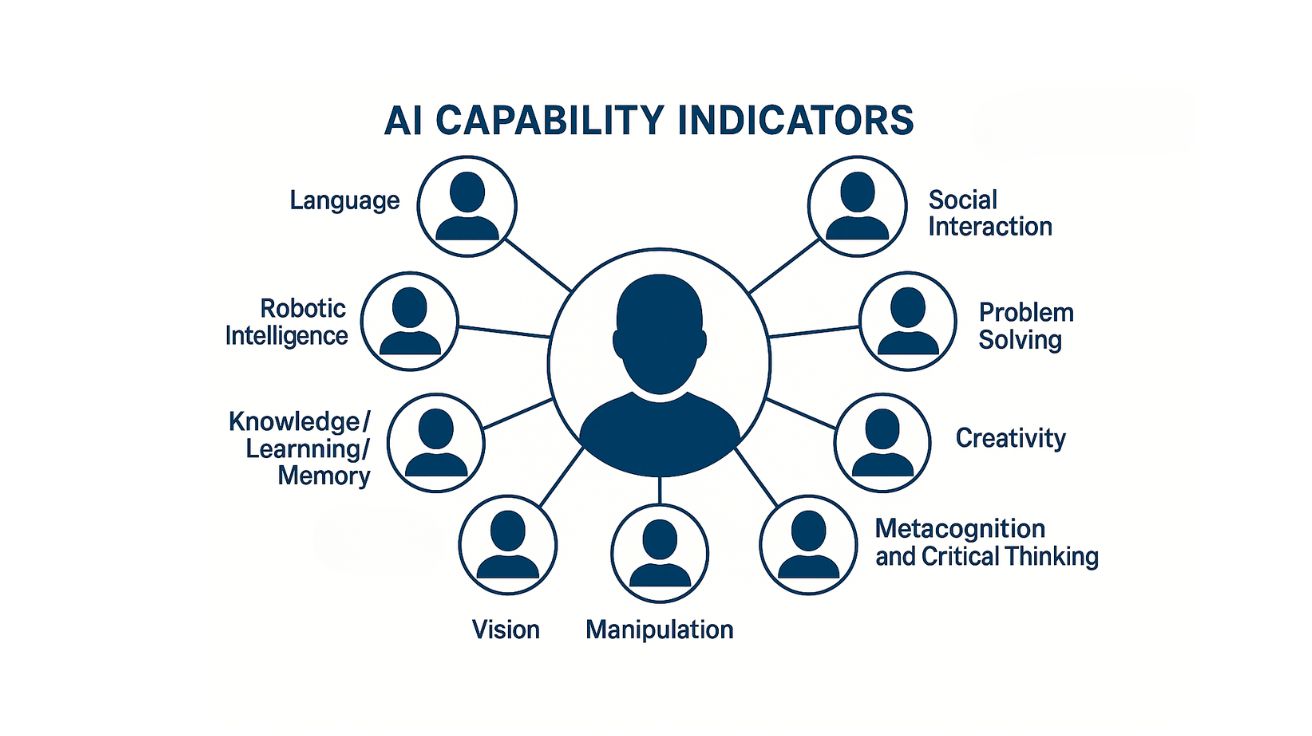
OECD가 제시한 AI 능력 측정 새 기준, 정책 결정을 위한 종합 프레임워크 공개
Introducing the OECD AI Capability Indicators 5년 연구 끝에 탄생한 AI 능력 평가의 글로벌 표준 경제협력개발기구(OECD)가 인공지능(AI) 능력을 체계적으로 측정할 수 있는 종합 프레임워크를…

알리바바, 12만 토큰 고맥락 거대 문서도 척척 이해하는 AI ‘큐원롱-L1’ 공개… “오픈AI o3-mini 성능 뛰어넘어”
QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning 기존 AI 모델들이 긴 문서에서 겪던 학습 효율성 저하와 불안정성 문제 알리바바 통이랩(Tongyi Lab)이 강화학습을…

메타, 기존 통념 뒤집는 연구 결과 공개… “추론 시간 짧으면 LLM 정확도 34.5% 향상”
Don’t Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning 기존 통념을 뒤집는 발견: 짧은 추론이 34.5% 더 정확 복잡한 수학 문제를 해결하는…

“정답 몰라도 괜찮다”… AI 강화학습의 상식을 뒤엎은 워싱턴대 연구
Spurious Rewards: Rethinking Training Signals in RLVR 무작위 보상만으로 21.4% 성능 향상, 틀린 답 보상해도 24.6% 상승 강화학습 분야에서 놀라운 연구 결과가 발표됐다. 워싱턴대학교와…

AI 에이전트 24개 모아 놨더니 신기한 일이… “AI끼리 대화하면서 ‘암묵적 룰’ 만들어”
Emergent social conventions and collective bias in LLM populations 4가지 AI 모델, 15라운드 만에 전체 집단이 하나의 관습에 합의 대화형 AI 에이전트 집단이 명시적인…

로봇에게 “왼쪽 물건 가져와”라고 하면 정말 이해할까? 로봇의 공간 인지 기술
Towards Embodied Cognition in Robots via Spatially Grounded Synthetic Worlds “왼쪽 물건 가져와” 명령을 이해하는 로봇의 핵심 기술, VPT란? 이탈리아 기술연구소(Italian Institute of Technology)와…
‘번뜩’ 하는 순간에 의존하던 AI, 드디어 체계적으로 생각하는 법을 배웠다! 수학·코딩 성능 10% 급상승의 비밀
Beyond ‘Aha!’: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models 오픈AI o1·딥시크 R1도 겪는 ‘아하!’ 순간의 예측 불가능성 문제 세일즈 포스 AI 연구소 및…

“AI가 그린 정의의 저울은 한쪽으로 기울었다” 달리-3의 윤리 편향 실험
Kaleidoscope Gallery: Exploring Ethics and Generative AI Through Art 덕 윤리는 남성 전용? DALL-E 3가 드러낸 성별·지역 편향 생성형 AI가 복잡한 철학적 개념을 어떻게…
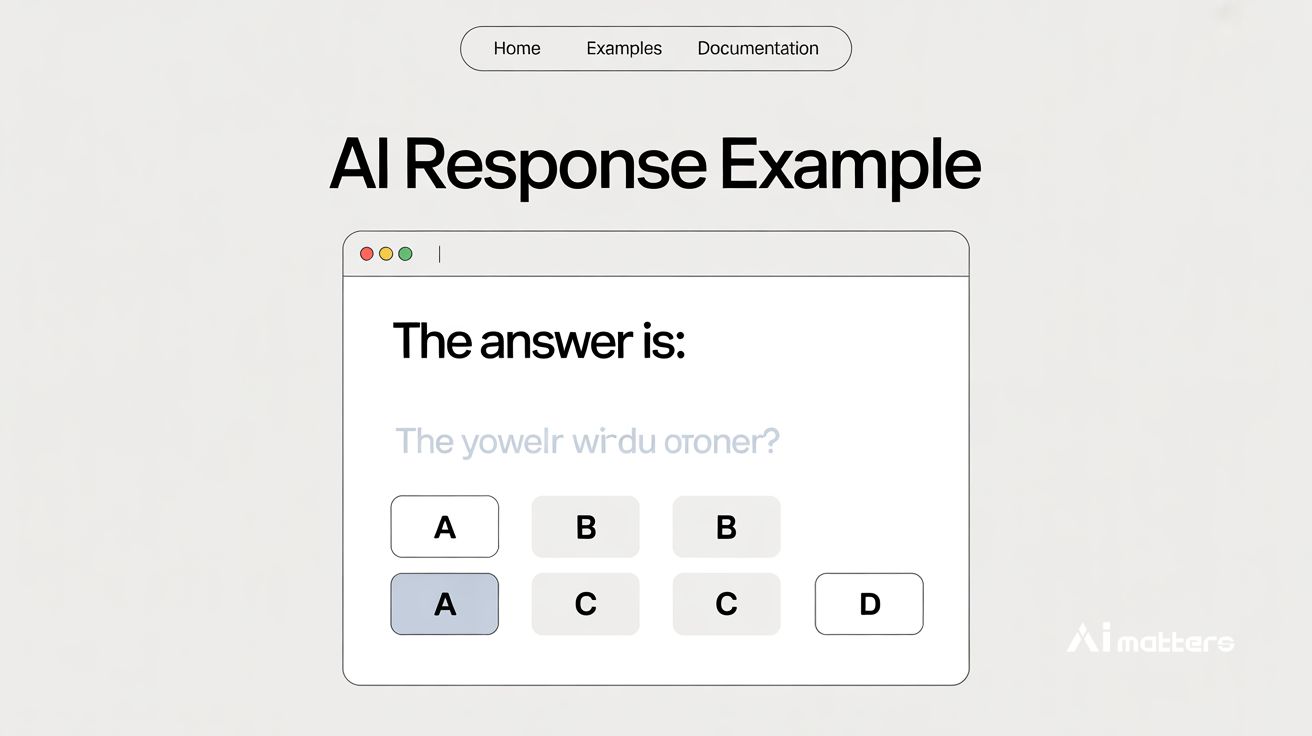
“한 문장만 추가했는데 정답률이 40% 올랐다?” AI 모델의 객관식 문제 정답률 높이는 간단한 방법 발견
Improving LLM First-Token Predictions in Multiple-Choice Question Answering via Prefilling Attack 구글 AI가 34%→72% 성능 급상승한 비밀, ‘프리필링’ 기법의 정체 이탈리아와 미국 대학 및…

“챗GPT도 속는다” AI가 정확한 정보를 줘도 14% 확률로 거짓말하는 이유
Sufficient Context: A New Lens on Retrieval Augmented Generation Systems 표준 데이터셋의 55.4%가 불완전한 정보: ‘충분한 맥락’ 개념으로 드러난 AI 한계 검색 증강 생성(RAG)…

챗GPT는 왜 내 편만 들까? 스탠포드 연구진이 밝힌 충격적 진실
Social Sycophancy: A Broader Understanding of LLM Sycophancy AI 모델들이 사용자에게 과도한 동조를 보이는 ‘사회적 아첨행동’ 발견 스탠포드 대학교 연구팀이 개발한 연구에 따르면, 대형언어모델(LLM)들이…

국방·재난 AI가 실패하는 이유, 데이터 훈련 방식의 근본적 문제점은?
The Achilles’ Heel of AI: Fundamentals of Risk-Aware Training Datafor High-Consequence Models 방어·재난대응 AI 모델, 기존 데이터 라벨링 방식으론 한계 드러나 전통적인 AI 훈련…
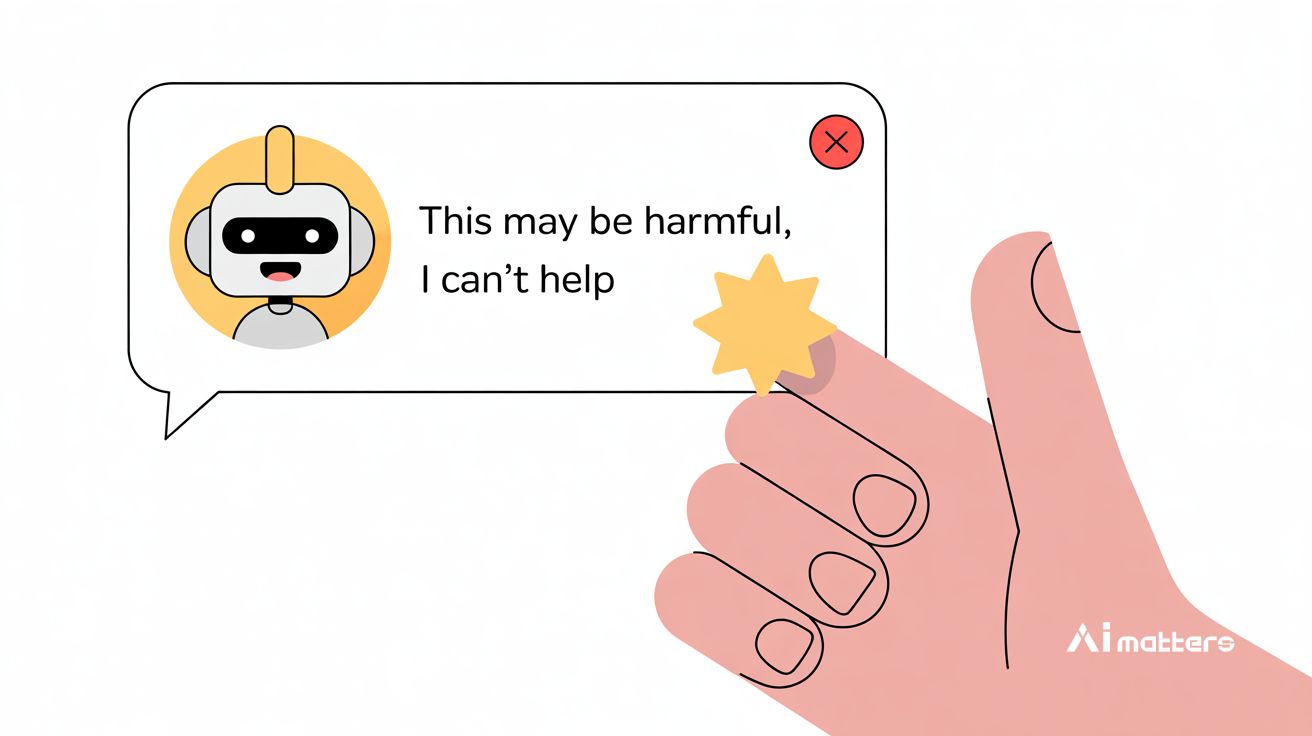
AI가 AI를 평가하면 생기는 일? ‘도움 드릴 수 없습니다’ 답변을 32% 더 좋아해
AI vs. Human Judgment of Content Moderation:LLM-as-a-Judge and Ethics-Based Response Refusals GPT-4o와 라마 모델, 윤리적 거부 응답에 32%포인트 높은 점수 대규모 언어 모델(LLM)이 다른…

“알렉사, 나를 잊어줘” 음성 AI가 개인정보를 선택적으로 삭제하는 기술 등장
“Alexa, can you forget me?” Machine Unlearning Benchmark in Spoken Language Understanding 음성 데이터 삭제가 시급한 이유: 개인 식별 정보 노출 위험성 음성 인공지능이…

“AI가 생화학 무기 제조 도울 수도” 앤트로픽, 클로드 오퍼스 4에 사상 최고 보안 적용
Activating AI Safety Level 3 Protections 범용 탈옥 공격 차단을 위한 실시간 분류기 가드 시스템 도입 앤트로픽(Anthropic)이 AI 안전성 레벨 3(ASL-3) 보안 표준을 적용한…
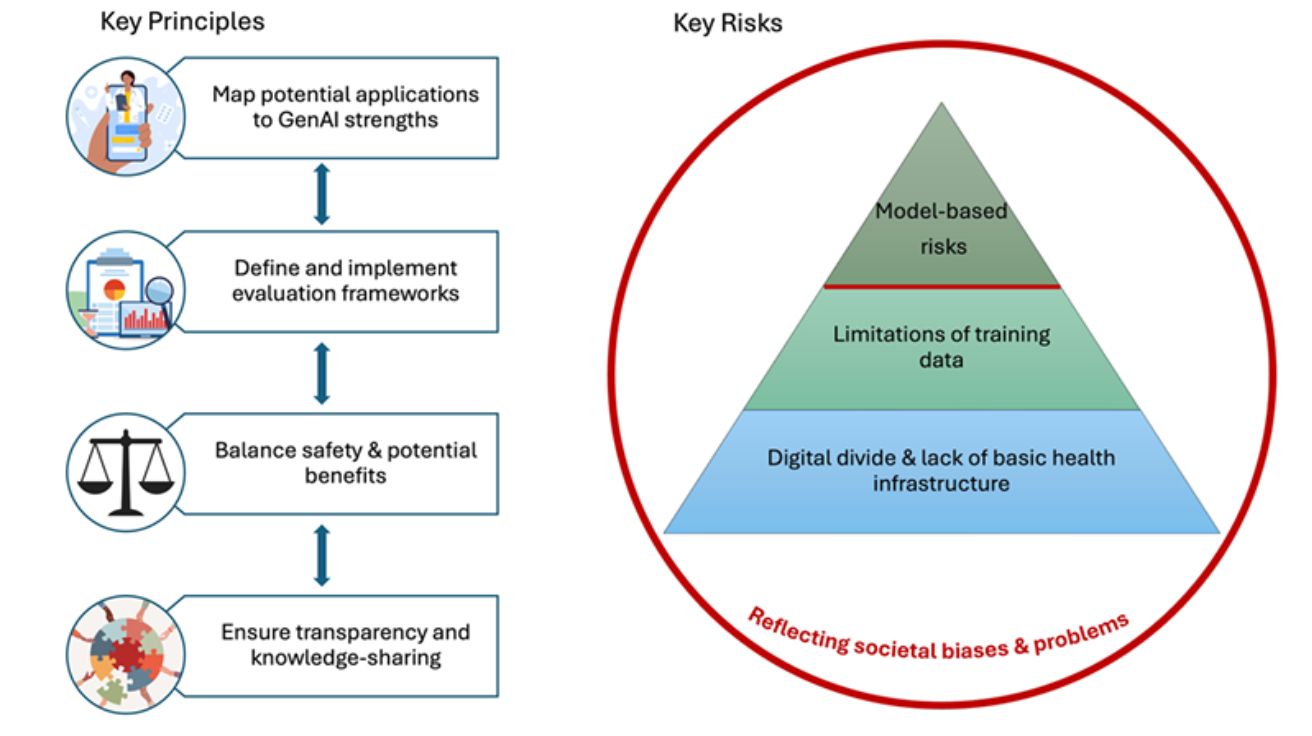
스탠포드 의료AI·디지털헬스 전문가 54명이 밝힌 의료용 AI의 치명적 위험과 해결책
A framework for considering the use of generative AI for health 스탠포드 대학 54명 전문가가 제시한 의료용 AI 안전 가이드 스탠포드 대학교(Stanford University) 디지털헬스센터…
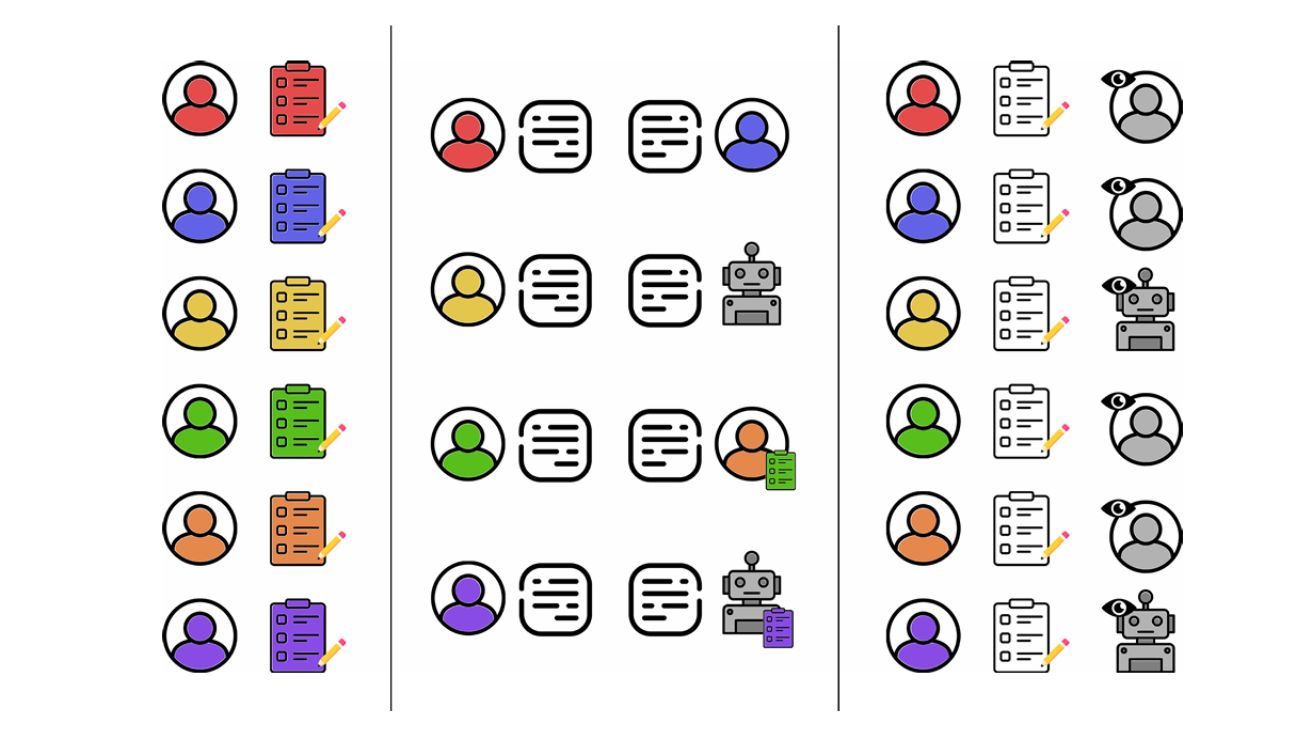
챗GPT, 개인 정보만 있으면 ‘설득의 달인’… “인간보다 81% 더 설득력 있어”
On the conversational persuasiveness of GPT-4 개인화된 GPT-4, 인간보다 81.2% 더 높은 설득력으로 대화 승리 대규모 언어 모델(LLM)이 설득력 있는 콘텐츠를 생성할 수 있다는…
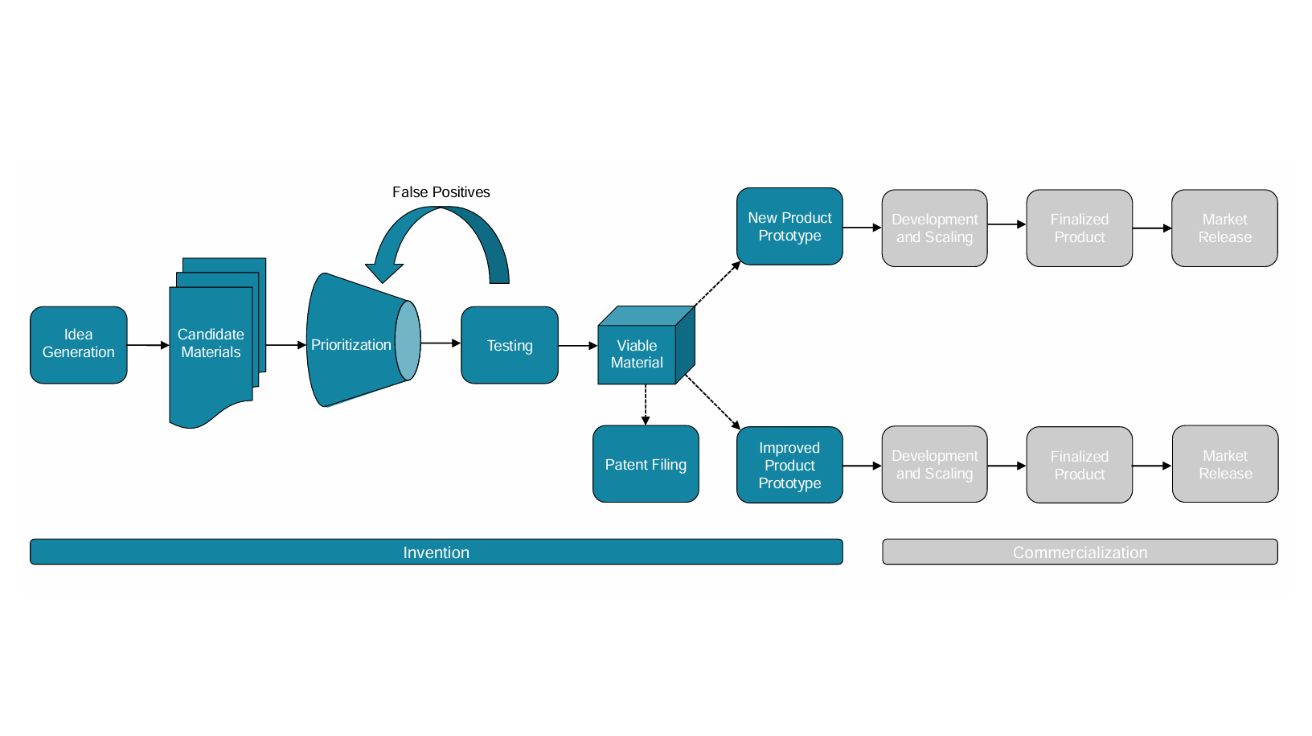
AI와 과학자의 공생 관계? 신소재 발견 44%, 특허 출원 39% 증가했지만, 직무 만족도 44% 감소
Artificial Intelligence, Scientific Discovery, and Product Innovation AI, 44% 더 많은 신소재 발견으로 과학 연구에 혁명 가져와 인공지능이 과학적 발견 영역에서 혁명적 변화를 가져오고…

7개월마다 2배씩 성장하는 AI? 전문가는 낙관적, 일반인은 우려하는 에이전트 시대
SPRi AI Brief 2025년 5월호 MCP vs A2A: 글로벌 기업들의 AI 에이전트 프로토콜 표준화 경쟁 점화 글로벌 AI 기업들이 AI 에이전트 기술 경쟁에 본격적으로…

“AI로 숙제하는 Z세대” 청소년 77%가 AI로 숙제한다는 설문조사 결과 공개
Generative AI in schools: 77% of teens say they are using AI for homework – why teachers are concerned 94%가 AI 경험, 20%는 ‘정기적…

AI도 ‘스스로’ 선택할 수 있다… 마인크래프트와 드론이 보여준 AI의 자유의지
Artificial intelligence and free will: generative agents utilizing large language models have functional free will 인간 수준에 도달한 AI 인지 능력: GPT-4는 의학 조언에서…

당신의 직업은 AI에 의해 사라질까? 노동 시장 영향력 연구 결과 보고서
Displacement or Augmentation? The Effects of AI Innovation on Workforce Dynamics and Firm Value AI 기능별 노동력 영향 차이: 증강형 vs 대체형 (500만 건…

“AI와 일하면 성과는 높아지지만 ‘흥미’는 떨어진다”… 3,500명 실험 결과 충격적
Human-generative AI collaboration enhances task performance but undermines human’s intrinsic motivation 생성형 AI와의 협업, 텍스트 길이 최대 150% 증가하고 품질도 향상 인간과 생성형 AI(GenAI)의…

AI도 ‘분업’이 효율적… 화웨이가 만든 ‘여러 전문가 AI’ 성능 58% 향상
PANGU ULTRA MOE: HOW TO TRAIN YOUR BIG MOE ON ASCEND NPUS 효율성 2배 향상, 화웨이의 7천억 파라미터 MoE 모델 어센드 NPU 최적화 도전기…

“책장 만들어줘” 한마디면 OK… 실제 조립 가능한 레고 설계하는 AI
Generating Physically Stable and Buildable LEGO Designs from Text 문장만 입력하면 물리적으로 안정적인 레고 구조물이 완성된다 카네기멜런대학교(Carnegie Mellon University)의 연구진은 텍스트 입력만으로 물리적으로 안정적인…

AI에게 자판기 운영 시켜봤더니… 클로드 3.5 소넷, 인간보다 185만원 더 벌어
Vending-Bench: A Benchmark for Long-Term Coherence of Autonomous Agents3 2천만 토큰 넘는 장기 실험, AI 에이전트의 일관성 측정하는 ‘벤딩-벤치’ 개발 대형 언어 모델(LLM)은 짧은…
AI에게 ‘간략히 설명해줘’라고 말하면 오답률 20% 증가… 충격적 연구 결과
Good answers are not necessarily factual answers: an analysis of hallucination in leading LLMs 배포된 AI 애플리케이션 사고의 3분의 1이 환각 현상 때문… 전문가들…
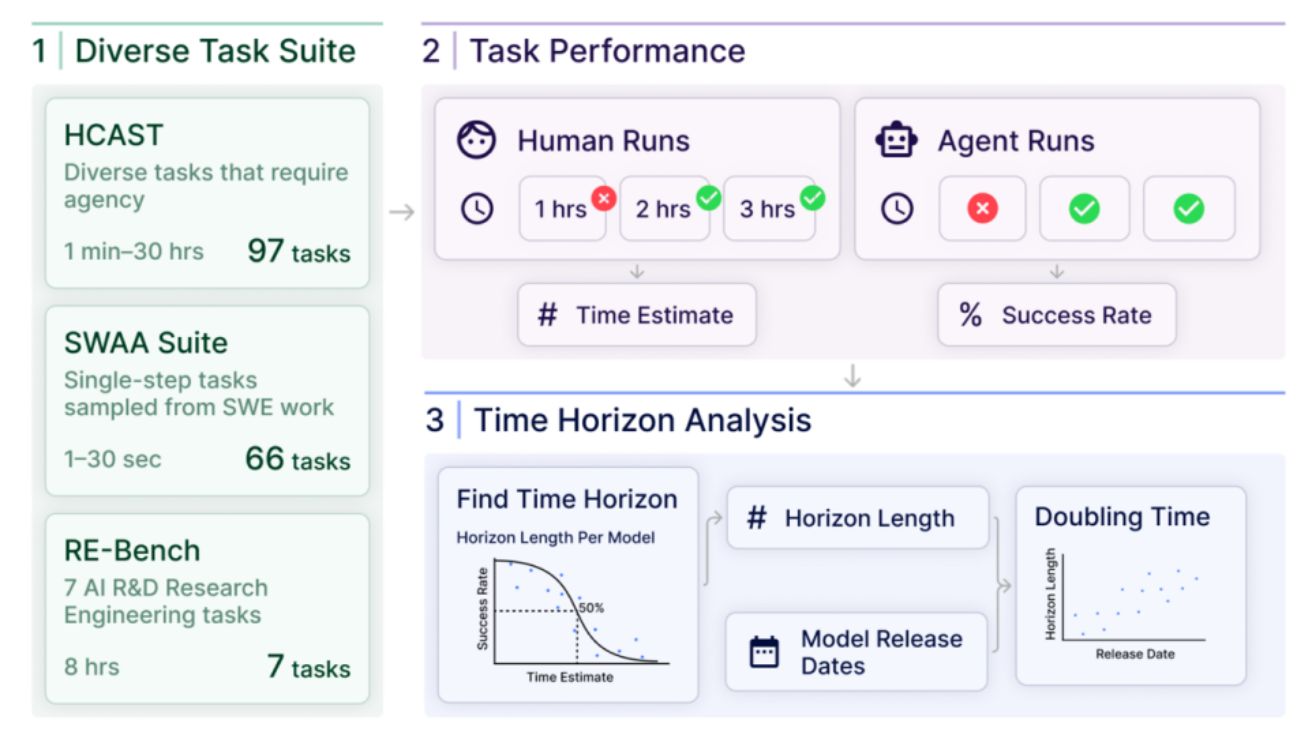
인간은 12시간 뒤에도 작업 성공률 20%, AI는 6%… 장시간 작업에서 드러난 AI의 치명적 약점
Is there a half-life for the success rates of AI agents? 7개월마다 AI 작업 능력 2배 증가…옥스포드 연구팀이 발견한 수학적 모델 연구기관 메트(METR)의 과학자들이…
당신의 우울함을 AI가 알아차릴까? 스탠포드 연구팀이 밝힌 정신건강 AI의 실체
Risks from Language Models for Automated Mental Healthcare: Ethics and Structure for Implementation 미국 정신과 의사 20% 미만만 신규 환자 수용, AI가 의료 공백…

AI 에이전트, 가짜 뉴스 대응의 새 무기 될 수 있나?
Assessing the Potential of Generative Agents in Crowdsourced Fact-Checking 오늘날 소셜미디어를 통해 허위정보가 빠르게 확산되는 상황에서 효과적인 팩트체킹 방법은 그 어느 때보다 중요해졌다. 최근…


