강화학습
“AI, 이제 인간 지식을 넘는다”… 전문가들이 극찬한 ‘경험의…
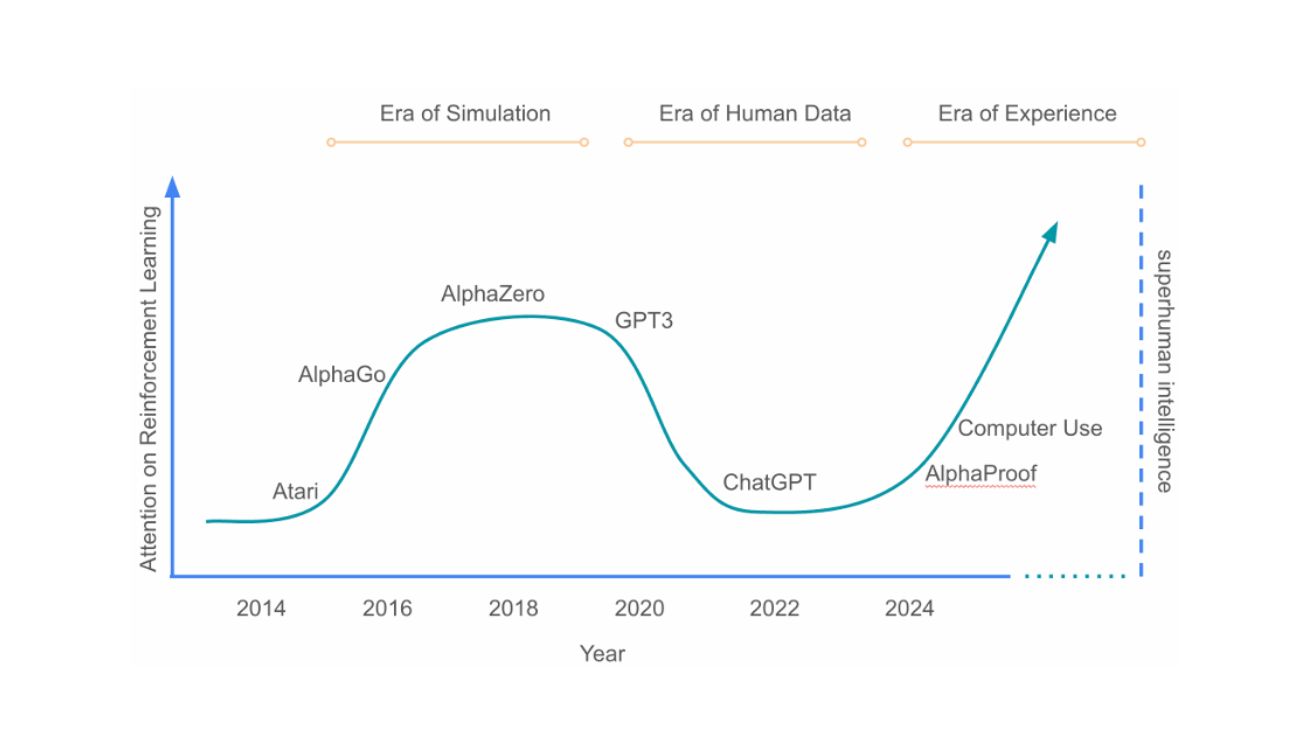
Welcome to the Era of Experience 인간 데이터의 한계? 고품질 데이터 소스 고갈로 AI 발전 둔화 인공지능(AI) 기술은…

“더 큰 AI보다 더 오래 생각하는 AI가 이긴다”…
Inference-Time Scaling for Generalist Reward Modeling 27배 더 작은 AI가 더 많이 ‘생각’하면 대형 모델을 이긴다: 추론 시간…
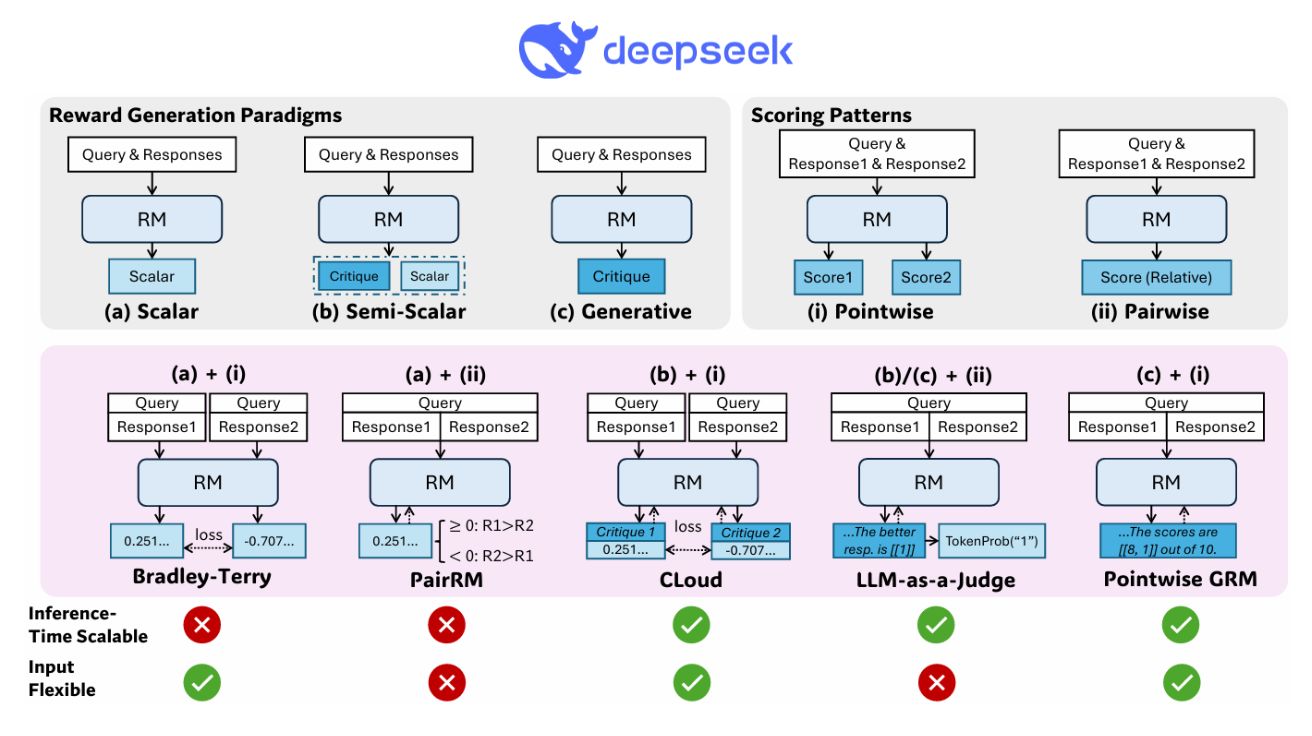
딥시크, AI 대화의 정확도를 32배 샘플링으로 끌어올리는 ‘보상…
Inference-Time Scaling for Generalist Reward Modeling 대규모 언어 모델의 성능 향상을 위한 보상 모델링 강화학습 기술은 대규모 언어…

클로드·딥시크도 속마음 안 털어놓는다? 흥미로운 앤트로픽 연구 결과
Reasoning Models Don’t Always Say What They Think 생각의 80%를 숨기는 AI: 추론 모델의 사고과정 충실도 20% 미만으로…

AI가 거짓말을 배우면? 강화학습으로 무장한 생성형 AI가 팀…
Learning to Lie: Reinforcement Learning Attacks Damage Human-AI Teams and Teams of LLMs 신뢰를 조작하는 적대적 AI: 팀…

피규어, 인간처럼 자연스럽게 걷는 휴머노이드 로봇 영상 공개
휴머노이드 로봇 전문기업 피규어(Figure)가 강화학습(Reinforcement Learning, RL)을 활용해 인간과 같은 자연스러운 보행이 가능한 로봇 개발에 성공했다. 25일(현지 시간)…

中 자전거 타는 로봇 영상 화제… “가르쳐주지 않아도…
글로벌타임즈가 11일(현지 시간) 보도한 내용에 따르면, 상하이의 휴머노이드 로봇 제조업체 애지봇(AgiBot)이 자전거 타기와 호버보드에서 균형 잡기 같은 인간에…

알리바바, 추론 모델 QwQ-32B 모델 공개… 20배 작은…
강화학습(RL)을 대규모로 적용하면 기존의 사전 훈련 및 후속 훈련 방법을 넘어서는 모델 성능을 실현할 수 있다. 퀜(Qwen) 팀이…

AI가 금연 도우미? 가상 코치가 개인별 맞춤 전략으로…
Psychology-Informed Reinforcement Learning for Situated Virtual Coaching in Smoking Cessation 사용자 맞춤형 금연 중재를 위한 가상 코치 연구의…

추론 모델 훈련에 일반 데이터 10만개보다 고급 데이터…
LIMO: Less is More for Reasoning 817개 학습 데이터로 AIME 57.1% 정확도 달성한 LIMO의 혁신 상하이교통대학교(SJTU) 연구진이 발표한…