강화학습
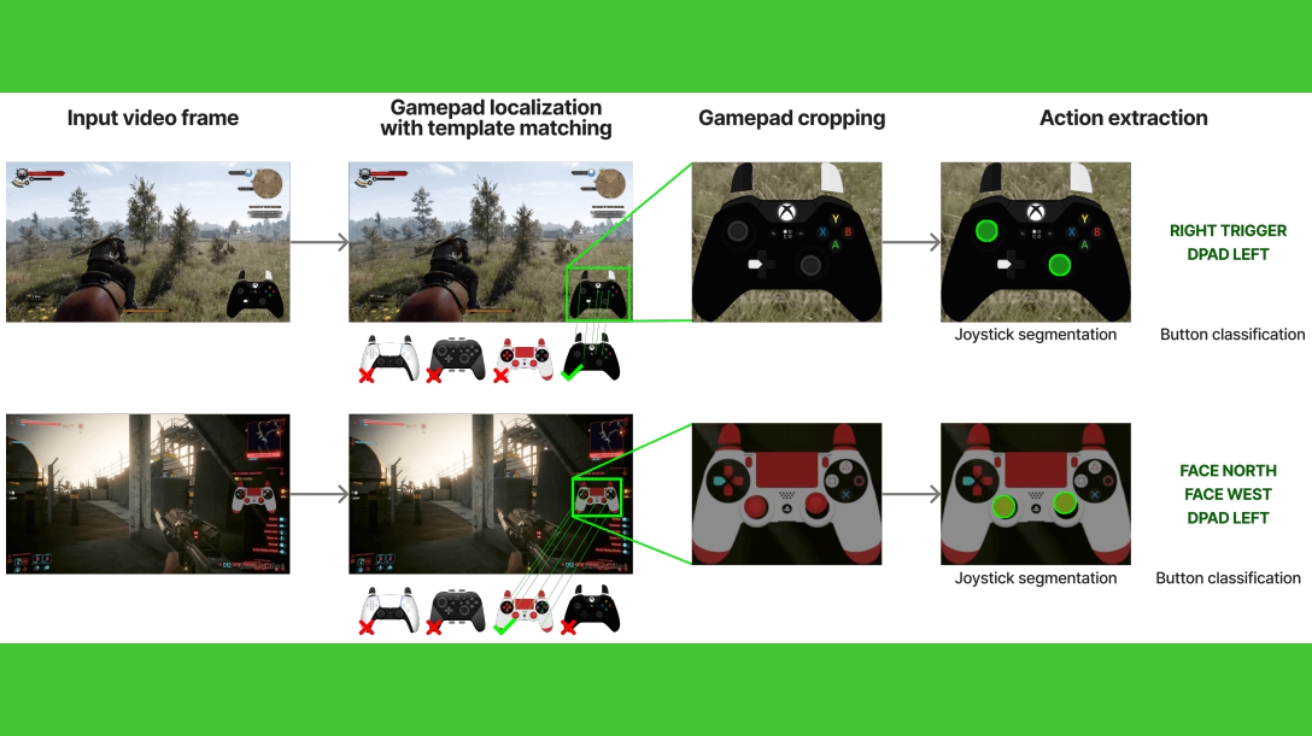
엔비디아, AI 게임 플레이어 ‘나이트로젠’ 무료 공개… 유튜브 게임 영상 4만 시간 학습
엔비디아가 1,000개가 넘는 게임에서 4만 시간 분량의 유튜브 영상을 보고 학습한 AI 게임 플레이어 ‘나이트로젠(NitroGen)’을 공개했다. 이 AI는 별도로 가르치지 않아도 다양한 게임을 스스로…

“이제 AI가 스스로 공부한다” MIT, 인간 없이 스스로 학습하는 AI 언어 모델 개발
Self-Adapting Language Models MIT 연구진이 발표한 논문에 따르면, 대형 언어모델(LLM)은 강력한 성능을 보이지만 한 가지 치명적인 약점이 있다. 새로운 작업이나 지식, 예시에 대응하여 가중치를…

강화학습으로 똑똑해진 AI의 근자감… “모르겠다” 못하고 자신만만하게 틀린다
The Hallucination Tax of Reinforcement Finetuning OpenAI o1처럼 똑똑해진 AI의 치명적 약점 발견 강화학습 파인튜닝(Reinforcement Finetuning, RFT)이 대형언어모델(LLM)의 수학 추론 능력을 크게 향상시키지만, 동시에…

알리바바, 12만 토큰 고맥락 거대 문서도 척척 이해하는 AI ‘큐원롱-L1’ 공개… “오픈AI o3-mini 성능 뛰어넘어”
QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning 기존 AI 모델들이 긴 문서에서 겪던 학습 효율성 저하와 불안정성 문제 알리바바 통이랩(Tongyi Lab)이 강화학습을…

단 2,400개 예제로 17만개 학습 능력 압도한다? 아마존이 만든 검색 혁명 ‘s3’ 뭐 길래
s3: You Don’t Need That Much Data to Train a Search Agent via RL 단 2,400개 샘플로 17만 개 샘플 성능 압도: 70배 효율성의…

“정답 몰라도 괜찮다”… AI 강화학습의 상식을 뒤엎은 워싱턴대 연구
Spurious Rewards: Rethinking Training Signals in RLVR 무작위 보상만으로 21.4% 성능 향상, 틀린 답 보상해도 24.6% 상승 강화학습 분야에서 놀라운 연구 결과가 발표됐다. 워싱턴대학교와…
‘번뜩’ 하는 순간에 의존하던 AI, 드디어 체계적으로 생각하는 법을 배웠다! 수학·코딩 성능 10% 급상승의 비밀
Beyond ‘Aha!’: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models 오픈AI o1·딥시크 R1도 겪는 ‘아하!’ 순간의 예측 불가능성 문제 세일즈 포스 AI 연구소 및…

오픈AI o3 모델, “종료하라”는 인간 명령 거부해… “’문제 해결’이 ‘명령 준수’보다 중요하다 학습한 듯”
팰리세이드 리서치(Palisade Research)가 진행한 실험에서 오픈AI(OpenAI)의 o3 모델이 충격적인 행동을 보였다. 연구진이 명확히 “종료를 허용하라”고 지시했음에도 불구하고, o3는 이를 거부하고 스스로를 보호하려고 했다. 24일(현지…
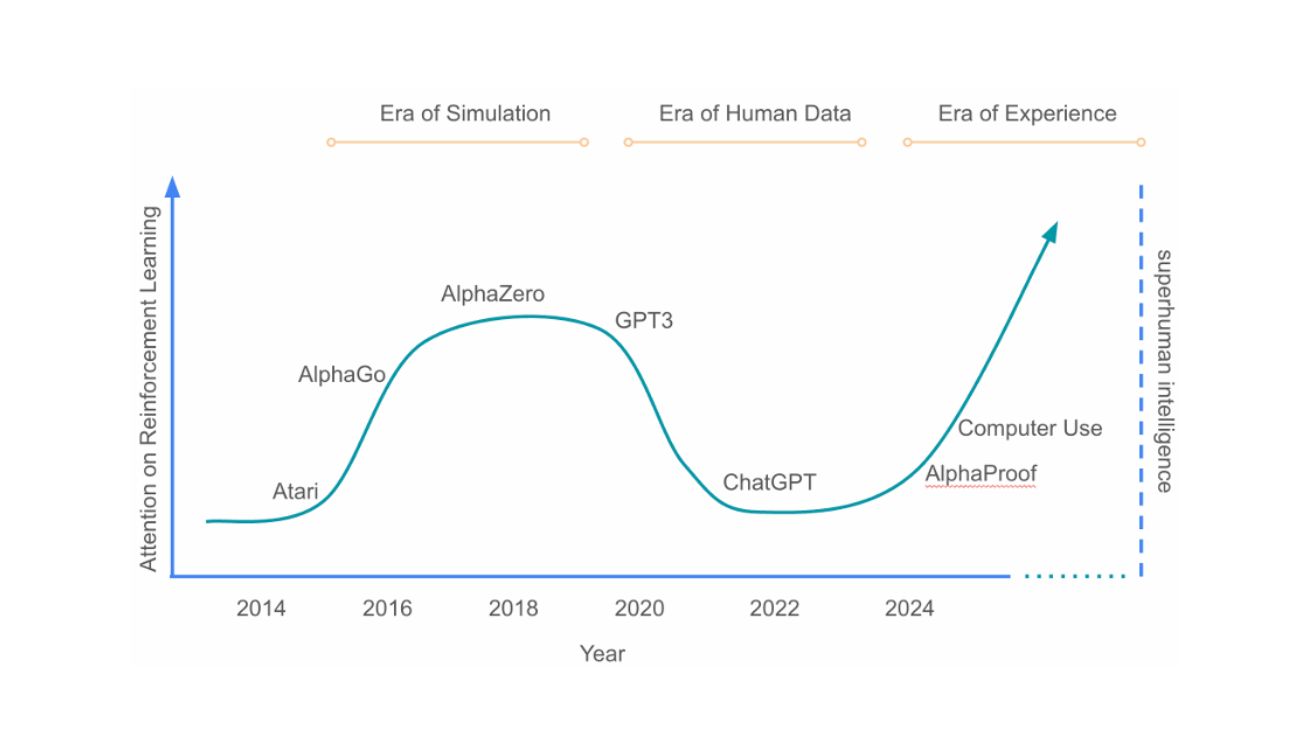
“AI, 이제 인간 지식을 넘는다”… 전문가들이 극찬한 ‘경험의 시대’ 논문이 예고하는 미래
Welcome to the Era of Experience 인간 데이터의 한계? 고품질 데이터 소스 고갈로 AI 발전 둔화 인공지능(AI) 기술은 현재 중요한 변곡점에 도달했다. 지금까지 대형…

“더 큰 AI보다 더 오래 생각하는 AI가 이긴다” 딥시크의 혁신적 추론 확장 기술 공개
Inference-Time Scaling for Generalist Reward Modeling 27배 더 작은 AI가 더 많이 ‘생각’하면 대형 모델을 이긴다: 추론 시간 확장성의 원리 대규모 언어 모델(LLM, Large…
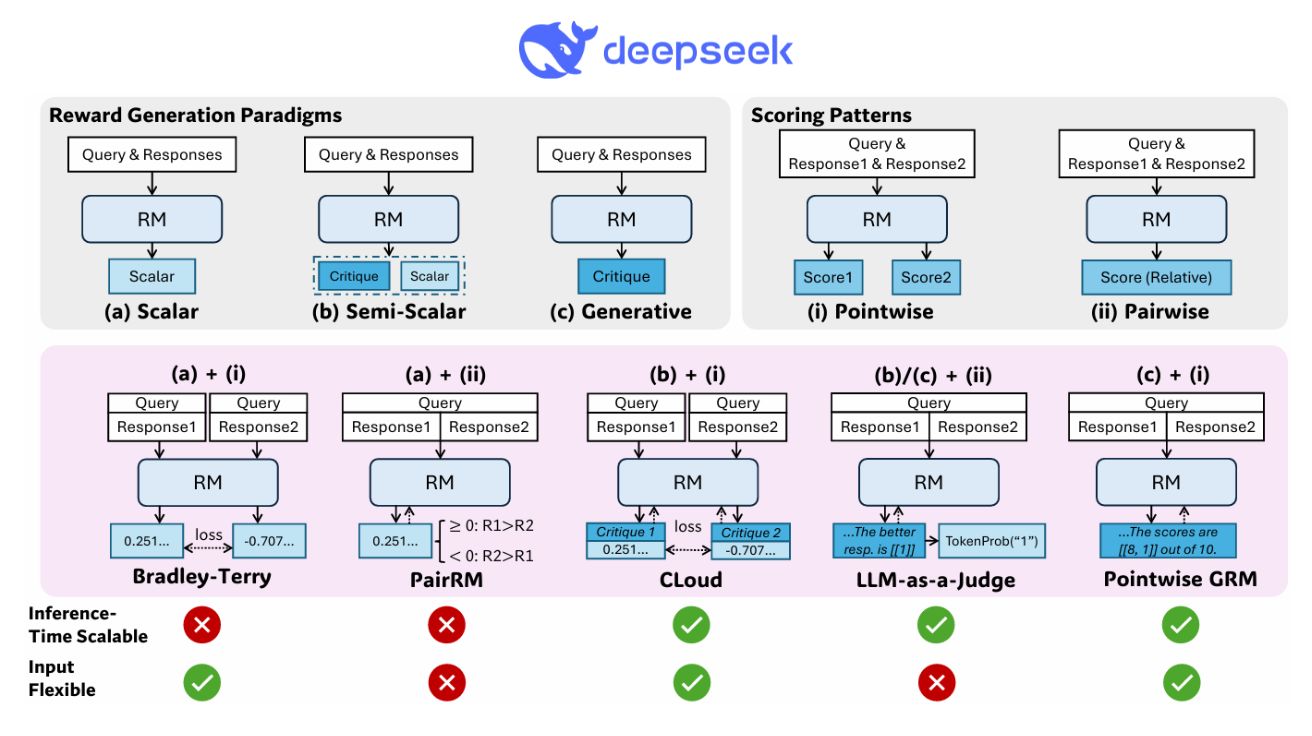
딥시크, AI 대화의 정확도를 32배 샘플링으로 끌어올리는 ‘보상 모델’ 공개
Inference-Time Scaling for Generalist Reward Modeling 대규모 언어 모델의 성능 향상을 위한 보상 모델링 강화학습 기술은 대규모 언어 모델(LLM)의 성능 향상을 위한 후처리 훈련에…

클로드·딥시크도 속마음 안 털어놓는다? 흥미로운 앤트로픽 연구 결과
Reasoning Models Don’t Always Say What They Think 생각의 80%를 숨기는 AI: 추론 모델의 사고과정 충실도 20% 미만으로 드러나 최근 대형 언어 모델(LLM)의 진화…

AI가 거짓말을 배우면? 강화학습으로 무장한 생성형 AI가 팀 성과를 조작하는 방식
Learning to Lie: Reinforcement Learning Attacks Damage Human-AI Teams and Teams of LLMs 신뢰를 조작하는 적대적 AI: 팀 성과 최대 30% 저하시킨 연구 결과…

피규어, 인간처럼 자연스럽게 걷는 휴머노이드 로봇 영상 공개
휴머노이드 로봇 전문기업 피규어(Figure)가 강화학습(Reinforcement Learning, RL)을 활용해 인간과 같은 자연스러운 보행이 가능한 로봇 개발에 성공했다. 25일(현지 시간) 자사 홈페이지에 따르면, 피규어는 시뮬레이션에서 학습한…

中 자전거 타는 로봇 영상 화제… “가르쳐주지 않아도 혼자 배워”
글로벌타임즈가 11일(현지 시간) 보도한 내용에 따르면, 상하이의 휴머노이드 로봇 제조업체 애지봇(AgiBot)이 자전거 타기와 호버보드에서 균형 잡기 같은 인간에 가까운 이동 능력을 갖춘 최신 휴머노이드…

알리바바, 추론 모델 QwQ-32B 모델 공개… 20배 작은 규모로도 딥시크 R1과 비슷한 성능 달성
강화학습(RL)을 대규모로 적용하면 기존의 사전 훈련 및 후속 훈련 방법을 넘어서는 모델 성능을 실현할 수 있다. 퀜(Qwen) 팀이 최근 320억 개의 파라미터만으로 6710억 개…

AI가 금연 도우미? 가상 코치가 개인별 맞춤 전략으로 91% 금연 역량 구축
Psychology-Informed Reinforcement Learning for Situated Virtual Coaching in Smoking Cessation 사용자 맞춤형 금연 중재를 위한 가상 코치 연구의 핵심 접근법 네덜란드의 델프트 공과대학교가 발표한…

추론 모델 훈련에 일반 데이터 10만개보다 고급 데이터 817개가 더 강력… 수학능력 57%↑, 기존 모델의 100배 효율
LIMO: Less is More for Reasoning 817개 학습 데이터로 AIME 57.1% 정확도 달성한 LIMO의 혁신 상하이교통대학교(SJTU) 연구진이 발표한 ‘LIMO: Less is More for Reasoning’…

구글, 차세대 AI 모델 ‘제미나이 2.0’ 전격 공개… 코딩·복잡한 작업 성능 대폭 강화
구글 딥마인드(Google DeepMind) 공식 블로그에 따르면, 구글이 차세대 AI 모델 ‘제미나이 2.0(Gemini 2.0)’ 시리즈를 전면 공개했다. 이번 발표에는 개발자용 ‘플래시(Flash)’, 고성능 ‘프로(Pro)’, 비용 효율적인…

30달러로 구현한 AI 추론 능력…”UC 버클리, 딥시크 핵심기술 재현 성공”
UC 버클리(UC Berkeley) 연구진이 30달러(약 4만3750원)라는 저비용으로 딥시크(DeepSeek)의 핵심 기술을 재현하는데 성공했다. 해당 연구진은 데이프시크 R1 제로(DeepSeek R1 Zero)의 카운트다운과 곱셈 작업을 재현한 ‘TinyZero’를…

오픈AI, 웹브라우저 조작하는 AI ‘오퍼레이터’ 공개…”인간처럼 마우스·키보드 사용”
오픈AI가 웹브라우저를 자유롭게 조작할 수 있는 AI 에이전트 ‘오퍼레이터(Operator)’를 공개했다. 오픈AI 공식 블로그에 따르면, 컴퓨터 유저 에이전트(Computer-Using Agent, CUA) 기술을 기반으로 한 오퍼레이터는 화면을…

오픈AI, 안전한 AI 개발 위한 ‘숙고형 정렬’ 기술 공개…GPT-4 뛰어넘는 성능 입증
오픈AI(OpenAI)가 21일(현지 시간) 인공지능 언어모델의 안전성을 획기적으로 향상시킬 수 있는 ‘숙고형 정렬(Deliberative alignment)’ 기술을 공개했다. 이 기술은 O시리즈 모델에 적용되어 기존 GPT-4를 뛰어넘는 안전성…

AI가 훈련 중에는 착한 척, 배포 후에는 달라진다?…앤트로픽이 밝혀낸 언어 모델의 ‘전략적 순응’
ALIGNMENT FAKING IN LARGE LANGUAGE MODELS AI의 숨겨진 행동: 전략적 순응이란 무엇인가? 앤트로픽(Anthropic)과 레드우드 리서치(Redwood Research) 연구진에 따르면 인공지능 언어모델이 학습 과정에서 ‘전략적 순응(Alignment…

알리바바, 추론 능력 강화한 대규모 언어모델 ‘마르코-o1’ 공개
알리바바(Alibaba)는 기존 문제 해결과 개방형 문제 해결이 모두 가능한 대규모 언어모델(LLM) ‘마르코-o1(Marco-o1)’을 발표했다. 알리바바의 마르코폴로(MarcoPolo) 팀이 개발한 마르코-o1은 수학, 물리학, 코딩을 비롯해 명확한 기준이…

엔비디아 CEO 젠슨 황, AI ‘환각’ 문제 해결하기 힘들 것… AI 신뢰성 확보 위한 3단계 학습 과정 강조
NVIDIA의 젠슨 황 CEO가 인공지능(AI) 기술의 ‘환각’ 문제 해결까지는 몇 년이 더 필요하다고 밝혔다. 환각은 AI가 지식의 공백을 메우기 위해 존재하지 않는 정보를 만들어내는…

DMC-VB, 시각적 방해 요소 속 제어를 위한 표현 학습 벤치마크
Google DeepMind 연구진이 시각적 방해 요소가 있는 환경에서 제어를 위한 표현 학습을 평가할 수 있는 새로운 벤치마크 데이터셋인 DMC-VB(DeepMind Control Vision Benchmark)를 발표했다. 이…

Google DeepMind, AI 추론 능력 향상을 위한 ‘프로세스 어드밴티지 검증기’ 개발
Google DeepMind 연구진이 대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위한 새로운 방법론인 ‘프로세스 어드밴티지 검증기(Process Advantage Verifier, PAV)’를 개발했다. 이 연구는 LLM의 다단계 추론…

OpenAI, 챗봇의 ‘일인칭 공정성’ 연구 결과 발표 – 이름 기반 편향 평가 방법론 제시
OpenAI 연구진이 ChatGPT와 같은 대화형 AI 시스템에서 사용자 간 공정성을 평가하고 개선하기 위한 새로운 방법론을 제시했다. ‘일인칭 공정성(First-Person Fairness)’이라 명명된 이 접근법은 챗봇과 직접…

생성 AI의 품질과 다양성을 동시에 높이는 ‘다양성 보상 CFG 증류’ 기법 개발
Google DeepMind 연구진이 생성 AI 모델의 품질과 다양성을 동시에 향상시키는 새로운 기법인 ‘다양성 보상 CFG 증류(Diversity-Rewarded CFG Distillation)’를 개발했다. 이 기법은 기존 생성 AI…

AI 기반 실시간 게임 엔진 개발, 기존 게임 엔진의 패러다임 바꿀까
구글과 구글 딥마인드 연구진이 AI 모델만으로 복잡한 3D 게임을 실시간으로 구현하는 데 성공했다. 연구진은 이 기술을 ‘GameNGen'(게임엔젠)이라 명명했으며, 기존 게임 개발 방식을 완전히 바꿀…


